ONNX Runtime unterstützt Phi-3 Mini-Modelle auf verschiedenen Plattformen und Geräten
22. APRIL 2024
Dank ONNX Runtime und DirectML können Sie Microsofts neueste Eigenentwicklungen, die Phi-3-Modelle, jetzt auf einer Vielzahl von Geräten und Plattformen ausführen. Heute sind wir stolz darauf, die Unterstützung für beide Varianten von Phi-3, phi3-mini-4k-instruct und phi3-mini-128k-instruct, vom ersten Tag an bekannt zu geben. Die optimierten ONNX-Modelle sind verfügbar unter phi3-mini-4k-instruct-onnx und phi3-mini-128k-instruct-onnx.
Viele Sprachmodelle sind zu groß, um lokal auf den meisten Geräten ausgeführt zu werden, aber Phi-3 stellt hier eine bemerkenswerte Ausnahme dar: Diese kleine, aber leistungsstarke Modellsuite erreicht eine vergleichbare Leistung wie Modelle, die 10-mal größer sind! Phi-3 Mini ist außerdem das erste Modell seiner Gewichtsklasse, das lange Kontexte von bis zu 128.000 Tokens unterstützt. Um mehr darüber zu erfahren, wie Microsofts strategische Datenkurierung und innovatives Scaling zu diesen bemerkenswerten Ergebnissen geführt haben, siehe hier.
Sie können ganz einfach mit Phi-3 beginnen, indem Sie unsere neu eingeführte ONNX Runtime Generate() API verwenden, die Sie hier finden!
DirectML und ONNX Runtime skalieren Phi-3 Mini unter Windows
Für sich genommen ist Phi-3 bereits klein genug, um auf vielen Windows-Geräten ausgeführt zu werden, aber warum dort aufhören? Phi-3 durch Quantisierung noch kleiner zu machen, würde die Reichweite des Modells unter Windows dramatisch erweitern, aber nicht alle Quantisierungstechniken sind gleich. Wir wollten die Skalierbarkeit sicherstellen und gleichzeitig die Modellgenauigkeit beibehalten.
Activation-Aware Quantization (AWQ) zur Quantisierung von Phi-3 Mini ermöglicht es uns, die Speichereinsparungen durch Quantisierung mit nur minimalen Auswirkungen auf die Genauigkeit zu erzielen. AWQ erreicht dies, indem es die obersten 1 % der salienten Gewichte identifiziert, die zur Aufrechterhaltung der Modellgenauigkeit notwendig sind, und die verbleibenden 99 % der Gewichte quantisiert. Dies führt im Vergleich zu vielen anderen Quantisierungstechniken zu deutlich geringeren Genauigkeitsverlusten durch Quantisierung mit AWQ. Mehr über AWQ erfahren Sie hier.
Jede GPU, die DirectX 12 unter Windows unterstützt, kann DirectML ausführen, unabhängig davon, ob es sich um eine AMD-, Intel- oder NVIDIA-GPU handelt. DirectML und ONNX Runtime unterstützen jetzt INT4 AWQ, was bedeutet, dass Entwickler diese quantisierte Version von Phi-3 jetzt auf Hunderten von Millionen Windows-Geräten ausführen und bereitstellen können!
Wir arbeiten mit unseren Hardwarepartnern zusammen, um Treiberaktualisierungen bereitzustellen, die die Leistung in den kommenden Wochen weiter verbessern werden. Besuchen Sie unseren Build Talk Ende Mai, um mehr zu erfahren!
Siehe unten für spezifische Leistungsdaten.
ONNX Runtime für Mobilgeräte
Neben der Unterstützung beider Phi-3 Mini-Modelle unter Windows kann ONNX Runtime diese Modelle auch auf anderen Client-Geräten wie Mobilgeräten und Mac-CPUs ausführen und ist somit ein wirklich plattformübergreifendes Framework. ONNX Runtime unterstützt auch Quantisierungstechniken wie RTN, um diese Modelle auf vielen verschiedenen Hardwaretypen ausführen zu können.
ONNX Runtime Mobile ermöglicht es Entwicklern, Inferenz mit KI-Modellen auf Mobil- und Edge-Geräten durchzuführen. Durch den Wegfall der Client-Server-Kommunikation bietet ORT Mobile Datenschutz und ist kostenlos. Mit RTN INT4-Quantisierung reduzieren wir die Größe der hochmodernen Phi-3 Mini-Modelle erheblich und können beide auf einem Samsung Galaxy S21 mit moderater Geschwindigkeit ausführen. Bei der Anwendung der RTN INT4-Quantisierung gibt es einen Abstimmungsparameter für den INT4-Genauigkeitsgrad. Dieser Parameter gibt den minimalen Genauigkeitsgrad an, der für die Aktivierung von MatMul in der INT4-Quantisierung erforderlich ist, und gleicht Leistung und Genauigkeit ab. Zwei Versionen von RTN-quantisierten Modellen wurden mit int4_accuracy_level=1, optimiert für Genauigkeit, und int4_accuracy_level=4, optimiert für Leistung, veröffentlicht. Wenn Sie eine bessere Leistung bei einem leichten Genauigkeitsverlust bevorzugen, empfehlen wir die Verwendung des Modells mit int4_accuracy_level=4.
