Beschleunigung von Phi-2, CodeLlama, Gemma und anderen Gen AI-Modellen mit ONNX Runtime
Von
Parinita Rahi, Sunghoon Choi, Yufeng Li, Kshama Pawar, Ashwini Khade, Ye Wang26. FEBRUAR 2024
In einer sich schnell entwickelnden Landschaft, in der Geschwindigkeit und Effizienz an erster Stelle stehen, ermöglicht ONNX Runtime (ORT) den Benutzern, die Leistung generativer KI-Modelle einfach in ihre Apps und Dienste zu integrieren, mit verbesserten Optimierungen, die schnellere Inferenzgeschwindigkeiten erzielen und effektiv Kosten senken. Dazu gehören modernste Fusions- und Kernel-Optimierungen zur Verbesserung der Modellleistung. Die kürzlich veröffentlichte Version ONNX Runtime 1.17 verbessert die Inferenzleistung mehrerer Gen AI-Modelle, darunter Phi-2, Mistral, CodeLlama, Orca-2 und mehr. ONNX Runtime ist eine komplette Lösung für kleine Sprachmodelle (SLMs) vom Training bis zur Inferenz und zeigt im Vergleich zu anderen Frameworks deutliche Geschwindigkeitssteigerungen. Mit Unterstützung für Float32, Float16 und Int4 bieten die Inferenzverbesserungen von ONNX Runtime maximale Flexibilität und Leistung.
In diesem Blog behandeln wir signifikante Optimierungssteigerungen sowohl für das Training als auch für die Inferenz für die neuesten GenAI-Modelle wie Phi-2, Mistral, CodeLlama, SD-Turbo, SDXL-Turbo, Llama2 und Orca-2. Für diese Modellarchitekturen verbessert ONNX Runtime die Leistung über ein Spektrum von Batch-Größen und Prompt-Längen hinweg erheblich im Vergleich zu anderen Frameworks wie PyTorch und Llama.cpp. Diese Optimierungen mit ONNX Runtime sind jetzt auch über Olive verfügbar.
Schnelllinks
Phi-2
Phi-2 ist ein 2,7 Milliarden Parameter starkes Transformer-Modell, das von Microsoft entwickelt wurde. Es ist ein SLM, das hervorragende Fähigkeiten in den Bereichen Schlussfolgern und Sprachverständnis aufweist. Mit seiner geringen Größe ist Phi-2 eine großartige Plattform für Forscher, die verschiedene Aspekte wie mechanistische Interpretierbarkeit, Sicherheitsverbesserungen und Feinabstimmungsversuche für verschiedene Aufgaben untersuchen können.
ONNX Runtime 1.17 führt Kernel-Änderungen ein, die das Phi-2-Modell unterstützen, einschließlich Optimierungen für Attention, Multi-Head Attention, Grouped-Query Attention und RotaryEmbedding für Phi-2. Insbesondere wurde die Unterstützung für Folgendes hinzugefügt:
- Kausale Maske im Multi-Head Attention CPU-Kernel
- rotary_embedding_dim in den Attention- und Rotary-Embedding-Kernels
- bfloat16 im Grouped-Query Attention Kernel
Die TorchDynamo-basierte ONNX-Exportierung für Phi-2 wird unterstützt, und das Optimierungsskript baut darauf auf.
Für die Phi-2-Inferenz schneidet ORT mit Float16- und Int4-Quantisierung bei allen Prompt-Längen besser ab als ORT mit Float32, PyTorch und Llama.cpp.
Inferenz
ORT-Vorteile mit Float16
Die optimierte CUDA-Leistung für den Prompt-Durchsatz (d. h. die Rate, mit der das Modell Antworten basierend auf Eingabeaufforderungen verarbeitet und generiert) ist **bis zu 7,39x** schneller als PyTorch Compile. Wir beobachten auch, dass ONNX Runtime bei größerer Batch-Größe und längeren Prompt-Längen deutlich schneller ist als Llama.cpp. Zum Beispiel ist es **bis zu 13,08x schneller** für Batch-Größe = 16, Prompt-Länge = 2048.
Der Durchsatz bei der Token-Generierung ist der durchschnittliche Durchsatz der ersten 256 generierten Token. ONNX Runtime mit Float16 ist **durchschnittlich 6,6x schneller** als torch.compile und **bis zu 18,55x** schneller. Es ist auch **bis zu 1,64x** schneller als Llama.cpp.

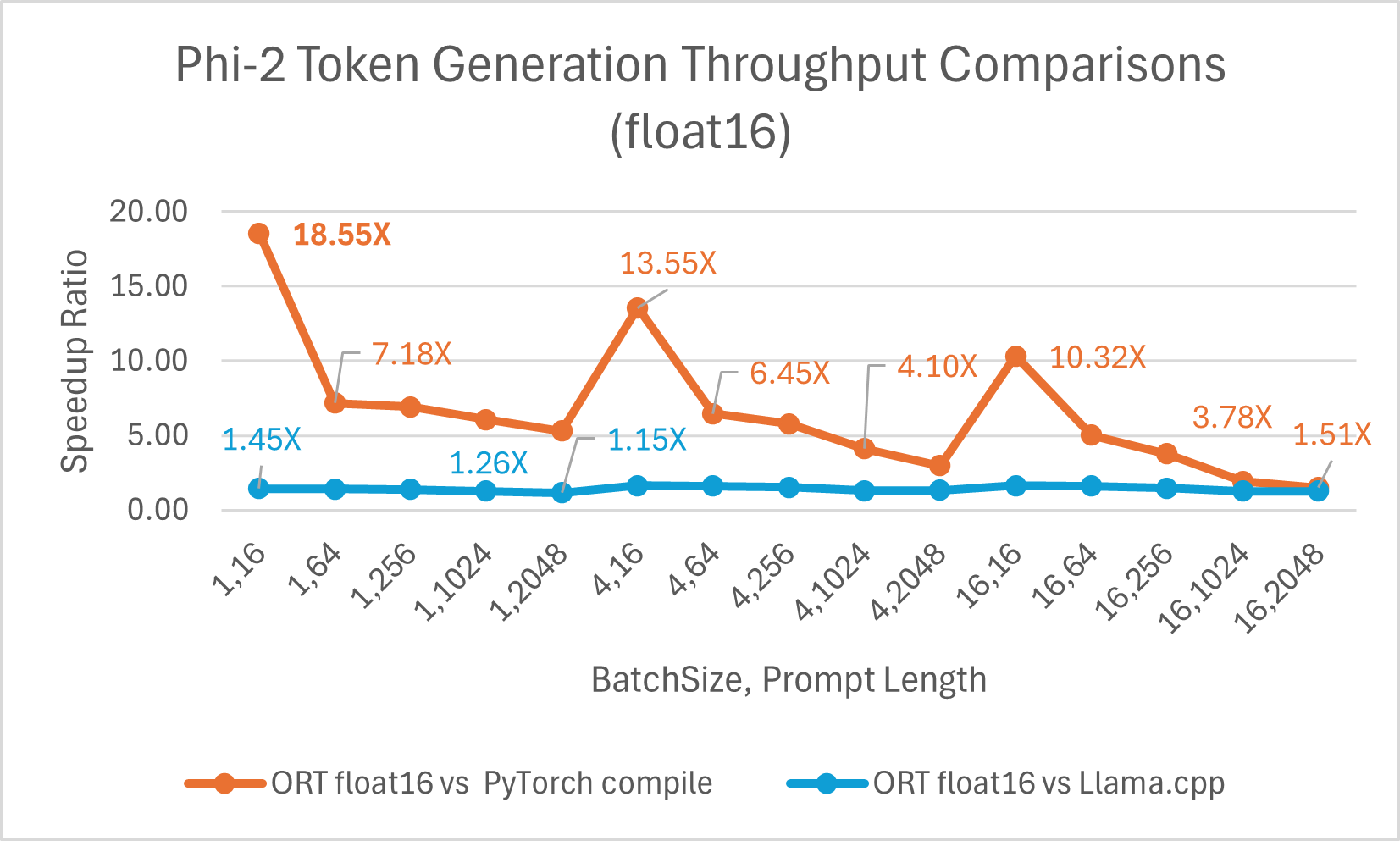
ORT-Vorteile mit Int4
ORT bietet Unterstützung für Int4-Quantisierung. ORT mit Int4-Quantisierung kann eine **bis zu 20,48x** verbesserte Leistung im Vergleich zu PyTorch bieten. Es ist durchschnittlich 3,9x besser als Llama.cpp und **bis zu 13,42x** schneller für große Sequenzlängen. ONNX Runtime mit Int4-Quantisierung schneidet typischerweise mit Batch-Größe 1 am besten ab, da es einen speziellen Kernel für GemV verwendet.
