Kritzeln zum Löschen auf Goodnotes für Windows, Web und Android, powered by ONNX Runtime
Von
Pedro Gómez, Emma Ning18. NOVEMBER 2024

Seit drei Jahren arbeitet das Goodnotes-Ingenieursteam an einem Projekt, um die erfolgreiche Notiz-App für iPads auf andere Plattformen wie Windows, Web und Android zu bringen. Dieser Beitrag beschreibt, wie die iPad-App des Jahres 2022 eine der meistgewünschten KI-Funktionen, das Kritzeln zum Löschen, gleichzeitig für die drei Plattformen unter Verwendung von ONNX Runtime implementiert hat.
📝 Was ist Kritzeln zum Löschen?
Wir sind alle Menschen, also machen wir alle Fehler. Kritzeln zum Löschen ist eine einfache Funktion, mit der der Benutzer Inhalte löschen kann, ohne den Radierer zu verwenden, indem er einfach über den zuvor erstellten Inhalt kritzelt.

Jede Notiz, die der Benutzer zuvor geschrieben hat, egal was Sie geschrieben haben, kann mit einer einfachen Kritzelgeste gelöscht werden. Diese Funktion mag für den Benutzer recht einfach aussehen, aber aus technischer Sicht recht komplex.

Dies war die erste Funktion, die das Goodnotes-Ingenieursteam für Windows, Web und Android unter Verwendung künstlicher Intelligenz veröffentlicht hat, dank ONNX Runtime, das hochleistungsfähige Modellinferenzen plattformübergreifend für Edge AI bietet. Das Team verwendete ein intern trainiertes Modell für dieses Projekt und evaluierte es geräteintern auf drei verschiedenen Plattformen.
🔍 Wie wird ein Kritzeln erkannt?
Für Goodnotes ist eine Kritzelgeste nichts anderes als ein weiterer Strich, der dem Dokument gemäß einem speziellen Muster hinzugefügt wird. Es gibt 2 Merkmale, die ein Strich haben muss, um als Kritzeln zu gelten:
- Die Anzahl der Punkte, die Teil des Strichs sind, sollte ausreichend groß sein.
- Das mit ONNX Runtime evaluierte KI-Modell sollte die Striche als Kritzeln erkennen.
Für das Ingenieurteam bedeutet dies, dass sie für jede Notiz, die die Goodnotes-Teams zu einem Dokument hinzufügen, die Größe und das KI-Modell bewerten müssen, um festzustellen, ob diese neue Notiz, die zu einem bestimmten Dokument hinzugefügt wurde, ein Kritzeln ist oder nicht.
Sobald die Vorverarbeitungsphase prüft, ob die Notizgröße einen bestimmten Schwellenwert überschreitet, ist es an der Zeit, einen klassischen KI-Modellauswertungsfluss wie diesen zu befolgen:
- Extrahieren Sie die Notizmerkmale aus den Punkten.
- Evaluieren Sie das KI-Modell mit ONNX Runtime.
Für die Merkmalsextraktion normalisiert das Goondotes-Team die Punkte im Notizbereich und wandelt eine Liste von Punkten, die vom Benutzerstift generiert wurden, in ein Array von Gleitkommazahlen um. Dieser Prozess ist nichts anderes als die klassische Merkmalsextraktion, der alle KI-Modelle folgen, um die Benutzerdaten in etwas umzuwandeln, das das KI-Modell verstehen kann.
Das für dieses Projekt verwendete KI-Modell ist ein überwachtes Modell, das auf LSTM basiert, das das Team entwickelt und auf jeder Plattform bereitgestellt hat, sodass alle Benutzer es geräteintern auswerten können, auch wenn keine Internetverbindung besteht.
Sobald die Punkte als etwas dargestellt sind, das das KI-Modell verarbeiten kann, können wir unter Verwendung von ONNX Runtime und dem Lesen des Ausgabemodells, das wir als Score behandeln, feststellen, ob die neu hinzugefügte Notiz ein Kritzeln ist oder nicht. Wenn der Strich als Kritzeln betrachtet wird, werden alle Notizen darunter automatisch gelöscht.
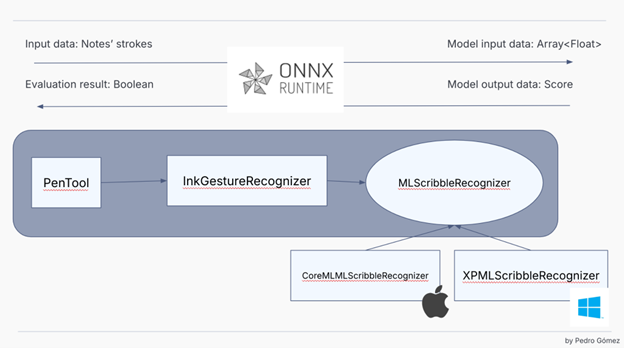
🤝 Warum ONNX Runtime?
