Verbessern Sie die Teamzusammenarbeit bei der Optimierung von KI-Modellen mit der Olive Shared Cache-Funktion
Von
Xiaoyu Zhang, Devang Patel, Sam Kemp30. OKTOBER 2024
👋 Einführung
In der sich ständig weiterentwickelnden Welt des maschinellen Lernens ist die Optimierung ein entscheidender Pfeiler zur Verbesserung der Modellleistung, Reduzierung der Latenz und Senkung der Kosten. Olive ist ein leistungsstarkes Werkzeug, das entwickelt wurde, um den Optimierungsprozess durch seine innovative Shared Cache-Funktion zu optimieren.
Effizienz im maschinellen Lernen beruht nicht nur auf der Wirksamkeit von Algorithmen, sondern auch auf der Effizienz der beteiligten Prozesse. Die Shared Cache-Funktion von Olive – unterstützt durch Azure Storage – verkörpert dieses Prinzip, indem sie es ermöglicht, zwischengespeicherte Modelle nahtlos innerhalb eines Teams zu speichern und wiederzuverwenden, wodurch redundante Berechnungen vermieden werden.
Dieser Blog-Beitrag befasst sich damit, wie die Shared Cache-Funktion von Olive Ihnen helfen kann, Zeit und Kosten zu sparen, illustriert mit praktischen Beispielen.
Voraussetzungen
- Ein Azure Storage Account. Details zur Erstellung eines Azure Storage Accounts finden Sie unter Erstellen eines Azure Storage Accounts.
- Sobald Sie Ihren Azure Storage Account erstellt haben, müssen Sie einen Speichercontainer erstellen (ein Container organisiert eine Reihe von Blobs, ähnlich einem Verzeichnis in einem Dateisystem). Weitere Details zur Erstellung eines Speichercontainers finden Sie unter Container erstellen.
🤝 Teamzusammenarbeit während des Optimierungsprozesses
Benutzer A beginnt den Optimierungsprozess, indem er den Olive-Befehl `quantize` verwendet, um das Modell Phi-3-mini-4k-instruct mit dem AWQ-Algorithmus zu optimieren. Dieser Schritt wird durch die folgende Befehlszeilenausführung gekennzeichnet