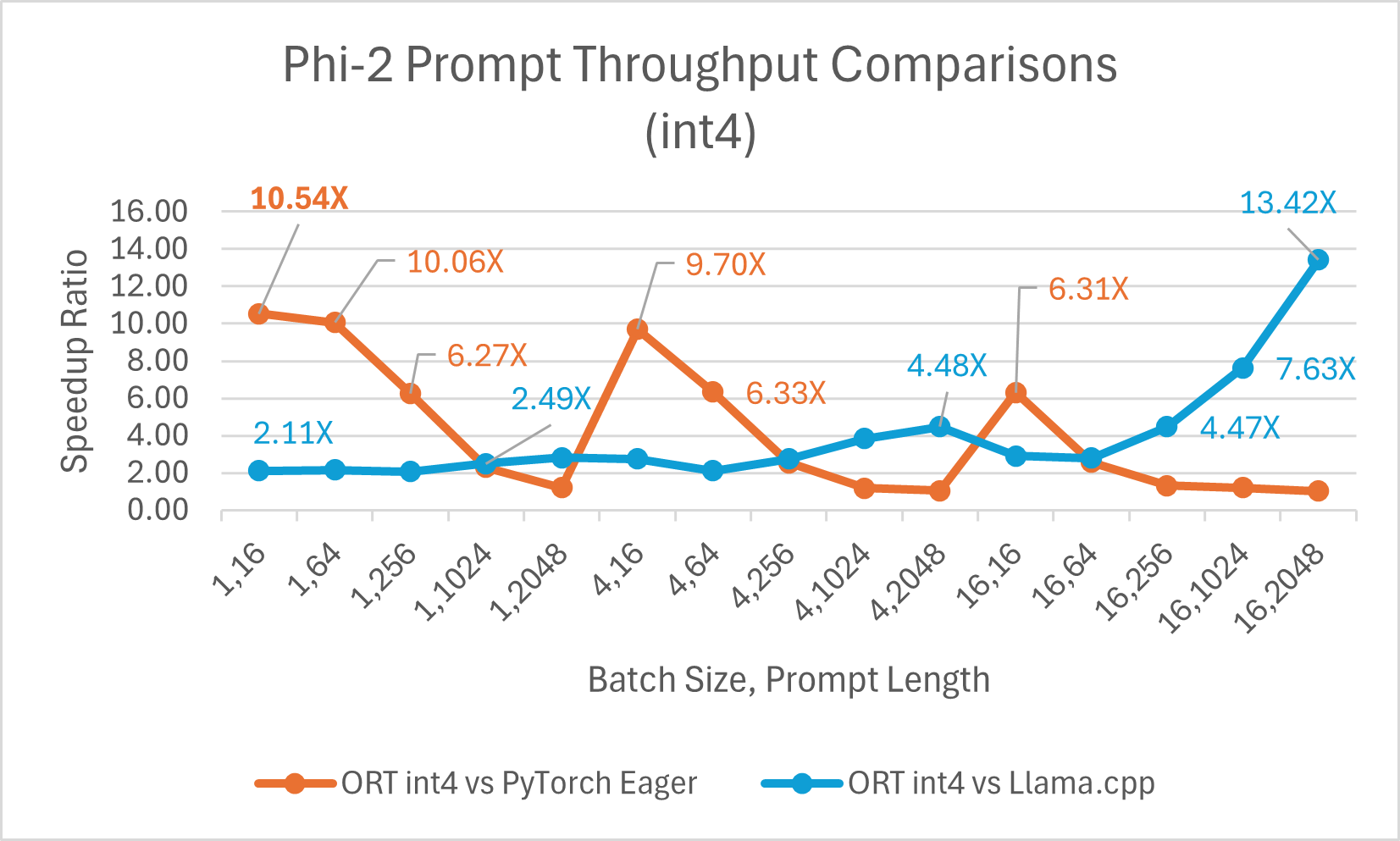
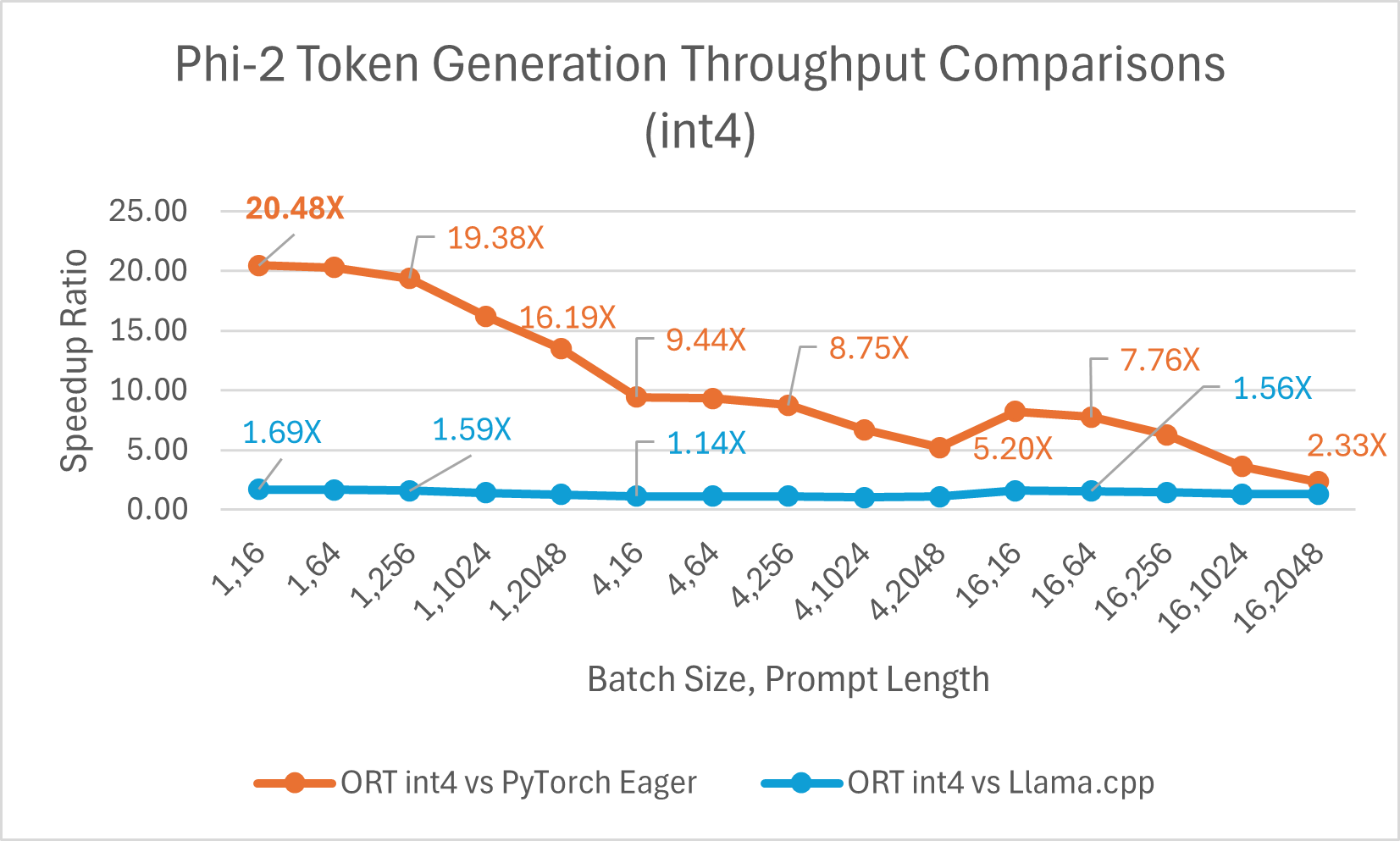
- Phi-2-Benchmarks wurden auf 1 A100 GPU (SKU: Standard_ND96amsr_A100_v4) durchgeführt. Pakete: torch: 2.3.0. dev20231221+cu121; pytorch-triton: 2.2.0+e28a256d71; ort-nightly-gpu: 1.17.0.dev20240118001; deepspeed: 0.12
- Batch ist eine Menge von Eingabesätzen unterschiedlicher Länge; Prompt-Länge bezieht sich auf die Größe oder Länge des Eingabetextes.
Hier ist ein Beispiel für Phi-2-Optimierungen mit Olive, das die in diesem Blog hervorgehobenen ONNX Runtime-Optimierungen mit dem einfach zu bedienenden, hardwaregesteuerten Modelloptimierungstool Olive nutzt.
Training
Zusätzlich zur Inferenz bietet ONNX Runtime auch Trainingsbeschleunigung für Phi-2 und andere LLMs. ORT-Training ist Teil des PyTorch-Ökosystems und über das torch-ort Python-Paket als Teil des Azure Container for PyTorch (ACPT) verfügbar. Es bietet flexible und erweiterbare Hardware-Unterstützung, bei der dasselbe Modell und dieselben APIs sowohl mit NVIDIA- als auch mit AMD-GPUs funktionieren. ORT beschleunigt das Training durch optimierte Kernel und Speicheroptimierungen, die deutliche Gewinne bei der Reduzierung der End-to-End-Trainingszeit für das Training großer Modelle zeigen. Dies beinhaltet die Änderung weniger Codezeilen im Modell, um es mit der ORTModule-API zu umhüllen. Es ist auch mit beliebten Beschleunigungsbibliotheken wie DeepSpeed und Megatron für schnelleres und effizienteres Training kombinierbar.
Open AI's Triton ist eine domänenspezifische Sprache und ein Compiler zum Schreiben hocheffizienter benutzerdefinierter Deep-Learning-Primitive. ORT unterstützt die Integration von Open AI Triton (ORT+Triton), bei der alle elementweisen Operatoren in Triton-Ops konvertiert werden und ORT benutzerdefinierte, fusionierte Kernel in Triton erstellt.
ORT führt auch Sparsity-Optimierungen durch, um die Sparsität der Eingabedaten zu bewerten und daraus abgeleitete Graph-Optimierungen durchzuführen. Dies reduziert den Rechenaufwand und erhöht die Leistung.
Low-Rank Adapters (LoRA) basierte Feinabstimmung macht das Training effizienter, indem nur eine kleine Anzahl zusätzlicher Parameter (die Adapter) trainiert wird, während die Gewichte des ursprünglichen Modells eingefroren werden. Diese Adapter passen das Modell an spezifische Aufgaben an. Quantization und LoRA (QLoRA) kombiniert Quantisierung mit LoRA, bei der die Gewichte mit weniger Bits dargestellt werden, während die Leistung und Qualität des Modells erhalten bleiben. ONNX Runtime Training komponiert mit LoRA und QLoRA, um Vorteile bei der Speichereffizienz und Beschleunigung der Trainingszeit für LLMs zu erzielen. LoRA- und QLoRA-Techniken ermöglichen es sehr großen Modellen wie LLMs, in den GPU-Speicher zu passen, um das Training effizient abzuschließen.
