Hohe Leistung bei Echtzeit-ML auf Geräten mit NimbleEdge, unter Verwendung von ONNX Runtime
Von
Nilotpal Pathak, Siddharth Mittal, Scott McKay, Natalie Kershaw, Emma Ning17. JUNI 2024
NimbleEdge ist eine On-Device Machine Learning (ML)-Plattform, die Echtzeit-Personalisierung in mobilen Apps ermöglicht und Datenerfassung, -verarbeitung und ML-Inferenz auf den mobilen Geräten der Endbenutzer anstelle in der Cloud ausführt. Die effiziente Nutzung der mobilen Rechenleistung zur Erzielung optimaler Leistung bei minimaler Ressourcennutzung des Geräts ist eine zentrale Priorität für NimbleEdge. Zu diesem Zweck nutzt NimbleEdge verschiedene ML-Inferenz-Runtimes, darunter prominent ONNX Runtime.
In diesem Blogbeitrag werden wir untersuchen, wie On-Device Compute für kosteneffizientes, datenschutzfreundliches Echtzeit-ML in mobilen Apps genutzt werden kann und wie NimbleEdge ONNX Runtime dafür einsetzt. Wir teilen auch Ergebnisse der On-Device-Bereitstellung von NimbleEdge bei einem der größten Fantasy-Gaming-Plattformen Indiens mit Hunderten von Millionen Nutzern.
Einleitung
Mit der Weiterentwicklung digitaler Verbraucheranwendungen ist Machine Learning (ML) immer zentraler für digitale Erlebnisse geworden (in E-Commerce, Gaming, Unterhaltung). ML-basierte Empfehlungssysteme sind ein prominentes Beispiel für dieses Phänomen. Sie reduzieren die Wahlüberlastung und fördern Konversion und Engagement und sind heute in groß angelegten Apps üblich.
Traditionell nutzten Empfehlungssysteme nur das historische Kundenverhalten (z. B. Käufe, Ansichten, Likes), das wöchentlich, täglich oder alle paar Stunden aktualisiert wurde. Pioniere wie LinkedIn, Doordash und Pinterest haben jedoch in letzter Zeit Near-Real-Time- und Echtzeit-Funktionen in Empfehlungen integriert. Dies ermöglicht hochaktuelle Empfehlungen, die auf Benutzerinteraktionen von nur wenigen Minuten oder sogar Sekunden basieren, und führt zu einem signifikanten Anstieg wichtiger Geschäftsmetriken.
Herausforderungen bei Echtzeit-ML in der Cloud
Der Aufbau von Echtzeit-ML-Systemen in der Cloud birgt jedoch mehrere große Herausforderungen:

- Hohe Rechenkosten: Unerschwinglich hohe Cloud-Kosten für die Speicherung und Verarbeitung von Benutzerinteraktionsdaten während der Sitzung in Echtzeit.
- Markteinführungszeit und Komplexität: Die Einrichtung von Echtzeit-Cloud-Pipelines für ML ist komplex und erfordert erhebliche Zeit und Entwicklerbandbreite.
- Datenschutzrisiko und Compliance: Die Clickstream-Daten der Benutzer während der Sitzung müssen zur Verarbeitung an Cloud-Server gesendet werden, was Datenschutzbedenken aufwirft.
- Skalierungsprobleme: Die Bewältigung von Verkehrsschwankungen erfordert entweder massive Reserve-Cloud-Kapazität oder eine schnelle Skalierung, was in der Cloud schwierig zu erreichen ist.
- Hohe Latenz: Hohe Latenz aufgrund der Zeit, die für Cloud-API-Aufrufe von/zu mobilen Geräten der Benutzer benötigt wird.
On-Device ML als Alternative
Die Ausführung von Echtzeit-ML für Empfehlungen auf den mobilen Geräten der Benutzer ist eine praktikable Alternative zur Cloud-Nutzung. Dies eliminiert die meisten der oben genannten Cloud-bedingten Herausforderungen.
- Kosten: Deutlich geringere Cloud-Rechenanforderungen durch On-Device-Inferenz und Datenverarbeitung.
- Datenschutz: Benutzerinteraktionsdaten während der Sitzung werden auf dem Gerät verarbeitet, was den Datenschutz erhöht.
- Latenz: Die meisten modernen Smartphones sind in der Lage, Datenverarbeitung und Inferenzberechnungen schnell durchzuführen.
- Skalierung: Mühelose Skalierung, da eine Verkehrszunahme zu mehr verfügbaren mobilen Geräten für die Berechnung führt.
