Beschleunigung der LLaMA-2-Inferenz mit ONNX Runtime
Von: Kunal Vaishnavi und Parinita Rahi
14. NOVEMBER 2023 (Aktualisiert am 22. November)
Interessiert daran, Llama2 schneller auszuführen? Lassen Sie uns untersuchen, wie ONNX Runtime Ihre Llama2-Varianten für schnellere Inferenz beschleunigen kann!
Sie können jetzt erhebliche Inferenzgewinne erzielen – bis zu 3,8-mal schneller – für die 7B-, 13B- und 70B-Modelle, dank modernster Fusions- und Kernel-Optimierungen mit ONNX Runtime. Dieser Blog beschreibt Leistungsverbesserungen, befasst sich mit ONNX Runtime Fusionsoptimierungen, unterstützt die Multi-GPU-Inferenz und führt Sie durch die Nutzung der plattformübergreifenden Leistungsfähigkeit von ONNX Runtime für nahtlose Inferenz über verschiedene Plattformen hinweg. Dies ist der erste Teil einer Reihe von bevorstehenden Blogs, die zusätzliche Aspekte für eine effiziente Speichernutzung mit ONNX Runtime Quantisierungsaktualisierungen und plattformübergreifende Nutzungsszenarien behandeln werden.
Hintergrund: Llama2 und Microsoft
Llama2 ist ein hochmodernes Open-Source-LLM von Meta, das in verschiedenen Größen von 7B bis 70B Parametern (7B, 13B, 70B) erhältlich ist. Microsoft und Meta haben im Juli 2023 ihre Zusammenarbeit im Bereich KI auf Azure und Windows angekündigt. Als Teil der Ankündigung wurde Llama2 dem Azure AI-Modellkatalog hinzugefügt, der als Zentrum für grundlegende Modelle dient und Entwicklern sowie Machine Learning (ML) -Profis ermöglicht, vorgefertigte große KI-Modelle einfach zu entdecken, zu bewerten, anzupassen und in großem Maßstab bereitzustellen.
ONNX Runtime ermöglicht es Benutzern, die Leistung dieses generativen KI-Modells einfach in ihre Apps und Dienste zu integrieren, mit verbesserten Optimierungen, die schnellere Inferenzgeschwindigkeiten erzielen und Ihre Kosten senken.
Schnellere Inferenz mit neuen ONNX Runtime-Optimierungen
Als Teil des neuen Releases 1.16.2 verfügt ONNX Runtime nun über mehrere integrierte Optimierungen für Llama2, darunter Graph-Fusionen und Kernel-Optimierungen. Die beschleunigte Inferenzgeschwindigkeit im Vergleich zu Hugging Face (HF)-Varianten von Llama2 im PyTorch-Kompilierungsmodus für die Prompt-Latenz von CUDA FP16 ist unten aufgeführt. Der End-to-End-Durchsatz oder die Wanduhr-Durchsatzzeit wird wie folgt definiert: Batch-Größe * (Prompt-Länge + Token-Generierungs-Länge) / Wanduhr-Latenz, wobei die Wanduhr-Latenz = die Latenz der End-to-End-Ausführung und die Token-Generierungs-Länge = 256 generierte Token ist. Der E2E-Durchsatz ist 2,4x höher (13B) und 1,8x höher (7B) im Vergleich zu PyTorch compile. Bei höheren Batch-Größen und Sequenzlängenpaaren wie (16, 2048) kommt PyTorch eager an seine Grenzen, während ORT eine bessere Leistung als im Kompilierungsmodus zeigt.