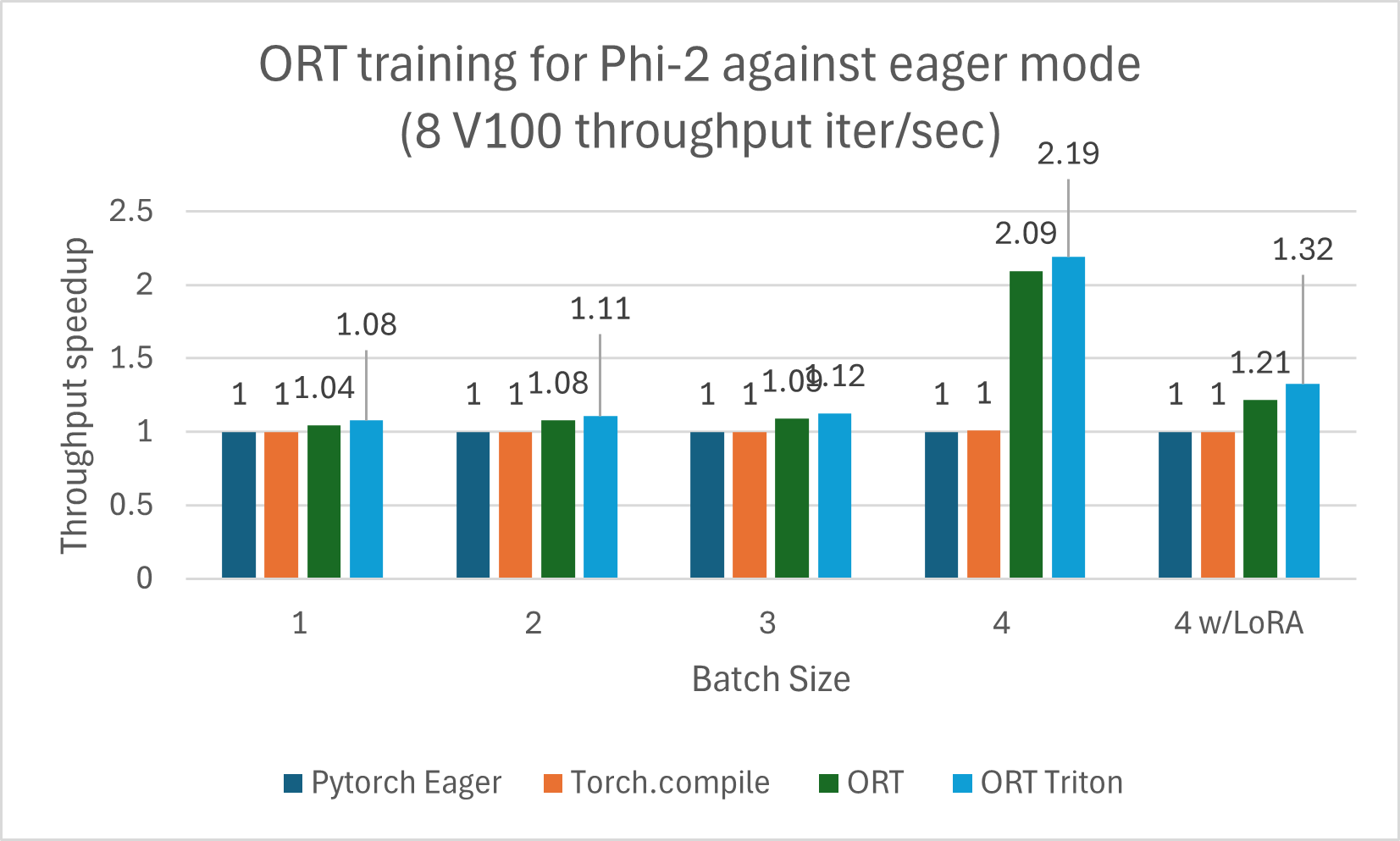
Das mit ORT trainierte Phi-2-Modell zeigt Leistungsgewinne gegenüber PyTorch Eager-Modus und torch.compile. Phi-2 wurde mit einer Mischung aus synthetischen und Web-Datensätzen trainiert. Wir haben Gewinne gegen ORT und den ORT+Triton-Modus gemessen, und die Gewinne nahmen mit größeren Batch-Größen zu. Das Modell wurde 5 Epochen lang mit DeepSpeed Stage-2 trainiert, mit zunehmenden Batch-Größen auf dem wikitext-Datensatz. Die Gewinne sind in den folgenden Diagrammen für V100 und A100 zusammengefasst.
Die Trainings-Benchmarks wurden auf 8 V100 durchgeführt und der Durchsatz wurde in Iterationen/Sekunde gemessen (höher ist besser).
Die nachfolgenden Trainings-Benchmarks wurden auf 2 A100 durchgeführt und der Durchsatz wurde in Iterationen/Sekunde gemessen (höher ist besser).
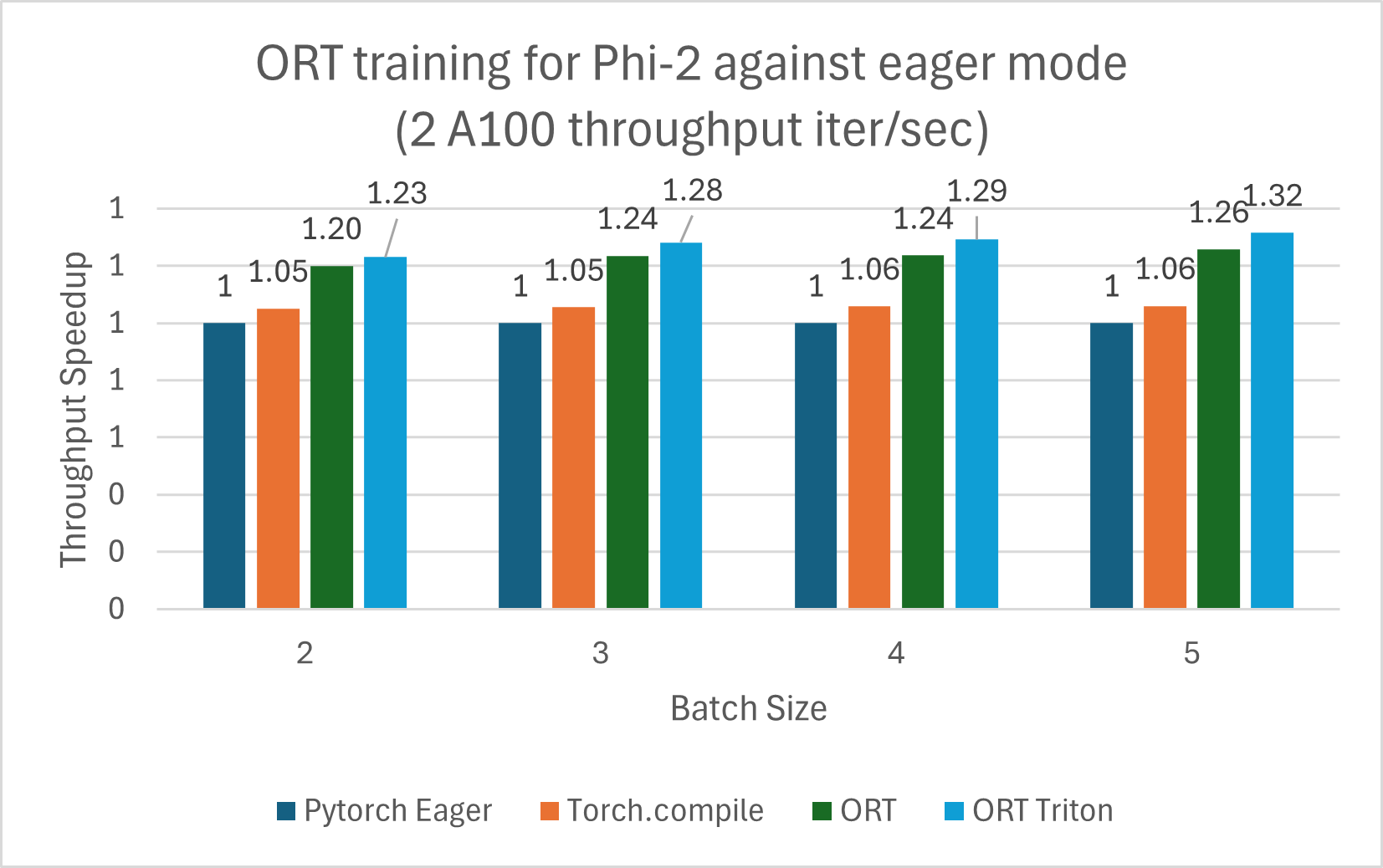 Hinweis: Es wurden die Versionen PyTorch Stable 2.2.0 und ONNXRuntime Training: Stable 1.17.0 verwendet.
Hinweis: Es wurden die Versionen PyTorch Stable 2.2.0 und ONNXRuntime Training: Stable 1.17.0 verwendet. Mistral