olive quantize \
--model_name_or_path Microsoft/Phi-3-mini-4k-instruct \
--algorithm awq \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
Hinweis
- Das
--account_namesollte auf den Namen Ihres Azure Storage Accounts gesetzt werden.- Das
--container_namesollte auf den Namen des Containers im Azure Storage Account gesetzt werden.
Der Optimierungsprozess generiert ein Protokoll, das bestätigt, dass der Cache an einem gemeinsam genutzten Speicherort in Azure gespeichert wurde.
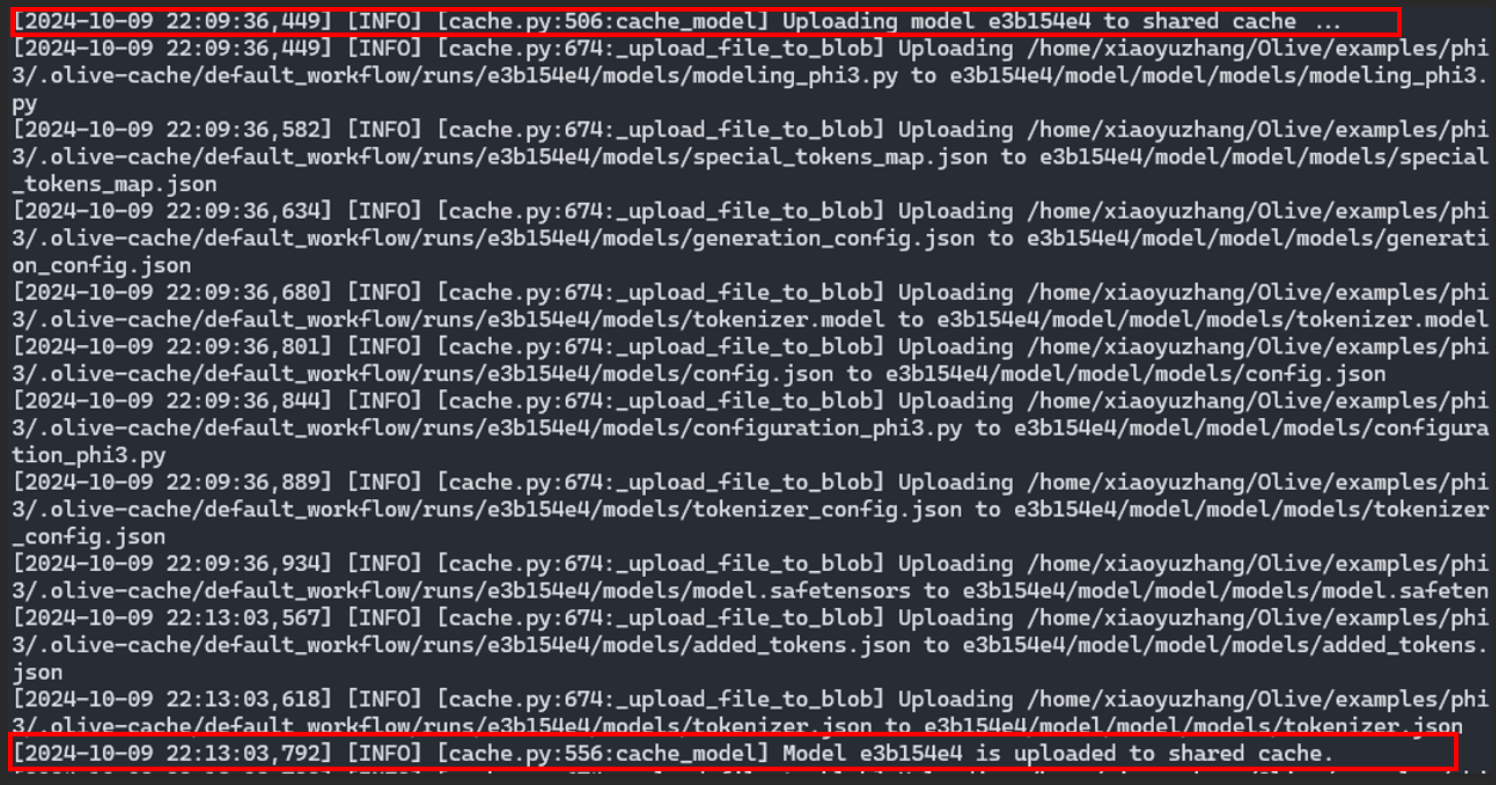 Olive-Protokollausgabe von Benutzer A: Das quantisierte Modell aus dem Workflow von Benutzer A wird im Shared Cache in der Cloud hochgeladen.
Olive-Protokollausgabe von Benutzer A: Das quantisierte Modell aus dem Workflow von Benutzer A wird im Shared Cache in der Cloud hochgeladen.Dieser Shared Cache ist ein entscheidendes Element, da er das optimierte Modell speichert und es für zukünftige Verwendungen durch andere Benutzer oder Prozesse zugänglich macht.
Nutzung des Shared Cache
Benutzer B, ein weiteres aktives Teammitglied im Optimierungsprojekt, profitiert von den Bemühungen von Benutzer A. Durch die Verwendung desselben `quantize`-Befehls zur Optimierung von Phi-3-mini-4k-instruct mit dem AWQ-Algorithmus wird der Prozess von Benutzer B erheblich beschleunigt. Der Befehl ist identisch, und Benutzer B nutzt denselben Azure Storage Account und Container.
olive quantize \
--model_name_or_path Microsoft/Phi-3-mini-4k-instruct \
--algorithm awq \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
Ein wichtiger Teil dieses Schritts ist die folgende Protokollausgabe, die die Abfrage des quantisierten Modells aus dem Shared Cache hervorhebt, anstatt die AWQ-Quantisierung neu zu berechnen.