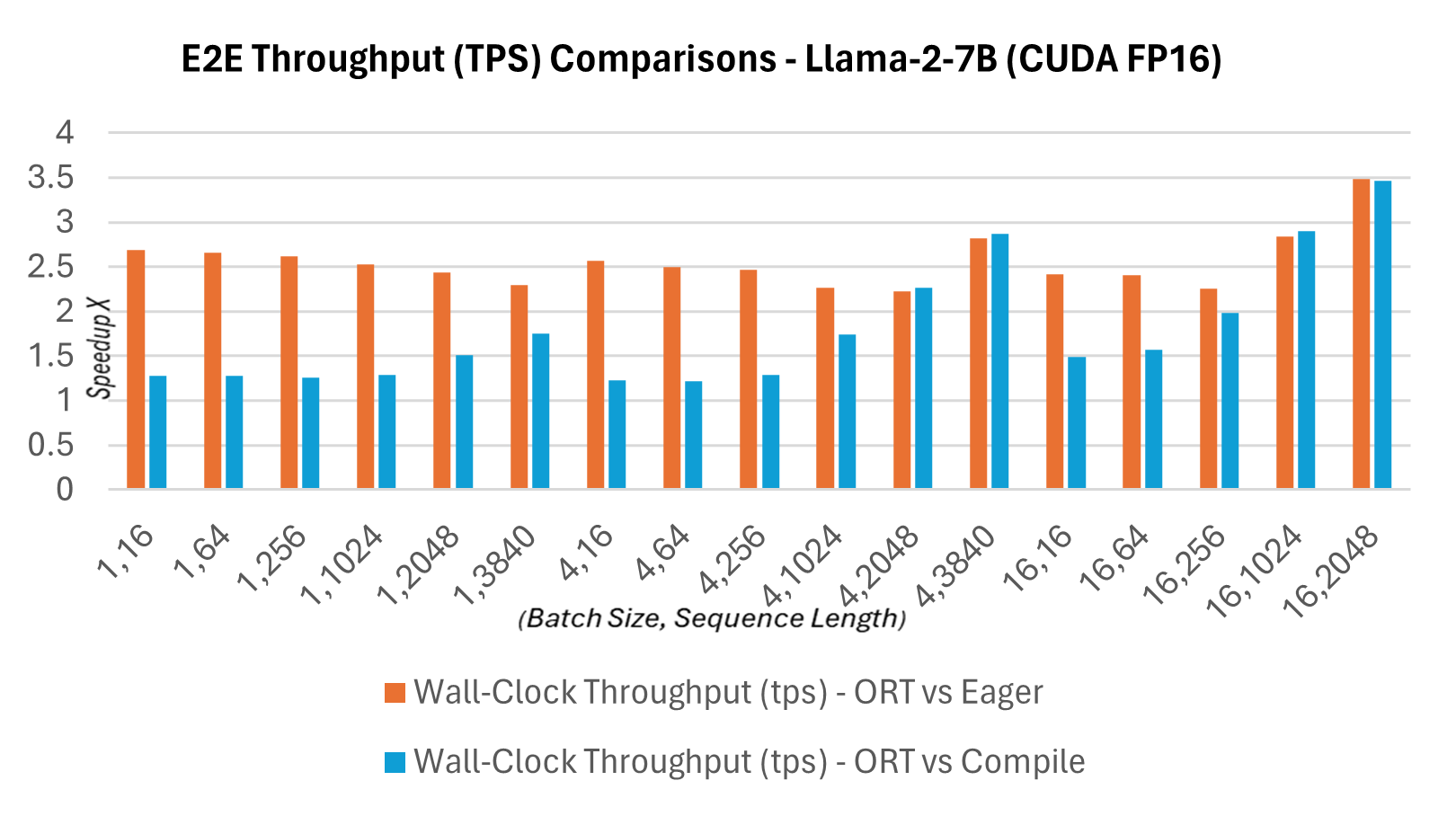

Latenz und Durchsatz
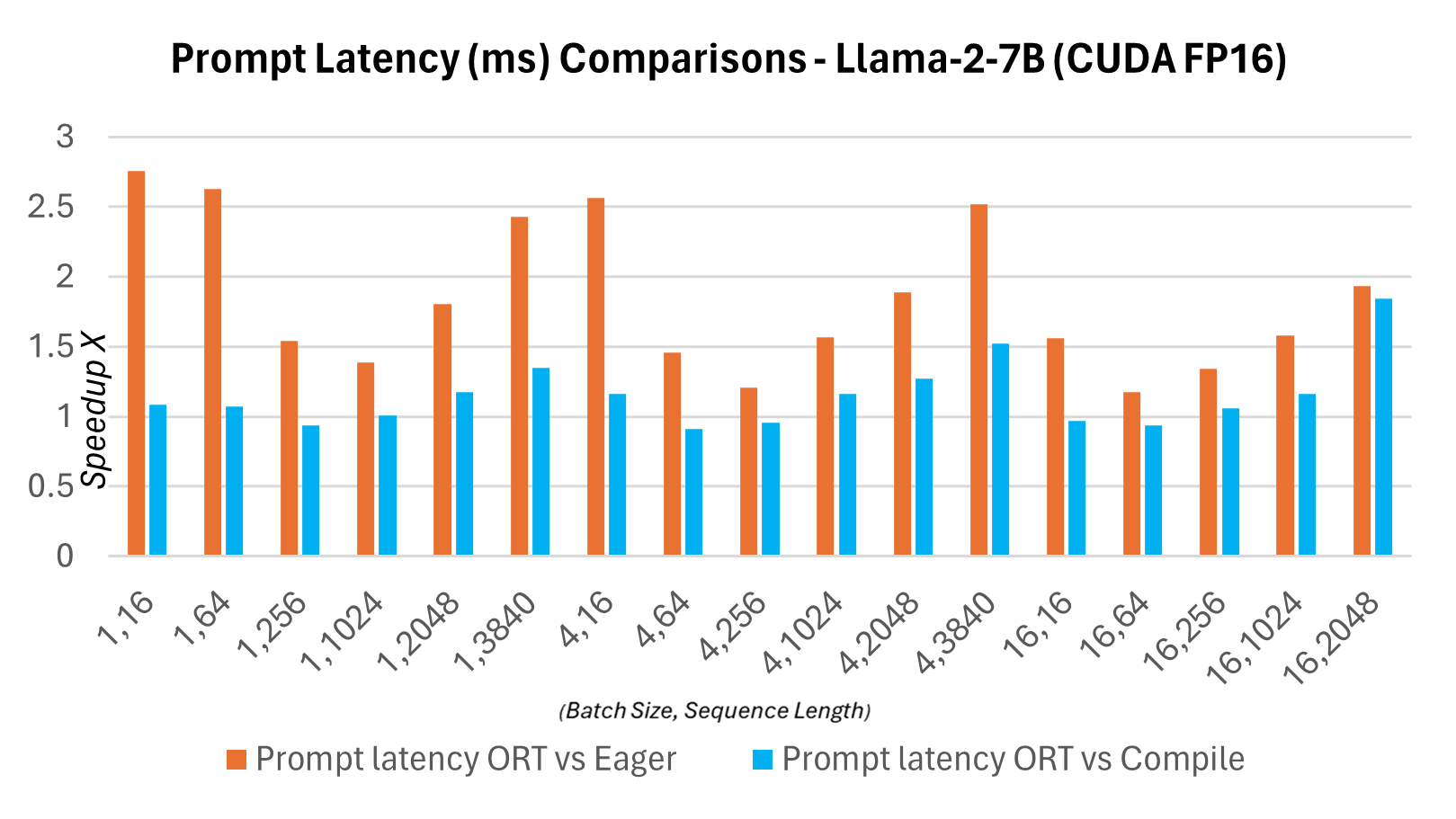
Die folgenden Graphen zeigen Latenzvergleiche zwischen den ONNX Runtime- und PyTorch-Varianten des Llama2 7B-Modells auf CUDA FP16. Die Latenz ist hier definiert als die Zeit, die benötigt wird, um einen Durchlauf durch das Modell abzuschließen, um die Logits zu erzeugen und die Ausgaben zu synchronisieren.

Der nachfolgende Durchsatz bei der Token-Generierung ist der durchschnittliche Durchsatz der ersten 256 generierten Token. Wir sehen Gewinne von bis zu ~1,3x (7B) und ~1,5x (13B) beim Token-Generierungs-Durchsatz im Vergleich zum PyTorch-Kompilierungsmodus.