Inferenz
Mistral7B ist ein vortrainiertes generatives Text-LLM mit 7 Milliarden Parametern. ONNX Runtime verbessert die Inferenzleistung für Mistral mit Float16- und Int4-Modellen erheblich. Mit Float16 ist ONNX Runtime **bis zu 9,46x** schneller als Llama.cpp. Der Durchsatz bei der Token-Generierung verbessert sich mit Int4-Quantisierung für Batch-Größe 1 erheblich und ist **bis zu 18,25x** schneller als PyTorch Eager.
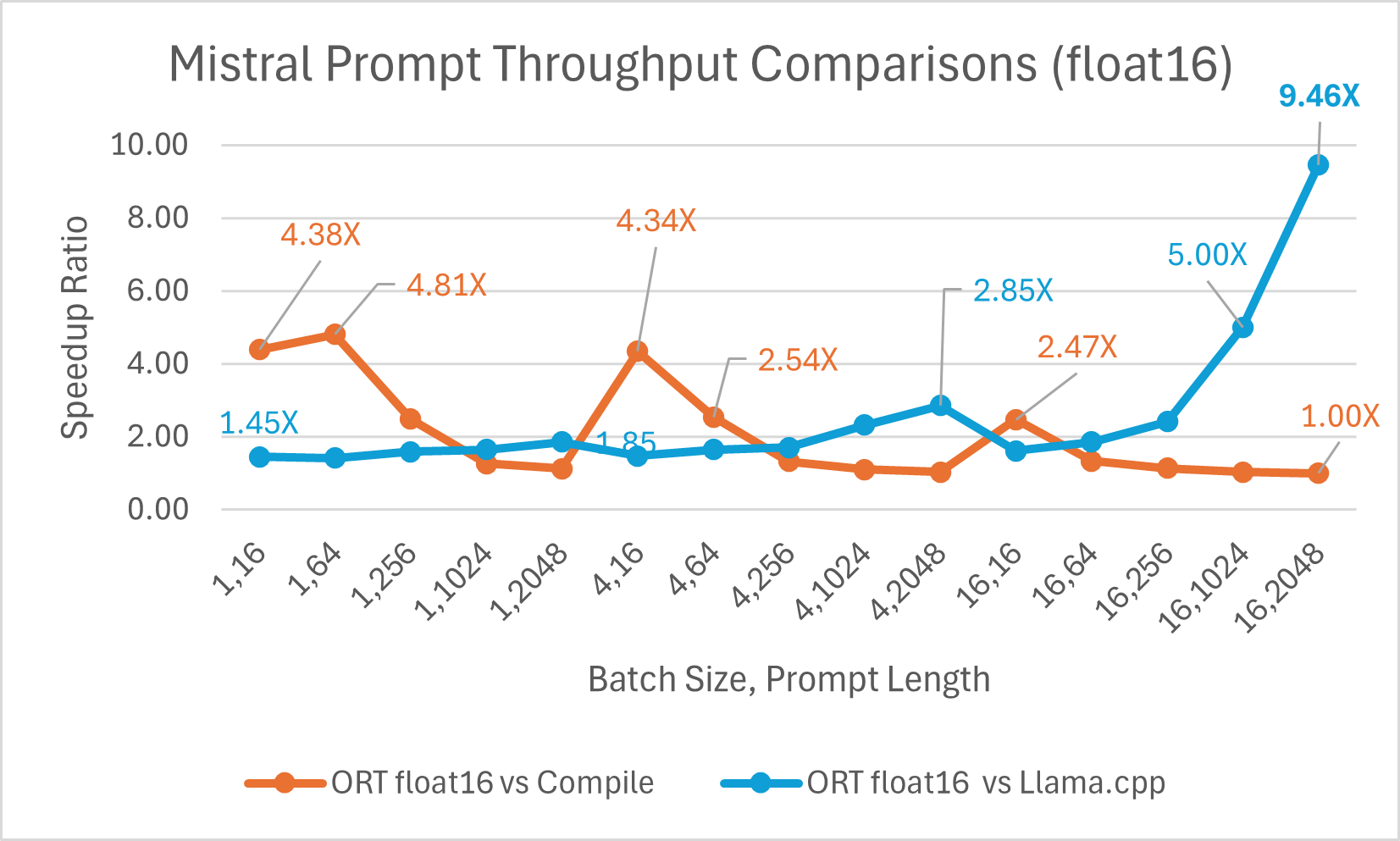
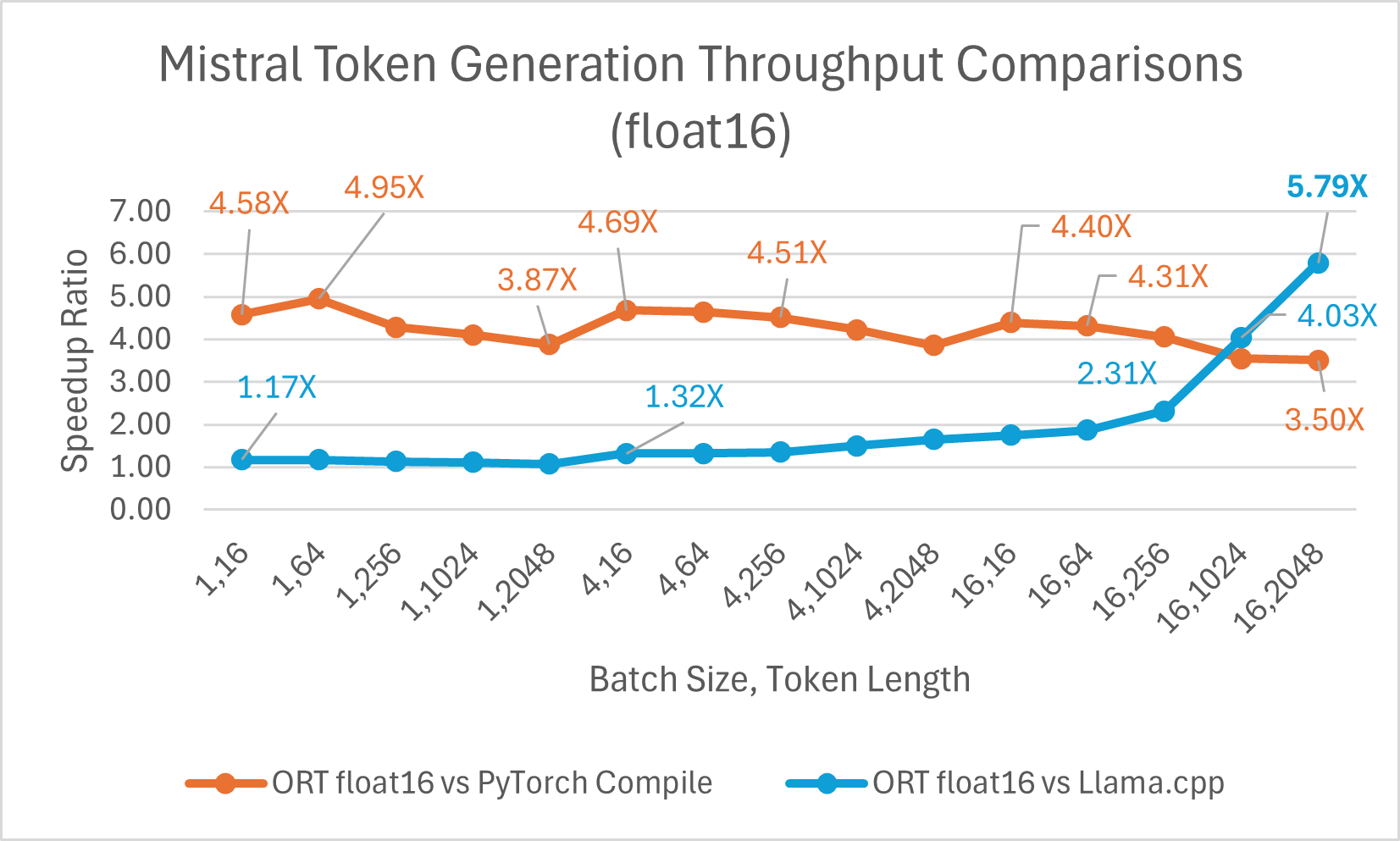

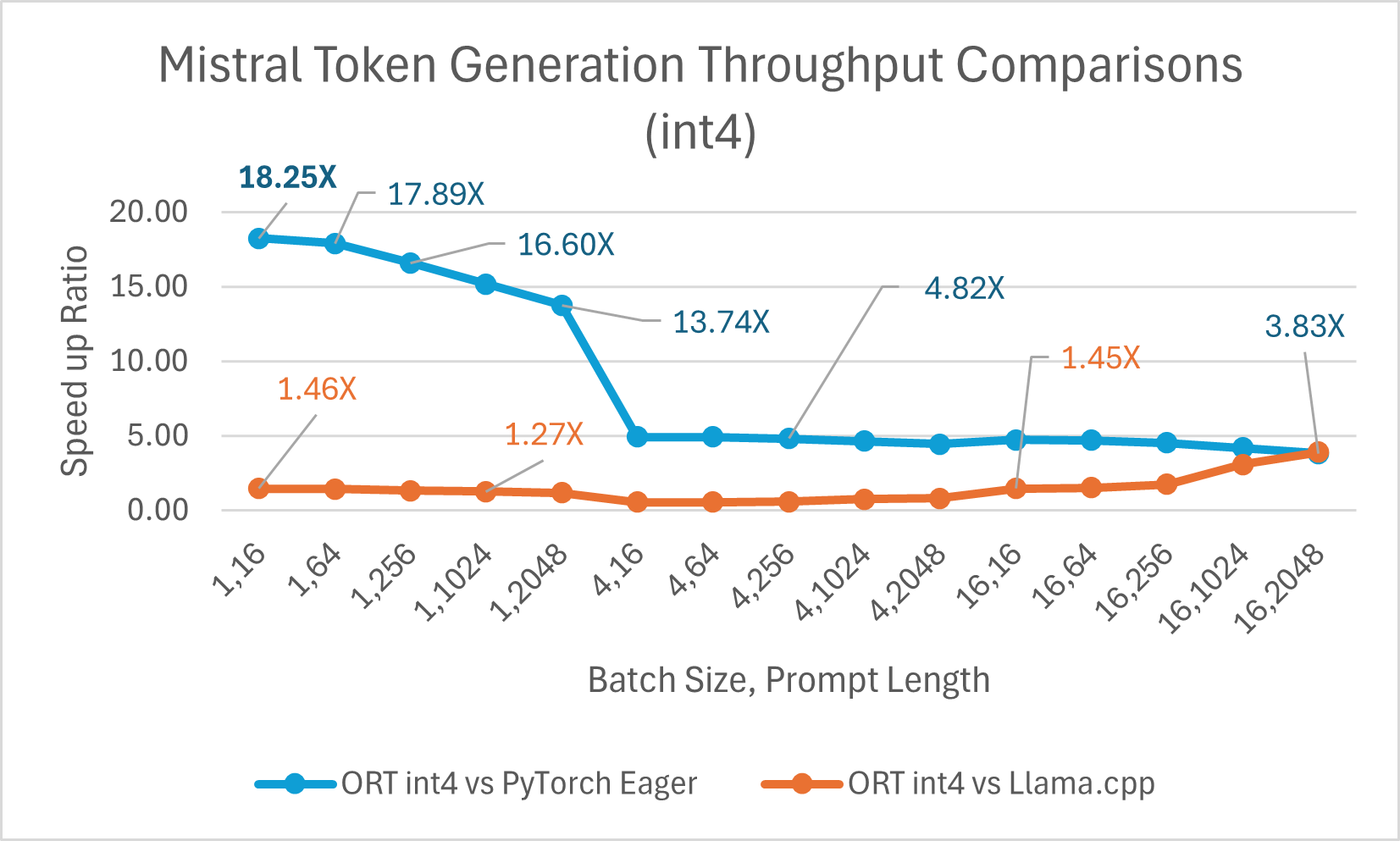
Sie können jetzt auf das optimierte Mistral-Modell auf Huggingface hier zugreifen.
Training
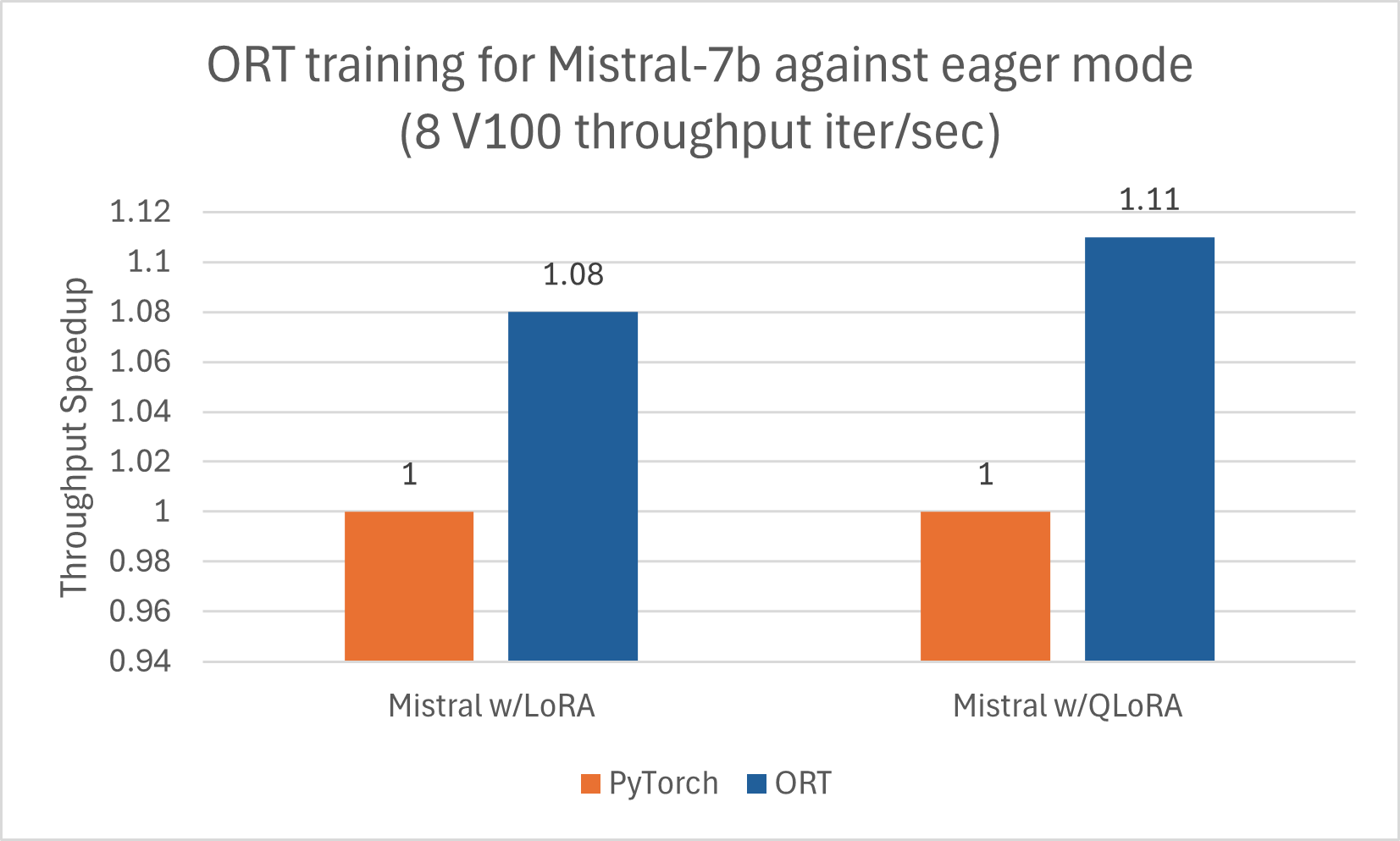
Ähnlich wie Phi-2 profitiert auch Mistral von der Trainingsbeschleunigung durch ORT. Wir haben Mistral-7B mit der folgenden Konfiguration trainiert, um Gewinne mit ORT zu erzielen, einschließlich bei Kombination mit LoRA und QLoRA. Das Modell wurde 5 Epochen lang mit DeepSpeed Stage-2 mit Batch-Größe 1 auf dem wikitext-Datensatz trainiert.