Die Entwicklung und Wartung von On-Device-Echtzeit-ML-Systemen ist jedoch ebenfalls sehr komplex und erfordert den Aufbau von Systemen für:
- On-Device Echtzeit-Event-Erfassung und -Speicherung
- On-Device Feature-Verarbeitung (wie z. B. rollierende Fensteraggregationen)
- Feature-Synchronisierung aus der Cloud
- ML-Inferenz-Ausführung, die Latenz und Ressourcennutzung über verschiedene mobile Geräte hinweg gut ausbalanciert.
All dies sind sehr komplexe und zeitaufwändige Unterfangen, weshalb performantes On-Device-Echtzeit-ML eine große Herausforderung darstellt.
NimbleEdge mit ONNX Runtime: End-to-End On-Device ML-Plattform
NimbleEdge umgeht die genannten Komplexitäten mit einer End-to-End-verwalteten On-Device-Echtzeit-ML-Plattform. Die Plattform beschleunigt und optimiert Prozesse über den gesamten On-Device-ML-Lebenszyklus hinweg – sei es bei der Experimentierung, Bereitstellung oder Wartung.
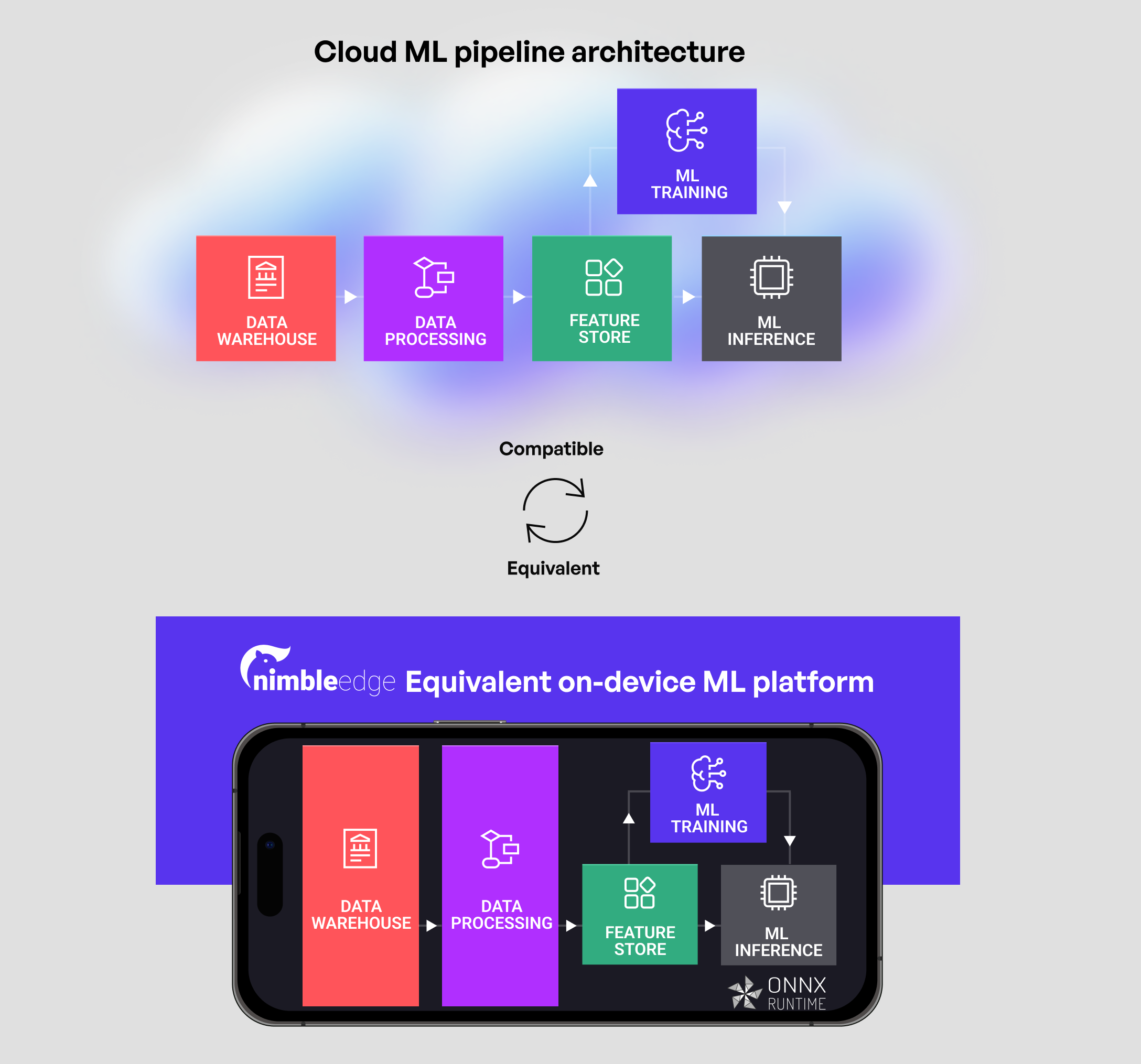
Fertig einsetzbare On-Device ML-Infrastruktur
- On-Device-Datenbank: Speichern Sie In-Session-Benutzerereignisse (z. B. Produktansichten, Hinzufügungen zum Warenkorb im E-Commerce) in einer verwalteten On-Device-Datenbank mit einer Abfragelatenz von
< 1ms. - Datenverarbeitung: Führen Sie Python-ähnliche Preprocessing-Skripte auf dem Gerät aus, um Features aus Echtzeit-Benutzereingaben zu berechnen.