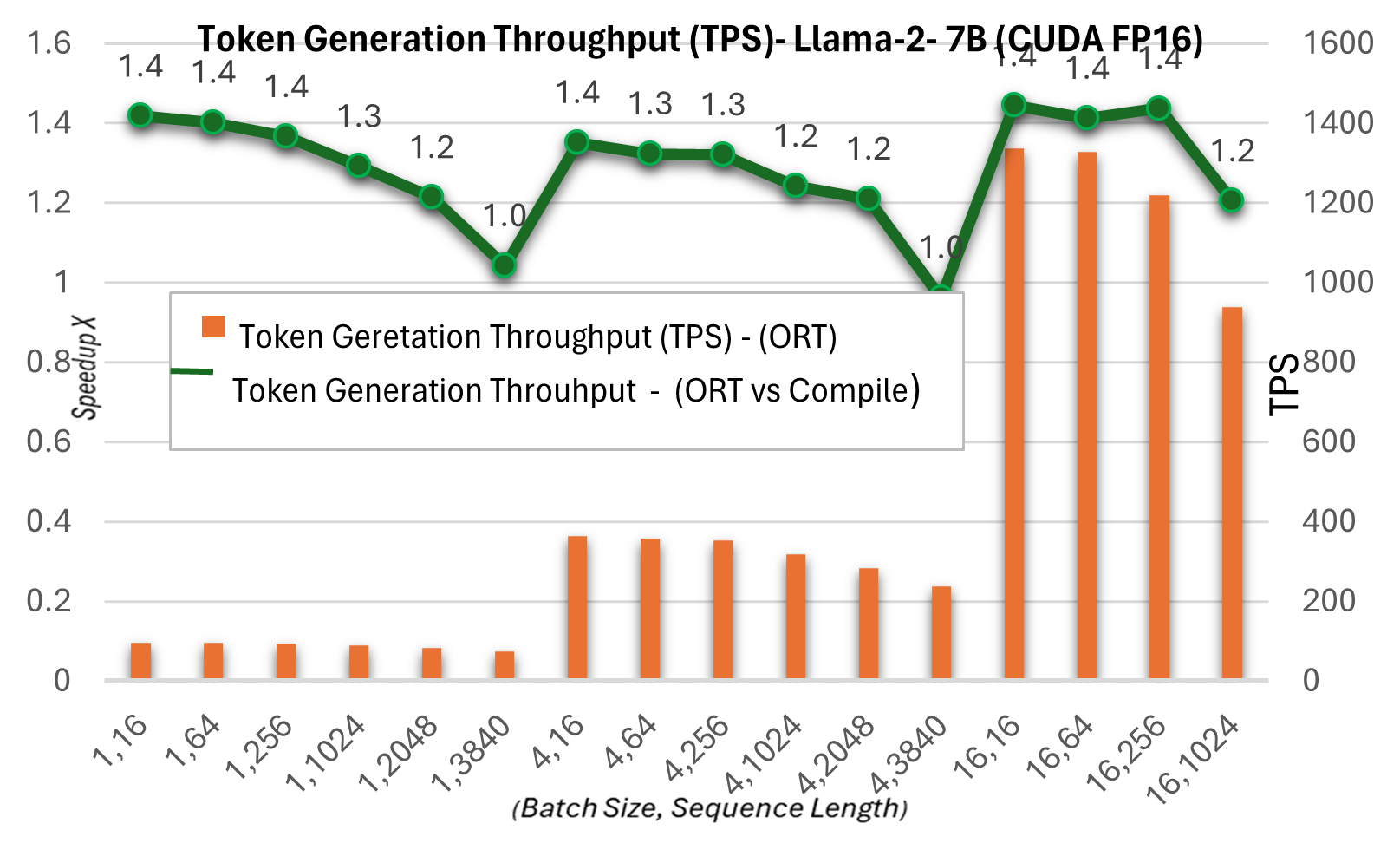
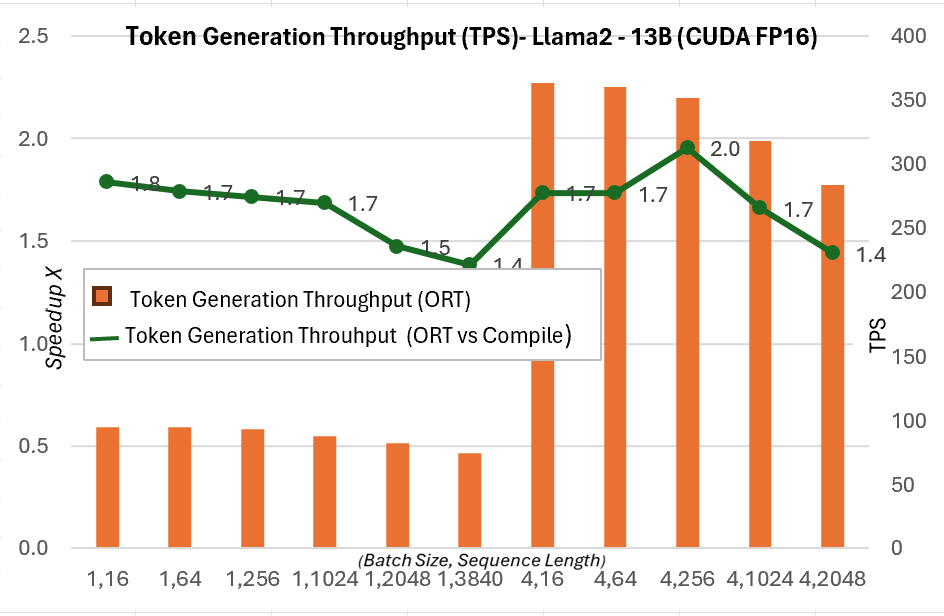
Weitere Details zu diesen Metriken finden Sie hier.
ONNX Runtime mit Multi-GPU-Inferenz
ONNX Runtime unterstützt Multi-GPU-Inferenz, um große Modelle bedienen zu können. Selbst in FP16-Präzision benötigt das LLaMA-2 70B-Modell 140 GB. Das Laden des Modells erfordert mehrere GPUs für die Inferenz, selbst mit einer leistungsstarken NVIDIA A100 80GB GPU.
ONNX Runtime wendet Megatron-LM Tensor Parallelism auf das 70B-Modell an, um das ursprüngliche Modellgewicht auf verschiedene GPUs aufzuteilen. Megatron Sharding auf dem 70B-Modell zerlegt das PyTorch-Modell in FP16-Präzision in 4 Partitionen, konvertiert jede Partition in ONNX-Format und wendet