CodeLlama
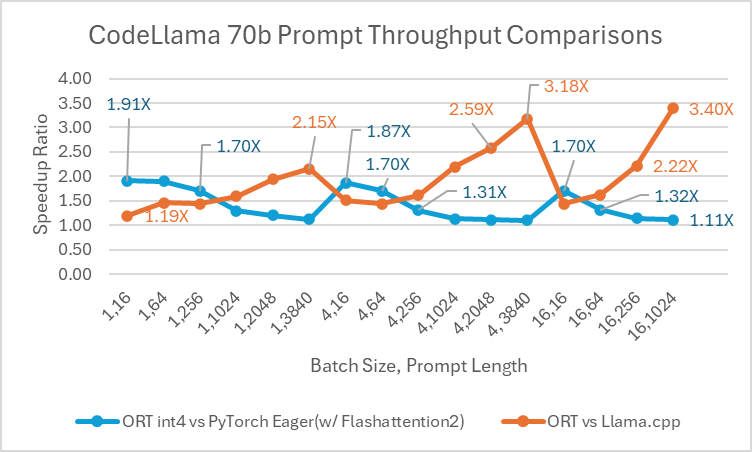
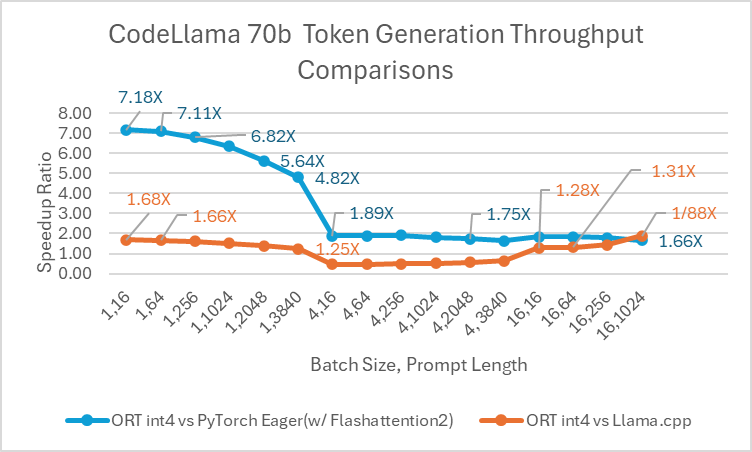
Codellama-70B ist ein auf Programmierung fokussiertes Modell, das auf der Llama-2-Plattform basiert. Dieses Modell kann Code produzieren und Diskussionen über Code in natürlicher Sprache generieren. Da CodeLlama-70B ein feinabgestimmtes Llama-Modell ist, können bestehende Optimierungen direkt angewendet werden. Wir verglichen ein 4-Bit-quantisiertes ONNX-Modell mit PyTorch Eager und Llama.cpp. Für den Prompt-Durchsatz ist ONNX Runtime **mindestens 1,4x schneller** als PyTorch Eager für alle Batch-Größen. ONNX Runtime produziert Token mit einer durchschnittlichen Geschwindigkeit, die **3,4x** höher ist als bei PyTorch Eager für jede Batch-Größe und **1,5x** höher als bei Llama.cpp für Batch-Größe 1.
SD-Turbo und SDXL-Turbo
ONNX Runtime bietet Inferenzleistungs-Vorteile, wenn es mit SD Turbo und SDXL Turbo verwendet wird, und macht die Modelle auch in anderen Sprachen als Python zugänglich, wie z. B. C# und Java. ONNX Runtime erreichte einen höheren Durchsatz als PyTorch für alle ausgewerteten Kombinationen von (Batch-Größe, Anzahl der Schritte), mit Durchsatzverbesserungen von **bis zu 229 %** für das SDXL Turbo-Modell und **120 %** für das SD Turbo-Modell. ONNX Runtime CUDA ist besonders gut im Umgang mit dynamischer Form, zeigt aber auch einen signifikanten Vorteil gegenüber PyTorch für statische Form.

Um mehr über die Beschleunigung der SD-Turbo- und SDXL-Turbo-Inferenz mit ONNX Runtime zu erfahren, lesen Sie unseren aktuellen Blog mit Hugging Face.
Llama-2
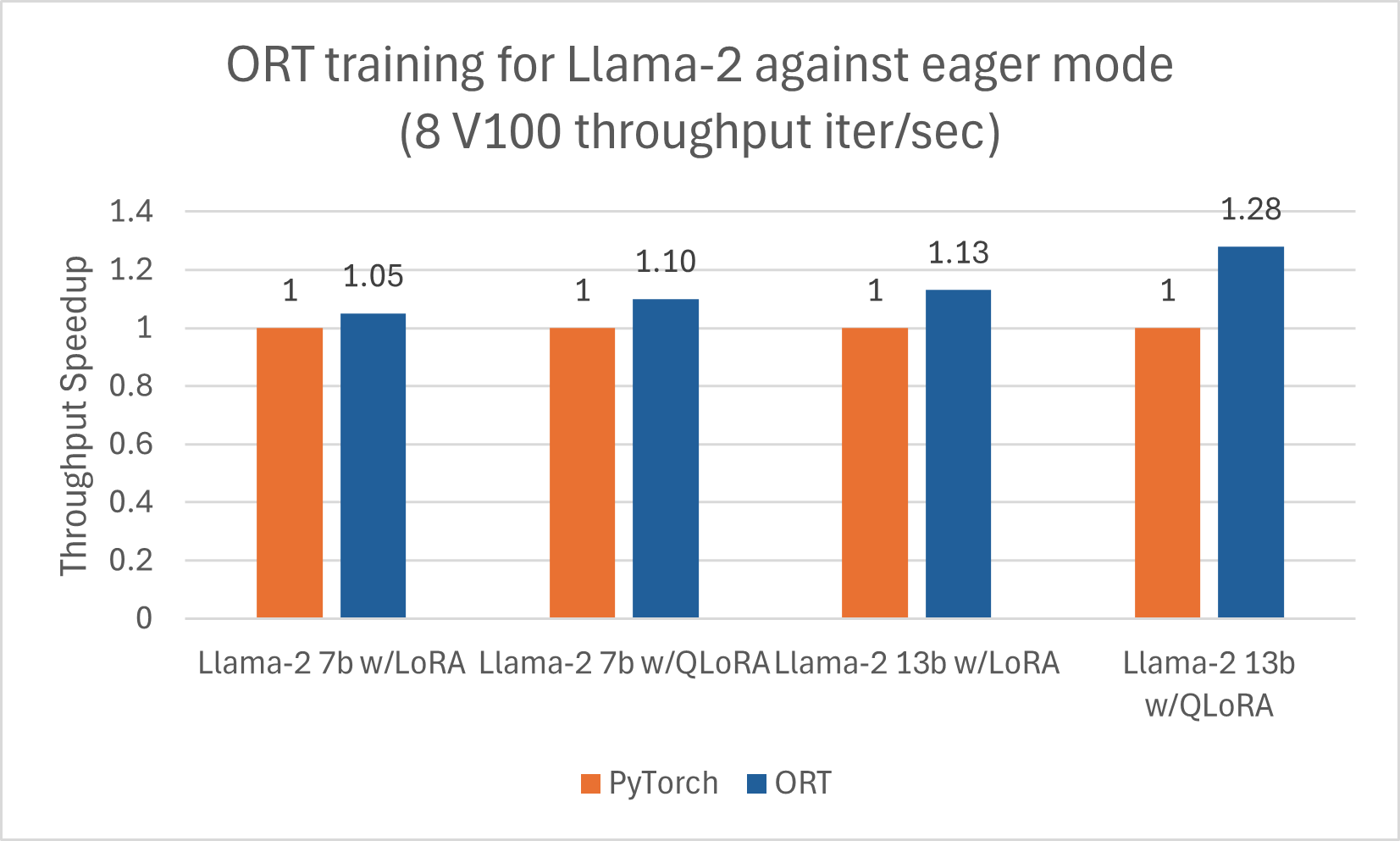
Wir haben einen separaten Blog über Llama-2-Verbesserungen mit ORT für die Inferenz hier veröffentlicht. Zusätzlich zeigen Llama-2-7B und Llama-2-13B gute Fortschritte mit ORT für das Training, insbesondere in Kombination mit LoRA und QLoRA. Diese Skripte können als Beispiel verwendet werden, um Llama-2 mit ORT unter Verwendung von Optimum feinabzustimmen. Die unten aufgeführten Zahlen beziehen sich auf das Training von Llama-2-Modellen mit ORT unter Verwendung von DeepSpeed Stage-2 für 5 Epochen mit Batch-Größe 1 auf dem wikitext-Datensatz.
Orca-2
Inferenz
Orca-2 ist ein reines Forschungssystem, das einmalige Antworten auf Aufgaben wie Schlussfolgerungen mit benutzerdefinierten Daten, Textverständnis, Lösen von Mathematikproblemen und Textzusammenfassung liefert. Orca-2 gibt es in zwei Versionen (7 Milliarden und 13 Milliarden Parameter); beide wurden durch Feinabstimmung der jeweiligen Llama-2-Basismodelle auf benutzerdefinierten, hochwertigen künstlichen Daten erstellt. ONNX Runtime hilft bei der Optimierung der Orca-2-Inferenz durch Graph-Fusionen und Kernel-Optimierungen wie die für Llama-2.