- Feature-Store-Synchronisierung: Pflegen Sie eine häufig aktualisierte On-Device-Kopie von Cloud-Features, die für Echtzeit-ML benötigt werden (z. B. Liste offener Restaurants für die Echtzeit-Rangfolge von Restaurants auf der Startseite einer Essensliefer-App).
Mühelose On-Device ML-Modellverwaltung
- Over-the-Air-Updates, um ML-Modellaktualisierungen und Frontend-App-Updates vollständig zu entkoppeln und schnelle ML-Experimente zu ermöglichen.
Schlüsselfertige, optimierte Inferenz-Runtime-Konfiguration
- Bereitstellungs- und Kompatibilitätsprüfung: Verwaltung von Bereitstellungen und Kompatibilitätsmatrizen (z. B. ML-Modell, SDK-Operatoren, Android/iOS, Hardwarefähigkeiten wie NPU/GPU usw.).
- Modell-Performance-Optimierung: Gewährleistung optimaler Modellleistung durch Auswahl der leistungsstärksten Inferenz-Runtime aus einem Multi-Executor-Fundament; Konfiguration von Backend-Dispatch-Ausführung, paralleler Verarbeitung, Thread- und Kernanzahl und mehr für jede (Gerätemodell x ML-Modell)-Permutation.
ONNX Runtime für die Inferenz-Ausführung
Die optimale Ausführung von Inferenz ist entscheidend für On-Device ML. Einerseits erfordern Echtzeit-ML-Anwendungsfälle schnelle Berechnungen, um die Latenz für Endbenutzer zu minimieren. Andererseits sind mobile Geräte ressourcenbeschränkt mit begrenztem Akku und begrenzter Verarbeitungsleistung. Das Erreichen der optimalen Balance zwischen Latenz und Geräteressourcennutzung für über 5.000 heute verbreitete einzigartige Gerätetypen ist eine massive Herausforderung.
Für die Inferenz-Ausführung nutzt NimbleEdge eine Reihe von Runtimes, darunter prominent ONNX Runtime. ONNX Runtime ist eine Open-Source-Engine mit hoher Leistung zur Beschleunigung von Machine-Learning-Modellen in Cloud- und Edge-Umgebungen. Eine seiner Schlüsselfunktionen, ONNX Runtime Mobile, ist speziell für leichtere und schnellere Modellinferenzen optimiert. Es bietet Konfigurationen für Quantisierung, Hardwarebeschleunigung (z. B. mit CPU/GPU/NPU), Operator-Fusion, parallele Verarbeitung und mehr. NimbleEdge nutzt ONNX Runtime Mobile auf vielfältige und wirkungsvolle Weise:
- Anwendung von statischen und dynamischen Quantisierungstechniken zur signifikanten Reduzierung des Speicherfußabdrucks von Modellen.
- Anpassung des Runtime-Builds an die spezifischen Operatoren und Datentypen, die vom(den) Modell(en) benötigt werden.
- Nutzung von Low-Level-Steuerungsmechanismen zur sorgfältigen Verwaltung und Optimierung des Ressourcenverbrauchs (CPU, Akku).
Durch die hier aufgeführten Fähigkeiten ermöglicht die umfassende On-Device-ML-Plattform von NimbleEdge Hochleistungs-Echtzeit-ML-Bereitstellungen in Tagen anstatt in Monaten.