dann eine neue ONNX Runtime Graph-Fusion auf das konvertierte ONNX-Modell an. Das 70B-Modell hat einen Durchsatz von ca. 30 Token pro Sekunde für die Token-Generierung bei Batch-Größe 1, und der End-to-End-Durchsatz beginnt bei 30 tps für kleinere Sequenzlängen mit diesen Optimierungen. Zusätzliche Beispiel-Skripte finden Sie hier.
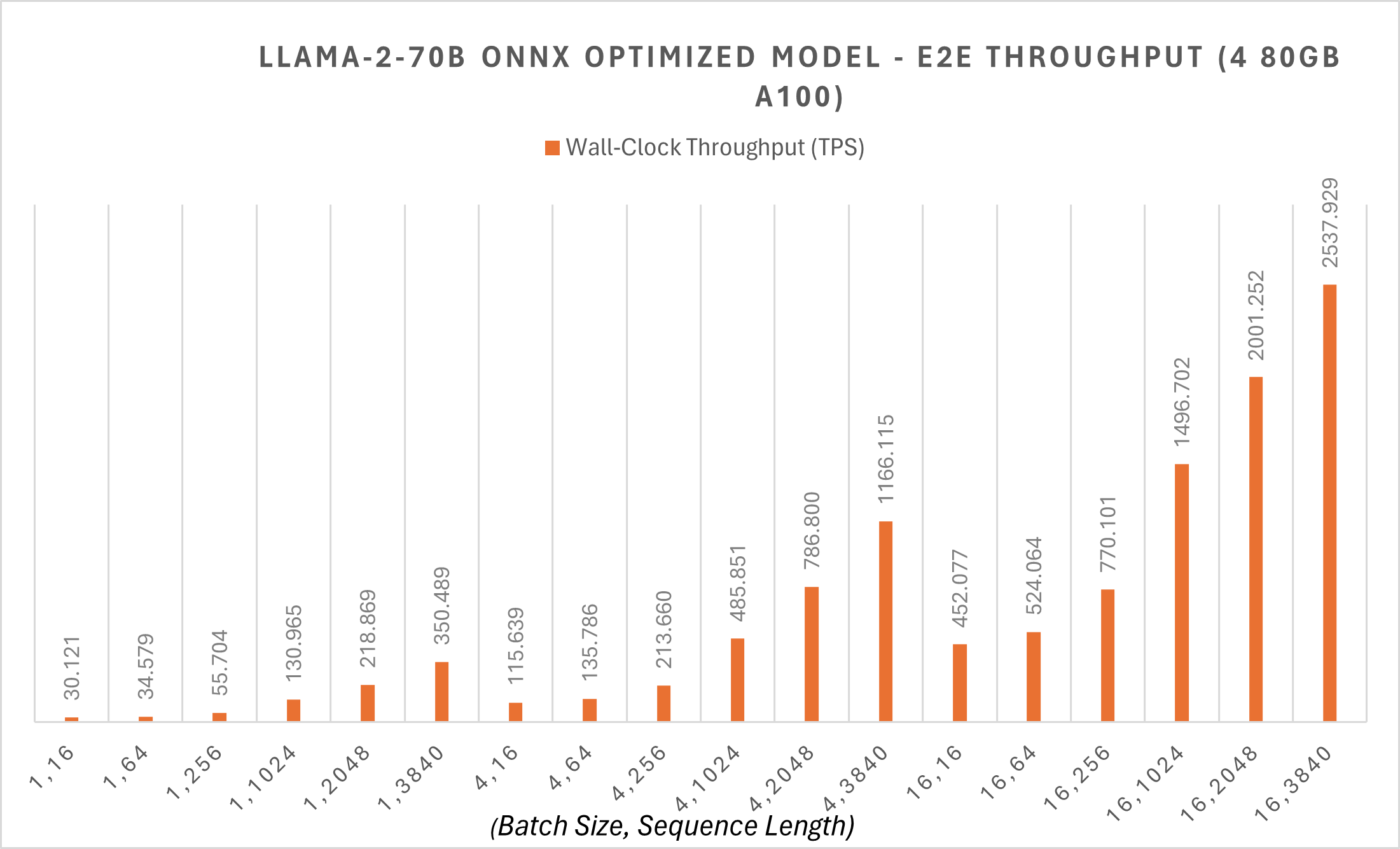
ONNX Runtime-Optimierungen

Die von ONNX Runtime verwendeten Optimierungstechniken, wie Graph-Fusionen, sind auf hochmoderne Modelle anwendbar. Da diese Modelle immer komplexer werden, werden die Techniken zur Anwendung von Graph-Fusionen angepasst, um die zusätzliche Komplexität zu berücksichtigen. Anstatt beispielsweise Fusionsmuster manuell im Graphen abzugleichen, unterstützt ONNX Runtime jetzt automatisiertes Mustererkennung. Anstatt große Teilgraphen von Hand zu erkennen und die vielen Pfade abzugleichen, die sie bilden, können Fusionsmöglichkeiten stattdessen identifiziert werden, indem ein großes Modul als Funktion exportiert und dann gegen die Spezifikation einer Funktion gematcht wird.

Als konkretes Beispiel zeigt Abbildung 6 die Knoten, aus denen die Berechnungen für das Rotary Embedding bestehen. Das Musterabgleichen gegen diesen Teilgraphen ist aufgrund der Anzahl der zu verifizierenden Pfade umständlich. Durch den Export als Funktion zeigt die Elternansicht des Graphen nur die Ein- und Ausgaben und stellt alle diese Knoten als einen einzigen Operator dar.