ORT-Vorteile mit Int4
Ein Vergleich der Orca-2-7B Int4-Quantisierungsleistung zeigte eine **bis zu 26X** Leistungssteigerung beim Prompt-Durchsatz und eine **bis zu 16,5X** Verbesserung beim Token-Generierungsdurchsatz gegenüber PyTorch. Es zeigt auch eine **über 4,75X** Verbesserung beim Prompt-Durchsatz und eine **3,64X** Verbesserung beim Token-Generierungsdurchsatz im Vergleich zu Llama.cpp.
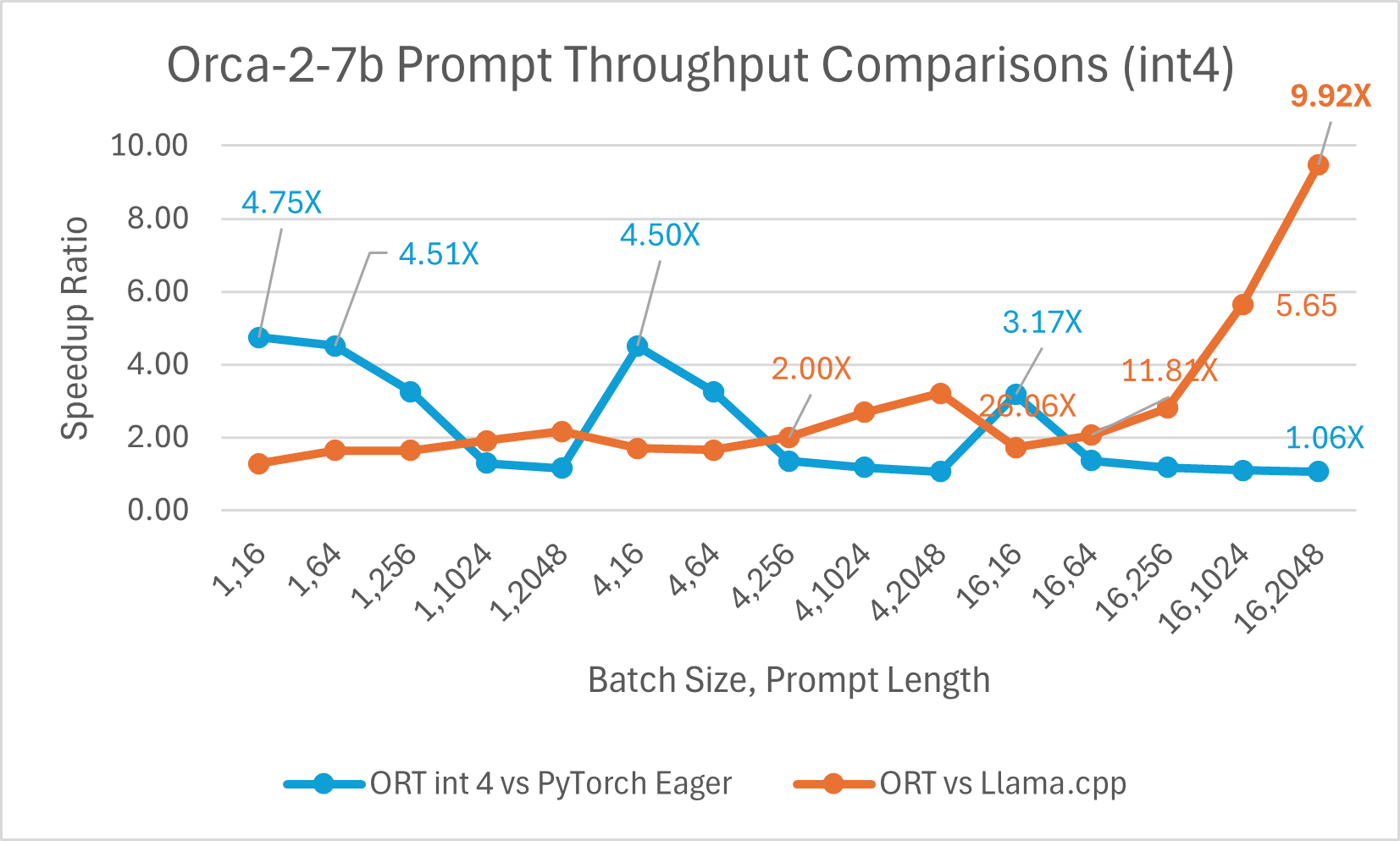
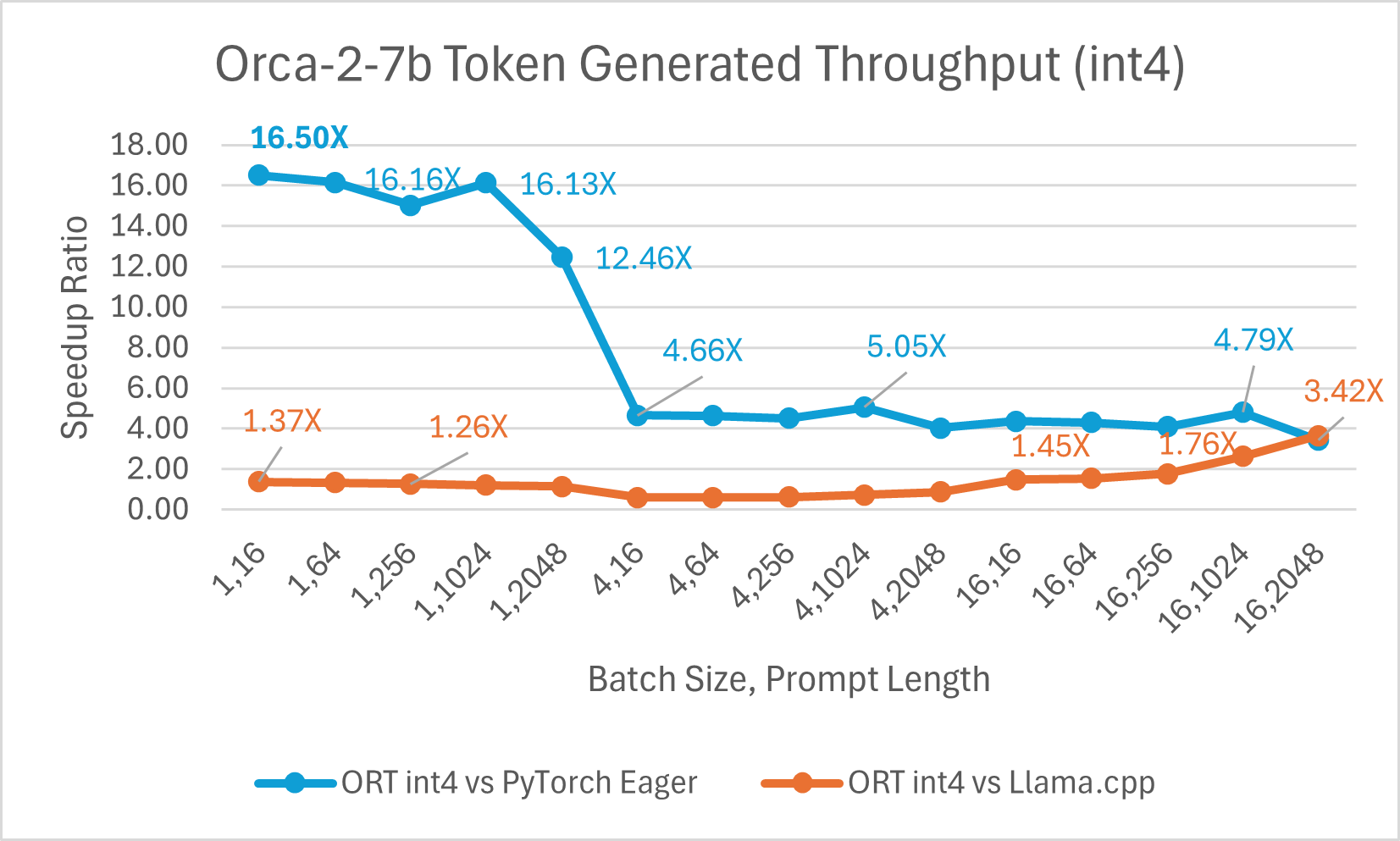

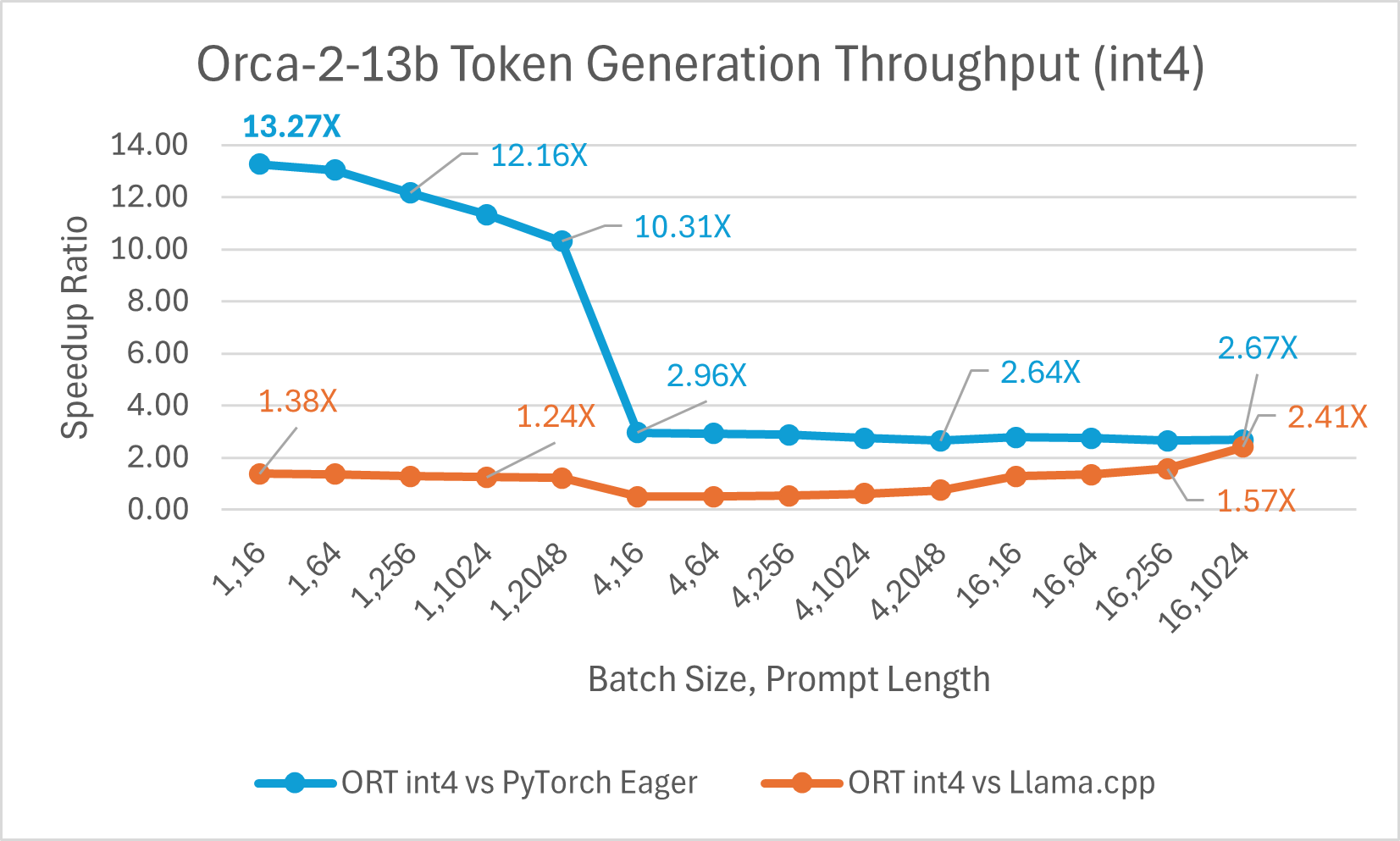
Der Vergleich der Orca-2 7b mit ONNX Runtime Float16-Leistung zeigt ebenfalls signifikante Gewinne beim Prompt- und Token-Generierungsdurchsatz.