Als das Goodnotes-Team die Implementierung dieser Funktion auswerten musste, war eine Entscheidung, die sie treffen mussten, wie das KI-Modell ausgewertet werden sollte. Dies war das erste Projekt, bei dem das Team KI einsetzte, und die iOS-Version dieses Produkts verwendete CoreML, das mit dem aktuellen Tech-Stack des Projekts nicht kompatibel ist, da diese Apple-Technologie außerhalb des iOS/MacOS SDK nicht verfügbar ist. Also beschlossen sie, etwas anderes zu versuchen.

Der Goodnotes-Tech-Stack für Windows, Web und Android basiert auf Webtechnologien. Intern verwendet die Anwendung eine Progressive Web Application. Wenn die App aus dem Microsoft Store oder einem anderen Store wie Google Play installiert wird, verwendet die App einen nativen Wrapper, aber letztendlich handelt es sich bei diesem Projekt um eine Webanwendung, die als Vollbild-Native-App läuft. Das bedeutet, dass die Technologie, die das Team zur Auswertung des KI-Modells verwenden musste, mit einem Web-Tech-Stack kompatibel sein musste und zudem performant genug für ihre Bedürfnisse sein musste, um Hardware-Runtimes zu ermöglichen, wann immer möglich. Bei der Suche nach verschiedenen Alternativen fanden sie ONNX als portables Format und ONNX Runtime mit Web-Lösung und beschlossen, es auszuprobieren. Nach einigen Experimenten und Prototypen, die vor der Feature-Implementierung mit ONNX Runtime erstellt wurden, entschied sich das Team, dass dies die richtige Technologie war!
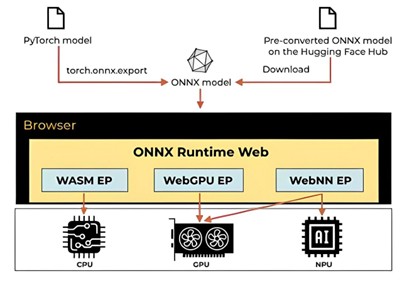
Es gab vier Gründe, warum das Team sich für ONNX Runtime anstelle anderer Technologien entschied:
- Der entwickelte Prototyp zeigte, dass die ONNX Runtime-Integration für uns ziemlich einfach war und uns alle benötigten Funktionen bot.
- ONNX ist ein portables Format, mit dem wir unsere aktuellen CoreML-Modelle in etwas exportieren können, das wir auf vielen verschiedenen Betriebssystemen auswerten können.
- Execution Provider in ONNX Runtime bieten hardware-spezifische Beschleunigung, die es uns ermöglicht, die bestmögliche Leistung bei der Modellbewertung zu erzielen. Speziell für die Web-Lösung gibt es den WSAM-Execution Provider für die CPU-Ausführung und WebNN und WebGPU-Execution Provider für weitere Beschleunigung durch Nutzung von GPUs/NPUs, was für uns sehr interessante Beispiele sind.
- Kompatibilität mit dem LSTM-Design für das KI-Modell.
💻 Wie sieht unser ONNX Runtime-Code aus?
Das Goodnotes-Team teilt die meisten Geschäftslogikcodes für die Goodnotes-Anwendung mit dem iOS/Mac-Team. Das bedeutet, sie kompilieren die ursprüngliche Swift-Codebasis, verarbeiten die Striche und post-prozessieren die Modellausgabe von Swift über Web Assembly. Aber es gibt einen Punkt im Ausführungsstapel, an dem das Goodnotes-Team das Modell auswerten muss, wo das Team die Ausführung von Swift in die Web-Umgebung mit ONNX Runtime delegiert.
Der TypeScript-ONNX Runtime-Code, der das Modell auswertet, ähnelt dem folgenden Snippet:
export class OnnxScribbleToEraseAIModel extends OnnxAIModel<Array<Array<number>>, EvaluationResult>
implements ScribbleToEraseAIModel
{
getModelResource(): OnDemandResource {
return OnDemandResource.ScribbleToErase;
}
async evaluateModel(input: Array<Array<number>>): Promise<EvaluationResult> {
const startTime = performance.now();
const { tensor, initializeTensorTime } = this.initializeTensor(input);
const { evaluationScore, evaluateModelTime } = await this.runModel(tensor);
const result = {
score: evaluationScore ?? 0.0,
timeToInitializeTensor: initializeTensorTime,
timeToEvaluateTheModel: evaluateModelTime,
totalExecutionTime: performance.now() - startTime,
};
return result;
}
…..Wie Sie sehen können, ist die Implementierung der klassische Code, den Sie von jeder KI-Funktion erwarten würden. Die Eingabedaten werden als Array von Merkmalen erhalten, die wir später verwenden, um das Modell mit einem Tensor zu füttern. Sobald die Auswertung abgeschlossen ist, prüfen wir den als Modellausgabe erhaltenen Score und betrachten die Eingabe als Kritzeln, wenn der Score über einem bestimmten Schwellenwert liegt.