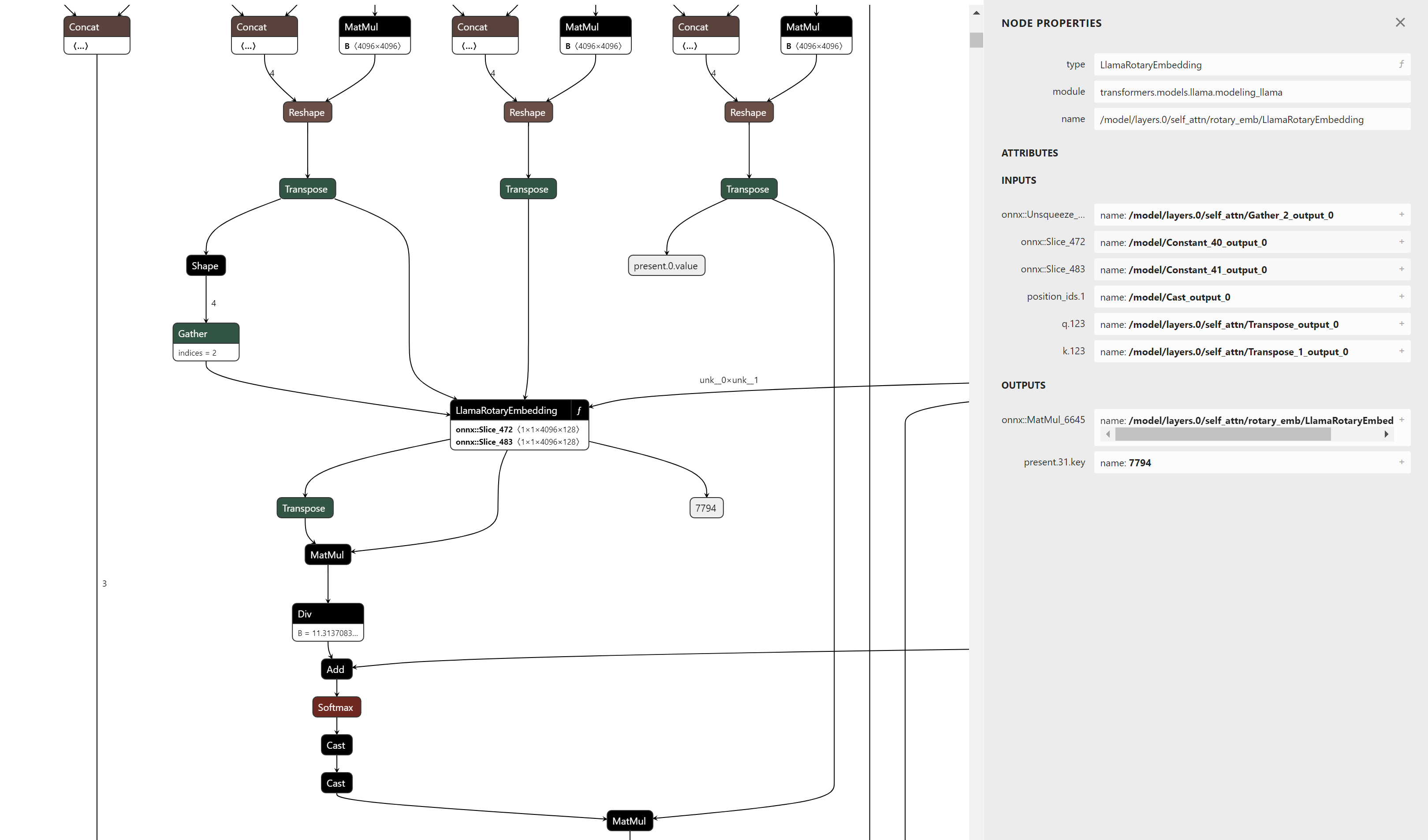
Dieser Ansatz erleichtert die Wartung und Unterstützung zukünftiger Versionen der Rotary Embedding-Berechnungen, da die Mustererkennung nur von den Eingängen und Ausgängen des Operators abhängt und nicht von seiner internen semantischen Darstellung. Er ermöglicht auch, dass andere bestehende Implementierungen von Rotary Embeddings in ähnlichen Modellen wie GPT-NeoX, Falcon, Mistral, Zephyr usw. mit minimalen oder keinen Änderungen abgeglichen und fusioniert werden.