ONNX Runtime für Server-Szenarien
Für Linux-Entwickler und darüber hinaus ist ONNX Runtime mit CUDA eine großartige Lösung, die eine breite Palette von NVIDIA-GPUs unterstützt, sowohl Consumer- als auch Rechenzentrum-GPUs. Phi-3 Mini-128K-Instruct leistet mit ONNX Runtime und CUDA besser als PyTorch für alle Batch-Größen- und Prompt-Längen-Kombinationen.
Für FP16 CUDA und INT4 CUDA ist Phi-3 Mini-128K-Instruct mit ORT bis zu 5x schneller und bis zu 9x schneller als PyTorch, bzw. Dies liegt daran, dass Phi-3 Mini-128K-Instruct derzeit nicht von Llama.cpp unterstützt wird.
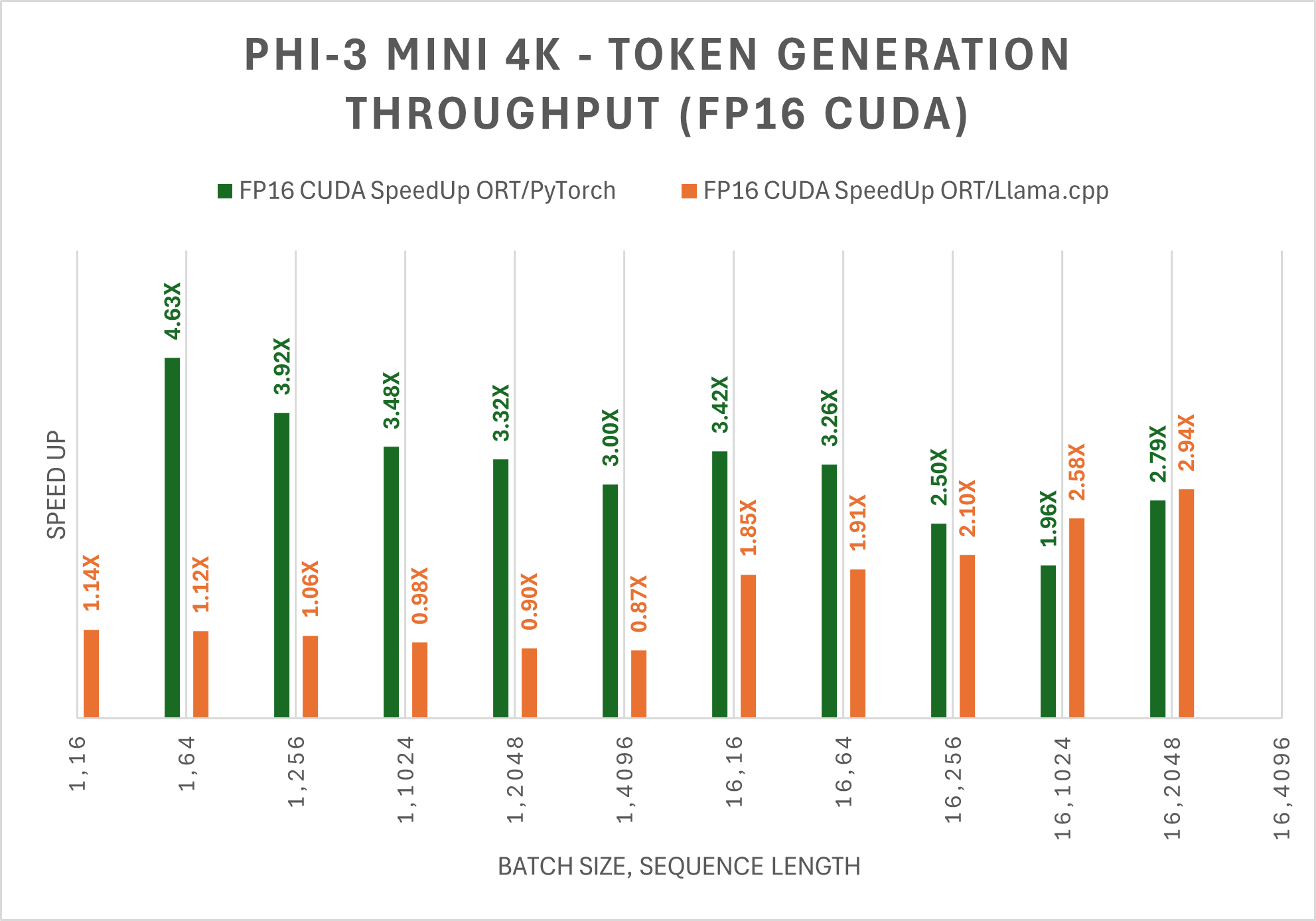
Für FP16 und INT4 CUDA ist Phi-3 Mini-4K-Instruct mit ORT bis zu 5x schneller und bis zu 10x schneller als PyTorch, bzw. Phi-3 Mini-4K-Instruct ist auch bis zu 3x schneller als Llama.cpp bei großen Sequenzlängen.