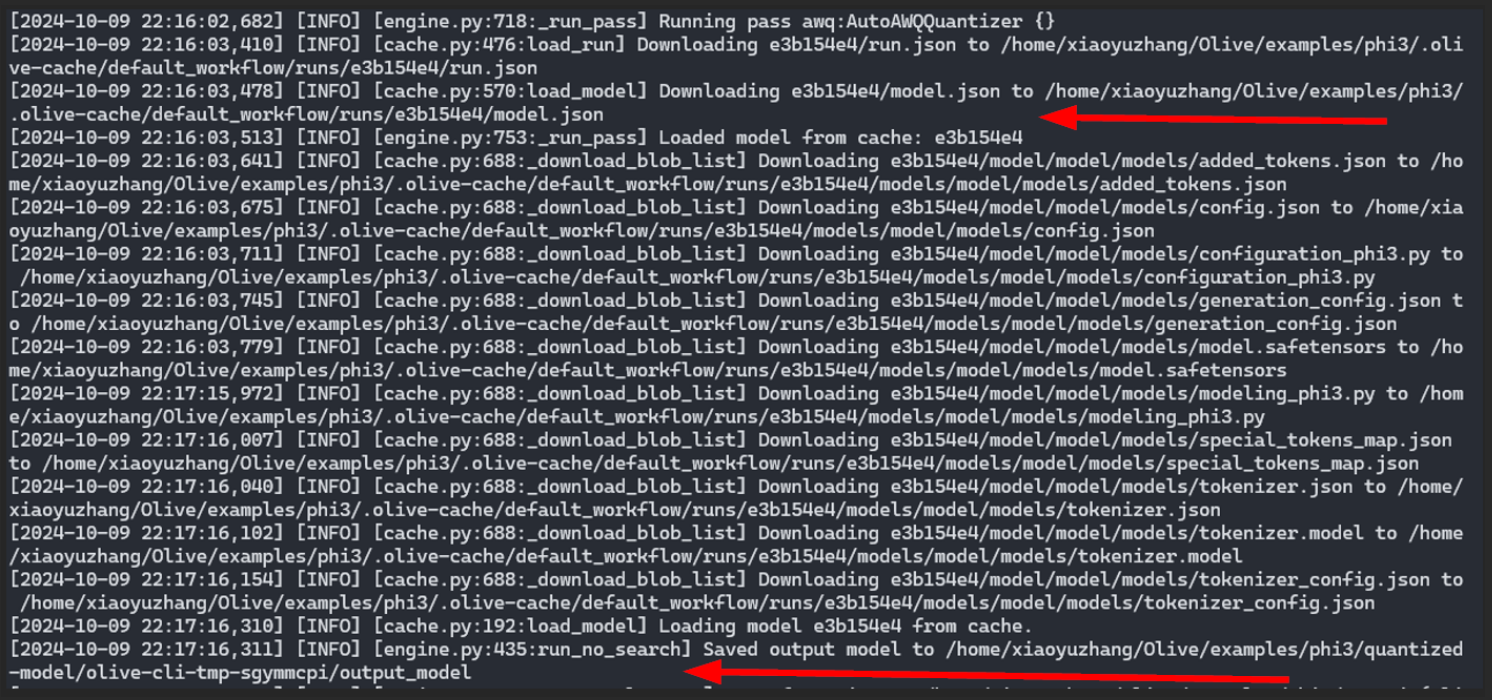 Olive-Protokollausgabe von Benutzer B: Das quantisierte Modell aus dem Workflow von Benutzer A wird heruntergeladen und im Workflow von Benutzer B verwendet, ohne dass es neu berechnet werden muss.
Olive-Protokollausgabe von Benutzer B: Das quantisierte Modell aus dem Workflow von Benutzer A wird heruntergeladen und im Workflow von Benutzer B verwendet, ohne dass es neu berechnet werden muss.Dieser Mechanismus spart nicht nur Rechenressourcen, sondern reduziert auch die für die Optimierung benötigte Zeit. Der Shared Cache in Azure dient als Repository für voroptimierte Modelle, die zur Wiederverwendung bereitstehen und somit die Effizienz steigern.
🪄 Shared Cache + Automatischer Optimierer
Die Optimierung beschränkt sich nicht nur auf die Quantisierung. Olives automatischer Optimierer erweitert seine Fähigkeiten, indem er weitere Vorverarbeitungs- und Optimierungsaufgaben in einem einzigen Befehl ausführt, um das beste Modell in Bezug auf Qualität und Leistung zu finden. Typische Optimierungsaufgaben, die im automatischen Optimierer ausgeführt werden, sind:
- Herunterladen des Modells von Hugging Face
- Erfassung der Modellstruktur in einem ONNX-Graphen und Konvertierung der Gewichte in ONNX-Format.