Fallstudie: Echtzeit-Rangfolge von Fantasy-Sport-Wettbewerben für führendes indisches Fantasy-Gaming-Unternehmen
Fantasy Gaming co (Name aus Vertraulichkeitsgründen geschwärzt) ist eine indische Fantasy-Sportplattform (ähnlich wie Fanduel/Draftkings in den USA) mit Hunderten von Millionen Nutzern und einer Spitzen-Konkurrenz von mehreren Millionen Nutzern. Fantasy Gaming co bietet Tausende von Fantasy-Wettbewerben über Dutzende von Spielen aus mehr als 10 Sportarten an, wobei jeder Wettbewerb sich in Höhe der Teilnahmegebühr, Gewinnwahrscheinlichkeit und Teilnehmerzahl unterscheidet.
Zur Optimierung des Benutzererlebnisses betrieb Fantasy Gaming co ein Empfehlungssystem, das personalisierte Wettbewerbsempfehlungen für Benutzer basierend auf historischen Interaktionen lieferte. Sie analysierten die Clickstream-Daten der Kunden und stellten fest, dass die Integration von Benutzerinteraktionen während der Sitzung in die Empfehlungssysteme die Qualität der Empfehlungen im Vergleich zu stündlich generierten Batch-Vorhersagen erheblich verbessern würde.
Aus diesem Grund war Fantasy Gaming co daran interessiert, Echtzeit-Empfehlungen, die sessionsbewusst sind, bereitzustellen. Die Implementierung war jedoch aufgrund der oben genannten Herausforderungen bei Echtzeit-ML in der Cloud schwierig. Daher wandte sich Fantasy Gaming co an On-Device ML mit NimbleEdge zur Implementierung von Echtzeit-personalisierten Wettbewerbsempfehlungen.
Ergebnisse
Mit NimbleEdge kann Fantasy Gaming co nun Features und Vorhersagen basierend auf Echtzeit-Benutzerinteraktionen generieren, was zu einer verbesserten Relevanz der Empfehlungen für Millionen von Nutzern führt. Zusätzlich wurde die Inferenz mit Millisekunden-Latenz geliefert, mit minimalen Auswirkungen auf Akku und CPU-Nutzung!
Anzahl der Inferenzen: 7B+
Anzahl der Geräteabstürze: 0
Durchschnittliche Latenz: ~15 Millisekunden
CPU-Auslastungsspitze: <1 %
Erweiterbare Anwendungsfälle
Die in diesem Blogbeitrag diskutierte Methodik lässt sich leicht auf ähnliche Echtzeit-Anwendungsfälle in anderen Branchen anwenden – wie z. B. E-Commerce, soziale Medien und Unterhaltung.
E-Commerce: Echtzeit-Empfehlungen
E-Commerce-Apps bieten Empfehlungen beim Checkout, auf der Startseite und auf Produktseiten. Die Integration von In-Session-Benutzereingaben, wie Seitenaufrufe, Suchanfragen und Hinzufügungen zum Warenkorb, kann die Qualität der Empfehlungen erheblich verbessern.
Der chinesische E-Commerce-Gigant Taobao berichtet einen Anstieg des GMV um ~10 % durch sessionsbewusste personalisierte Homepage-Empfehlungen! Aufgrund der Herausforderungen von Echtzeit-ML in der Cloud hat Alibaba das Empfehlungssystem auf dem Gerät bereitgestellt, was zu einer erheblichen Umsatzsteigerung führte.
Soziale Medien: Feed-Rangfolge
Die Nutzerabsichten können von Sitzung zu Sitzung bei Nutzern sozialer Medien erheblich variieren. Soziale Medien-Apps, die in der Lage sind, die Absicht in Echtzeit zu erfassen und entsprechend zu reagieren, erzielen eine deutlich höhere Bindung.
Als Beispiel Pinterest steigerte die Repins um >10 %, indem es In-Session-Benutzeraktionen einbezog, um die Homepage der Nutzer in Echtzeit anzupassen!
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass die On-Device-Ausführung von Echtzeit-ML eine Reihe von transformativen Anwendungsfällen in verschiedenen Branchen ermöglicht und massive Topline-Vorteile freisetzt. Obwohl die Ausführung herausfordernd ist, beschleunigen und vereinfachen Tools wie NimbleEdge und ONNX Runtime die Implementierung erheblich und etablieren sich so als führende Alternativen für performantes, Echtzeit-On-Device-ML.