Ob Windows, Linux, Android oder Mac, es gibt einen Weg, Modelle effizient mit ONNX Runtime auszuführen!
Probieren Sie die ONNX Runtime Generate() API aus
Wir freuen uns, unsere neue Generate() API ankündigen zu können, die die Ausführung der Phi-3-Modelle auf einer Reihe von Geräten, Plattformen und EP-Backends erleichtert, indem sie mehrere Aspekte der generativen KI-Inferenz kapselt. Die Generate() API macht es einfach, LLMs direkt in Ihre Anwendung zu ziehen und abzulegen. Um die frühe Version dieser Modelle mit ONNX auszuführen, folgen Sie den Schritten hier.
Beispiel
python model-qa.py -m /YourModelPath/onnx/cpu_and_mobile/phi-3-mini-4k-instruct-int4-cpu -k 40 -p 0.95 -t 0.8 -r 1.0
Input: <user> Tell me a joke <end>
Output: <assistant> Why don't scientists trust atoms?
Because they make up everything!
This joke plays on the double meaning of "make up." In science, atoms are the fundamental building blocks of matter,
literally making up everything. However, in a colloquial sense, "to make up" can mean to fabricate or lie, hence the humor. <end>
Bitte behalten Sie diesen Bereich für weitere Updates zu AMD und zusätzliche Optimierungen mit ORT 1.18 im Auge. Schauen Sie sich auch unseren Build Talk Ende Mai an, um mehr über diese API zu erfahren!
Leistungskennzahlen
DirectML
DirectML ermöglicht es Entwicklern nicht nur, eine hohe Leistung zu erzielen, sondern auch Modelle im gesamten Windows-Ökosystem bereitzustellen, mit Unterstützung von AMD, Intel und NVIDIA. Das Beste daran ist, dass AWQ bedeutet, dass Entwickler diese Skalierung erzielen und gleichzeitig eine hohe Modellgenauigkeit beibehalten.
Bleiben Sie dran für zusätzliche Leistungsverbesserungen in den kommenden Wochen dank optimierter Treiber von unseren Hardwarepartnern und weiteren Updates der ONNX Generate() API.
| Prompt-Länge | Generierungs-Länge | Wall Clock Tokens/s |
|---|---|---|
| 16 | 256 | 266.65 |
| 16 | 512 | 251.63 |
| 16 | 1024 | 238.87 |
| 16 | 2048 | 217.5 |
| 32 | 256 | 278.53 |
| 32 | 512 | 259.73 |
| 32 | 1024 | 241.72 |
| 32 | 2048 | 219.3 |
| 64 | 256 | 308.26 |
| 64 | 512 | 272.47 |
| 64 | 1024 | 245.67 |
| 64 | 2048 | 220.55 |
CUDA
Die folgende Tabelle zeigt die Verbesserung des durchschnittlichen Durchsatzes der ersten 256 generierten Token (tps) für das Phi-3 Mini 128K Instruct ONNX-Modell. Die Vergleiche beziehen sich auf FP16 und INT4-Präzision auf CUDA, gemessen auf 1 A100 80GB GPU (SKU: Standard_ND96amsr_A100_v4).
 Hinweis: PyTorch Compile und Llama.cpp unterstützen derzeit nicht das Phi-3 Mini 128K Instruct-Modell.
Hinweis: PyTorch Compile und Llama.cpp unterstützen derzeit nicht das Phi-3 Mini 128K Instruct-Modell.Die folgende Tabelle zeigt die Verbesserung des durchschnittlichen Durchsatzes der ersten 256 generierten Token (tps) für das Phi-3 Mini 4K Instruct ONNX-Modell. Die Vergleiche beziehen sich auf FP16 und INT4-Präzision auf CUDA, gemessen auf 1 A100 80GB GPU (SKU: Standard_ND96amsr_A100_v4).

Die Leistung wird auch auf CPUs und anderen Geräten verbessert.
Sicherheit
Sicherheitsmetriken und RAI entsprechen den Basis-Phi-3-Modellen. Weitere Details finden Sie hier.
Probieren Sie ONNX Runtime für Phi3 aus
Dieser Blogbeitrag erklärt, wie ONNX Runtime und DirectML das Phi-3-Modell optimieren. Wir haben Anleitungen zum Ausführen von Phi-3 unter Windows und auf anderen Plattformen sowie erste Benchmarking-Ergebnisse aufgenommen. Weitere Verbesserungen und Leistungsoptimierungen sind in Arbeit, halten Sie also Ausschau nach der ONNX Runtime 1.18 Version Anfang Mai!
Wir ermutigen Sie, Phi-3 auszuprobieren und Ihr Feedback im ONNX Runtime GitHub-Repository zu teilen!