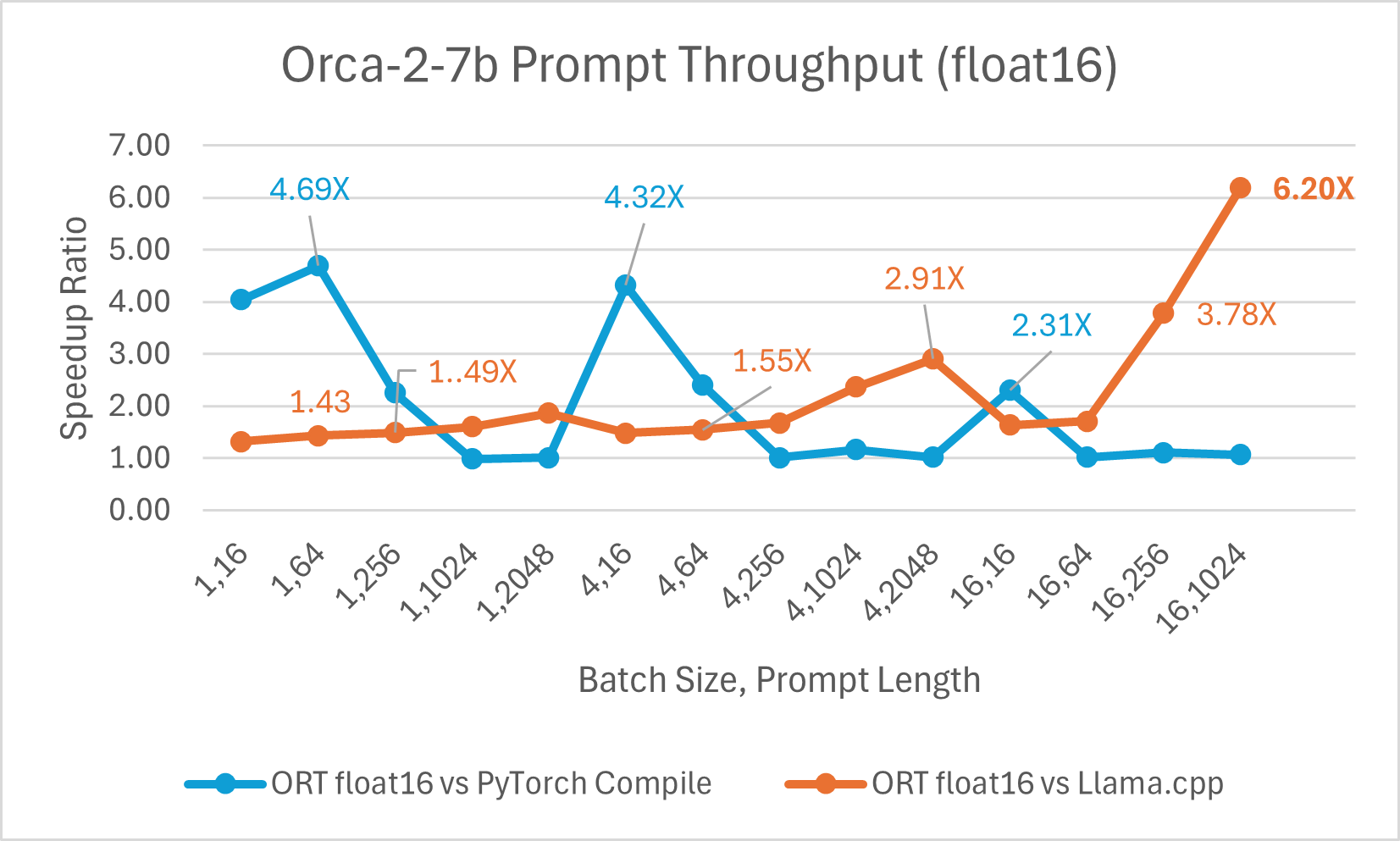
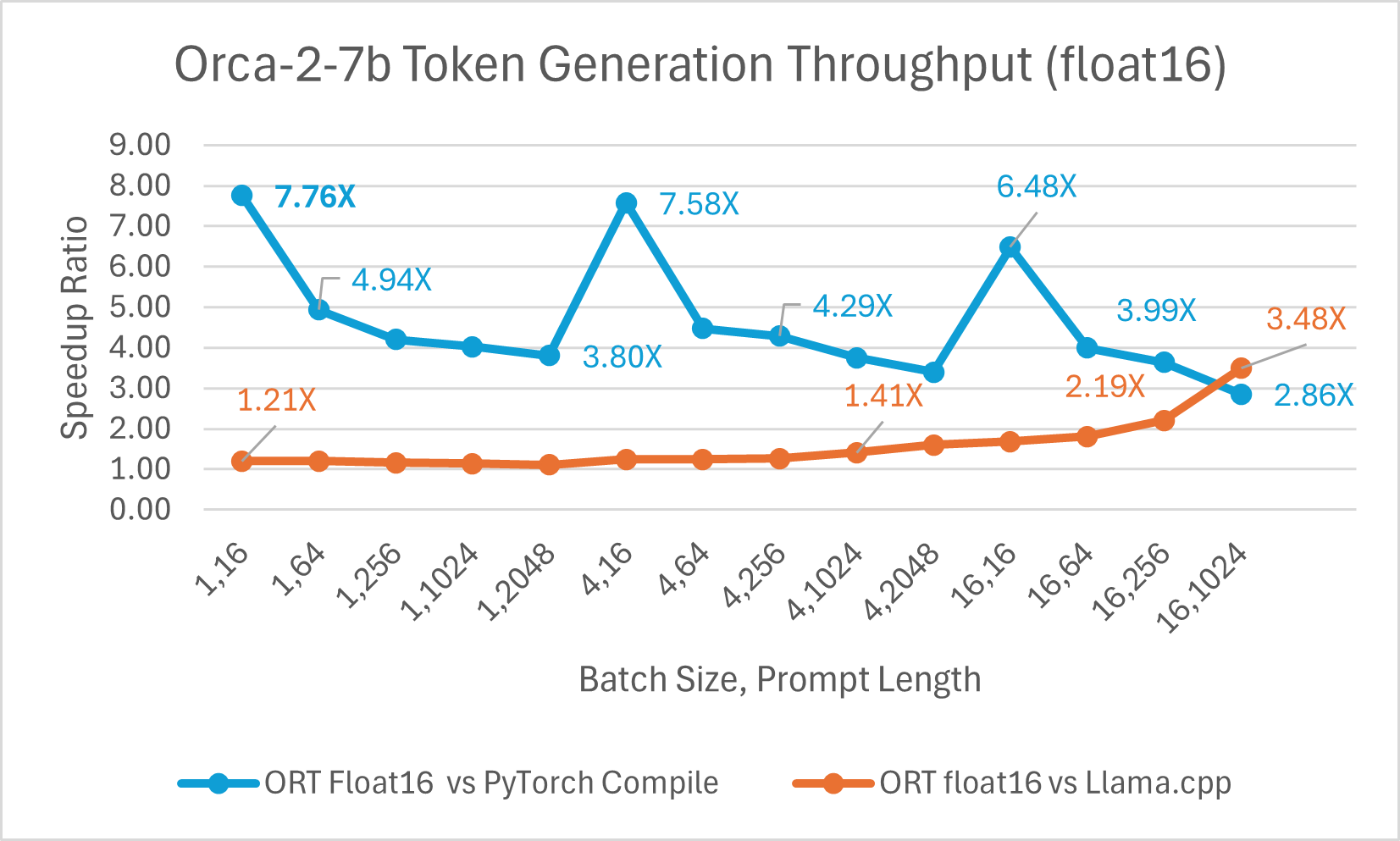
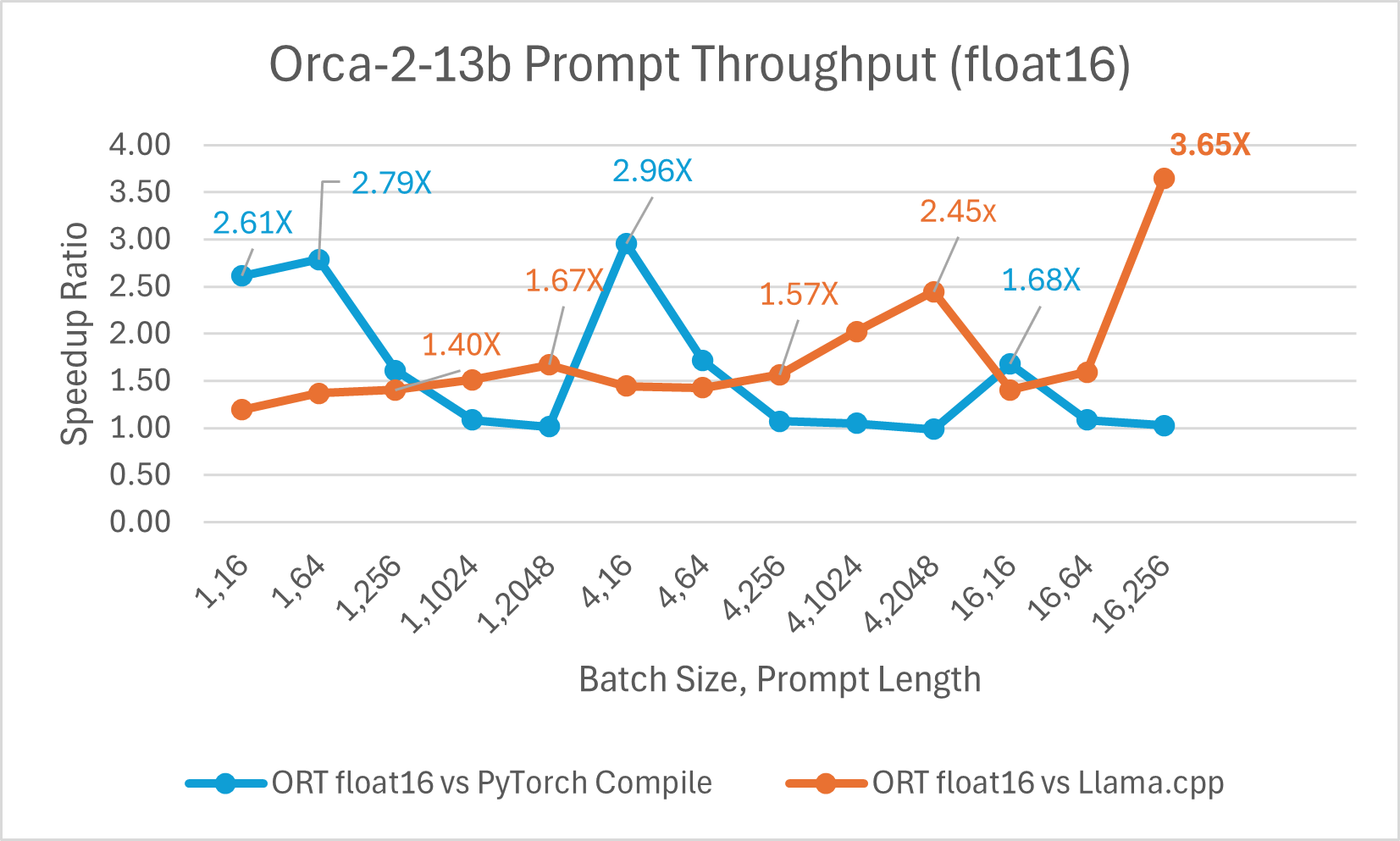
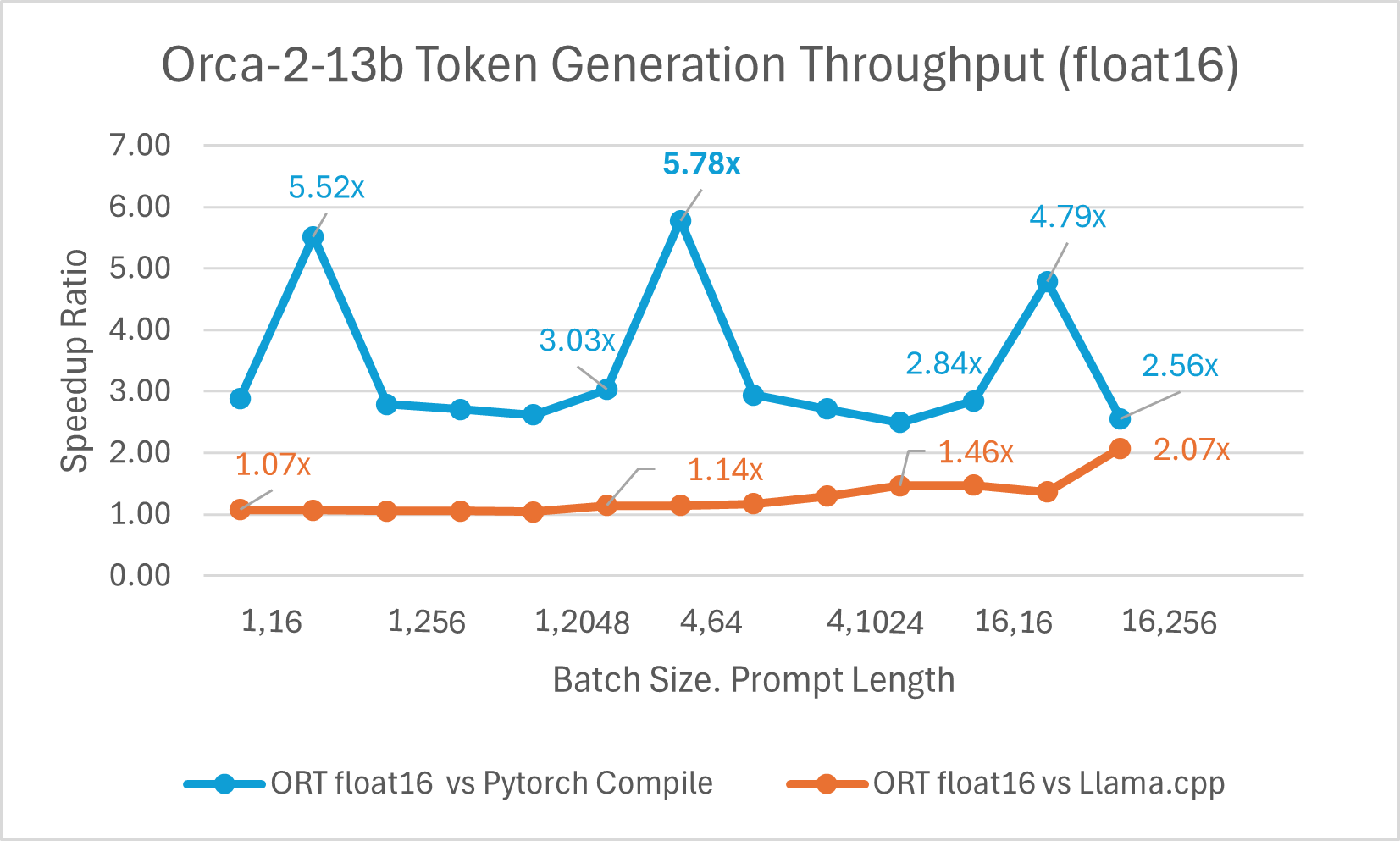
Orca-2-Benchmarks wurden auf 1 A100 GPU, SKU: Standard_ND96amsr_A100_v4, durchgeführt. Pakete: torch 2.2.0, triton 2.2.0, onnxruntime-gpu 1.17.0, deepspeed 0.13.2, llama.cpp - commit 594fca3fefe27b8e95cfb1656eb0e160ad15a793, transformers 4.37.2
Training
Orca-2-7B profitiert auch von der Trainingsbeschleunigung durch ORT. Wir haben das