- Optimierung des ONNX-Graphen (z.B. Fusion, Kompression)
- Anwendung spezifischer Kernel-Optimierungen für die Zielhardware
- Quantisierung der Modellgewichte
Benutzer A nutzt den automatischen Optimierer, um Llama-3.2-1B-Instruct für die CPU zu optimieren. Die Befehlszeilenanweisung für diese Aufgabe lautet:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device cpu \
--provider CPUExecutionProvider \
--precision int4 \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
Für jede im automatischen Optimierer ausgeführte Aufgabe – z.B. Modelldownload, ONNX-Konvertierung, ONNX-Graph-Optimierung, Quantisierung usw. – wird das Zwischenmodell im Shared Cache gespeichert und kann für die Verwendung auf verschiedenen Hardwarezielen wiederverwendet werden. Wenn Benutzer B später dasselbe Modell für ein anderes Ziel (z.B. die GPU eines Windows-Geräts) optimieren möchte, würde er den folgenden Befehl ausführen:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device gpu \
--provider DmlExecutionProvider \
--precision int4 \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
Die gemeinsamen Zwischenschritte der CPU-Optimierung von Benutzer A – wie ONNX-Konvertierung und ONNX-Graph-Optimierung – werden wiederverwendet, was Benutzer B Zeit und Kosten spart.
Dies unterstreicht die Vielseitigkeit von Olive, nicht nur bei der Optimierung verschiedener Modelle, sondern auch bei der Anwendung einer Vielzahl von Algorithmen und Exportern. Der Shared Cache spielt erneut eine entscheidende Rolle, indem er diese optimierten Zwischenmodelle für die nachfolgende Verwendung speichert.
➕ Vorteile der Olive Shared Cache-Funktion
Die obigen Beispiele zeigen, dass die Olive Shared Cache-Funktion ein Wendepunkt in der Modelloptimierung ist. Hier sind die wichtigsten Vorteile:
- Zeiteffizienz: Durch die Speicherung optimierter Modelle entfällt die Notwendigkeit wiederholter Optimierungen, was den Zeitaufwand drastisch reduziert.
- Kostenreduzierung: Rechenressourcen sind teuer. Durch die Minimierung redundanter Prozesse reduziert der Shared Cache die damit verbundenen Kosten und macht maschinelles Lernen erschwinglicher.
- Ressourcenoptimierung: Die effiziente Nutzung der Rechenleistung führt zu einem besseren Ressourcenmanagement und stellt sicher, dass Ressourcen für andere kritische Aufgaben verfügbar sind.
- Zusammenarbeit: Der Shared Cache fördert ein kollaboratives Umfeld, in dem verschiedene Benutzer von den Optimierungsbemühungen anderer profitieren können, was den Wissensaustausch und die Teamarbeit fördert.
Schlussfolgerung
Durch das Speichern und Wiederverwenden optimierter Modelle ebnet die Olive Shared Cache-Funktion den Weg für ein effizienteres, kostengünstigeres und kollaborativeres Umfeld. Da KI weiter wächst und sich entwickelt, werden Werkzeuge wie Olive entscheidend für die Förderung von Innovation und Effizienz sein. Egal, ob Sie ein erfahrener Data Scientist oder ein Neuling in diesem Bereich sind, die Nutzung von Olive kann Ihren Workflow erheblich verbessern. Indem Sie den Zeit- und Kostenaufwand für die Modelloptimierung reduzieren, können Sie sich auf das konzentrieren, was wirklich zählt: die Entwicklung bahnbrechender KI-Modelle, die die Grenzen des Möglichen verschieben. Beginnen Sie noch heute Ihre Optimierungsreise mit Olive und erleben Sie die Zukunft der Effizienz im maschinellen Lernen.
⏭️ Probieren Sie Olive aus
Um die Befehle zur Quantisierung und zum automatischen Optimierer mit der Shared-Cache-Funktion auszuprobieren, führen Sie die folgende Pip-Installation aus:
pip install olive-ai[auto-opt,shared-cache] autoawqDie Quantisierung eines Modells mit dem AWQ-Algorithmus erfordert ein CUDA-GPU-Gerät. Wenn Sie nur Zugriff auf ein CPU-Gerät haben und kein Azure-Abonnement besitzen, können Sie den automatischen Optimierer mit einer CPU ausführen und die lokale Festplatte als Cache verwenden.
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device cpu \
--provider CPUExecutionProvider \
--precision int4 \
--log_level 1