ONNX Runtime fügt auch Unterstützung für den GroupQueryAttention (GQA)-Operator hinzu, der den neuen Flash Attention V2-Algorithmus und seine optimierten Kernel nutzt, um die Aufmerksamkeit effizient zu berechnen. Der GQA-Operator unterstützt die gemeinsame Nutzung von Past-Present-Puffern zwischen dem vergangenen Schlüssel-/Wert-Cache (Past KV Cache) und dem aktuellen Schlüssel-/Wert-Cache (Present KV Cache). Durch die Bindung der aktuellen KV-Caches an die vergangenen KV-Caches ist kein separater On-Device-Speicher für beide Caches erforderlich. Stattdessen können die Past KV-Caches mit genügend On-Device-Speicher vorab zugewiesen werden, so dass während der Inferenz keine neuen On-Device-Speicher angefordert werden müssen. Dies reduziert den Speicherverbrauch, wenn die KV-Caches bei rechenintensiven Workloads groß werden, und senkt die Latenz durch Eliminierung von On-Device-Speicherzuweisungsanfragen. Die Past-Present-Pufferfreigabe kann aktiviert oder deaktiviert werden, ohne das ONNX-Modell ändern zu müssen, was Endbenutzern mehr Flexibilität gibt, den für sie besten Ansatz zu wählen.
Zusätzlich zu diesen Fusions- und Kernel-Optimierungen reduziert ONNX Runtime den Speicherverbrauch des Modells. Neben Quantisierungsverbesserungen (die in einem zukünftigen Beitrag behandelt werden) komprimiert ONNX Runtime die Größe der Cosinus- und Sinus-Caches, die in jedem der Rotary Embeddings verwendet werden, um 50 %. Die Compute-Kernel in ONNX Runtime, die die Rotary Embedding-Berechnungen ausführen, können dieses Format erkennen und ihre parallelisierten Implementierungen verwenden, um die Rotary Embeddings effizienter und mit geringerem Speicherverbrauch zu berechnen. Die Rotary Embedding-Compute-Kernel unterstützen auch interleave- und non-interleaved Formate, um sowohl die Microsoft-Version von LLaMA-2 als auch die Hugging Face-Version von LLaMA-2 zu unterstützen, während sie die gleichen Berechnungen teilen.
Die Optimierungen funktionieren für die Hugging Face-Versionen (Modelle, die mit "-hf" enden) und die Microsoft-Versionen. Sie können die optimierten HF-Versionen aus dem Microsoft LLaMA-2 ONNX Repository herunterladen. Bleiben Sie dran für neuere Microsoft-Versionen, die bald erscheinen!
Optimieren Sie Ihr eigenes Modell mit Olive
Olive ist ein Hardware-abhängiges Modelloptimierungstool, das fortschrittliche Techniken wie Modellkomprimierung, Optimierung und Kompilierung integriert. Wir haben ONNX Runtime-Optimierungen über Olive verfügbar gemacht, sodass Sie den gesamten Optimierungsprozess für eine gegebene Hardware mit einfacher Erfahrung rationalisieren können.
Hier ist ein Beispiel für die Llama2-Optimierung mit Olive, die die in diesem Blog hervorgehobenen ONNX Runtime-Optimierungen nutzt. Unterschiedliche Optimierungsabläufe decken verschiedene Anforderungen ab. Sie haben beispielsweise die Flexibilität, verschiedene Datentypen für die Quantisierung bei CPU- und GPU-Inferenz zu wählen, basierend auf Ihrer Genauigkeitstoleranz. Darüber hinaus können Sie Ihr eigenes Llama2-Modell mit Olive-QLoRa auf Client-GPUs feinabstimmen und die Inferenz mit ONNX Runtime-Optimierungen durchführen.
Anwendungsbeispiel
Hier ist ein Beispiel-Notebook, das Ihnen ein End-to-End-Beispiel zeigt, wie Sie die oben genannten ONNX Runtime-Optimierungen in Ihrer Anwendung verwenden können.
Schlussfolgerung
Die in diesem Blog besprochenen Fortschritte ermöglichen eine schnellere Llama2-Inferenz mit ONNX Runtime und bieten spannende Möglichkeiten für KI-Anwendungen und Forschung. Mit verbesserter Leistung und Effizienz steht die Horizont für Innovationen weit offen, und wir warten gespannt auf neue Anwendungen, die von der lebendigen Community von Entwicklern mit Llama2 und ONNX Runtime erstellt werden. Bleiben Sie dran für weitere Updates!