Wie Sie im Code sehen können, verfolgen wir zusätzlich zur Initialisierung des Tensors und zur Auswertung des Modells auch die Ausführungszeit, um unsere Implementierung zu validieren und die Ressourcen besser zu verstehen, die in der Produktion benötigt werden, wenn echte Benutzer diese Funktion nutzen.
private initializeTensor(input: number[][]) {
const prepareTensorStartTime = performance.now();
const modelInput = new Float32Array(input.flat());
const tensor = new Tensor(modelInputTensorType, modelInput, modelInputDimensions);
const initializeTensorTime = performance.now() - prepareTensorStartTime;
return { tensor, initializeTensorTime };
}
private async runModel(tensor: Tensor) {
const evaluateModelStartTime = performance.now();
const inferenceSession = this.session;
const outputMap = await inferenceSession.run({ x: tensor });
const outputTensor = outputMap[modelOutputName];
const evaluationScore = outputTensor?.data[0] as number | undefined;
const evaluateModelTime = performance.now() - evaluateModelStartTime;
return { evaluationScore, evaluateModelTime };
}Darüber hinaus hat sich das Goodnotes-Team in diesem Fall entschieden, das KI-Modell mithilfe von ONNX Runtime aus einem Web Worker zu laden und auszuwerten und die Inferenzsitzung über einen Web Worker auszuführen, da dieser Pfad in unserer Anwendung Teil eines kritischen UX-Flows ist und wir die Leistungsauswirkungen für die Benutzer minimieren wollten.
ort.env.logLevel = 'fatal';
ort.env.wasm.wasmPaths = '/onnx/providers/wasm/';
this.session = await InferenceSession.create(modelURL);Der für dieses Projekt konfigurierte Execution Provider ist der CPU-Provider gemäß der Modellarchitektur. Dies ist ein leichtgewichtiges Modell, und wir können mit dem Standard-CPU-Execution Provider, der im Hintergrund von WASM betrieben wird, sehr schnelle Ausführungszeiten erzielen. Wir planen, für fortgeschrittenere Modelle in neuen KI-Szenarien WebGPU- und WebNN-Execution Provider zu verwenden.
🚀 Bereitstellung und Integration
Aufgrund des von dem Team verwendeten technischen Stacks ist die Verwendung von Webtechnologien bei der ONNX Runtime-Integration und der Art und Weise, wie wir das KI-Modell hosten, erwähnenswert. Für dieses Projekt verwendet Goodnotes Vite als Frontend-Tooling, daher mussten sie die Vite-Konfiguration ein wenig modifizieren, um nicht nur unser KI-Modell, sondern auch die vom CPU-Execution Provider benötigten Ressourcen zu verteilen. Es war für das Team keine große Sache, da die ONNX Runtime-Dokumentation bereits die Verwendung von Bundlern abdeckt, aber es war für sie ziemlich interessant, da die App eine PWA ist, die offline verwendet werden kann, und diese Änderung die Bundle-Größe erhöhte, indem sie nicht nur die Modelldatei, sondern auch alle vom ONNX Runtime benötigten Ressourcen enthielt.
📈 Ergebnisse nach einigen Monaten in Produktion
Goodnotes hat diese Funktion vor Monaten veröffentlicht. Seit dem ersten Tag nutzten alle Benutzer dieses Kritzeln zum Löschen-Modell transparent. Einige von ihnen begannen proaktiv, Kritzelgesten zum Löschen von Inhalten zu verwenden, andere entdeckten diese Funktion als eine natürliche Geste.
Seit dem Veröffentlichungsdatum hat das Goodnotes-Team das KI-Modell mit ONNX Runtime fast 2 Milliarden Mal ausgewertet! Mit dem CPU-Execution Provider und der Ausführung des Modells aus einem Worker erreichte das Team P95 der Auswertungszeit unter 16 Millisekunden und P99 unter 27 Millisekunden! Benutzer auf der ganzen Welt, von verschiedenen Betriebssystemen und Plattformen, haben bereits ihre Notizen mit der Kritzeln zum Löschen-Funktion geändert, und das Team ist super stolz auf die technischen Errungenschaften, die dank dieser erstaunlichen ONNX Runtime-Lösung erzielt wurden!