Orca-2-7B-Modell für eine Sequenzlänge von 512 mit LoRA und aktivierter Sparsity-Optimierung trainiert und gute Leistungsgewinne erzielt. Die unten aufgeführten Zahlen beziehen sich auf Orca-2-7B-Modelle, die mit ORT unter Verwendung von DeepSpeed Stage-2 für 5 Epochen mit Batch-Größe 1 auf dem wikitext-Datensatz trainiert wurden.
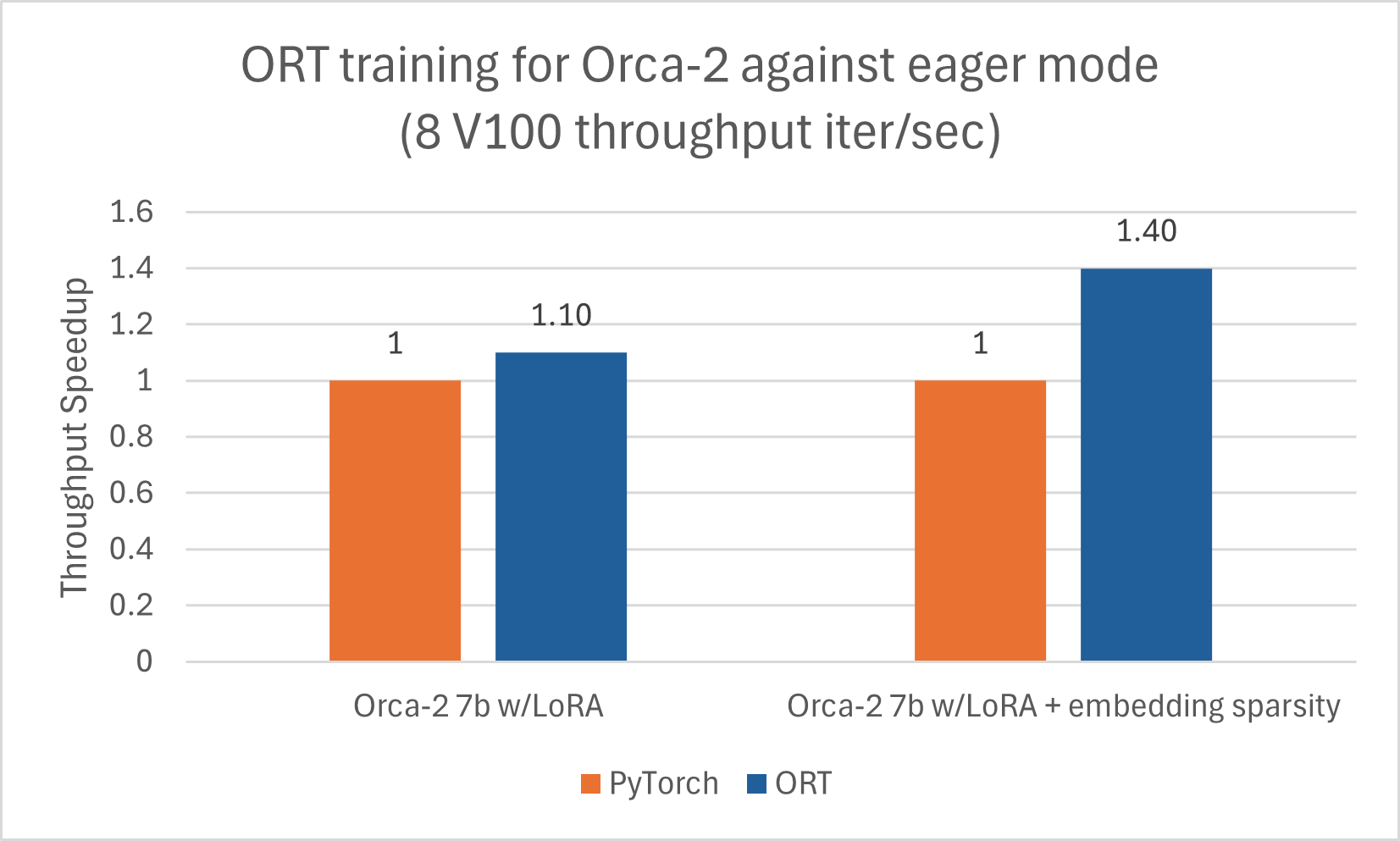 Nutzt ACPT-Image: nightly-ubuntu2004-cu118-py38-torch230dev:20240131
Nutzt ACPT-Image: nightly-ubuntu2004-cu118-py38-torch230dev:20240131 Gemma
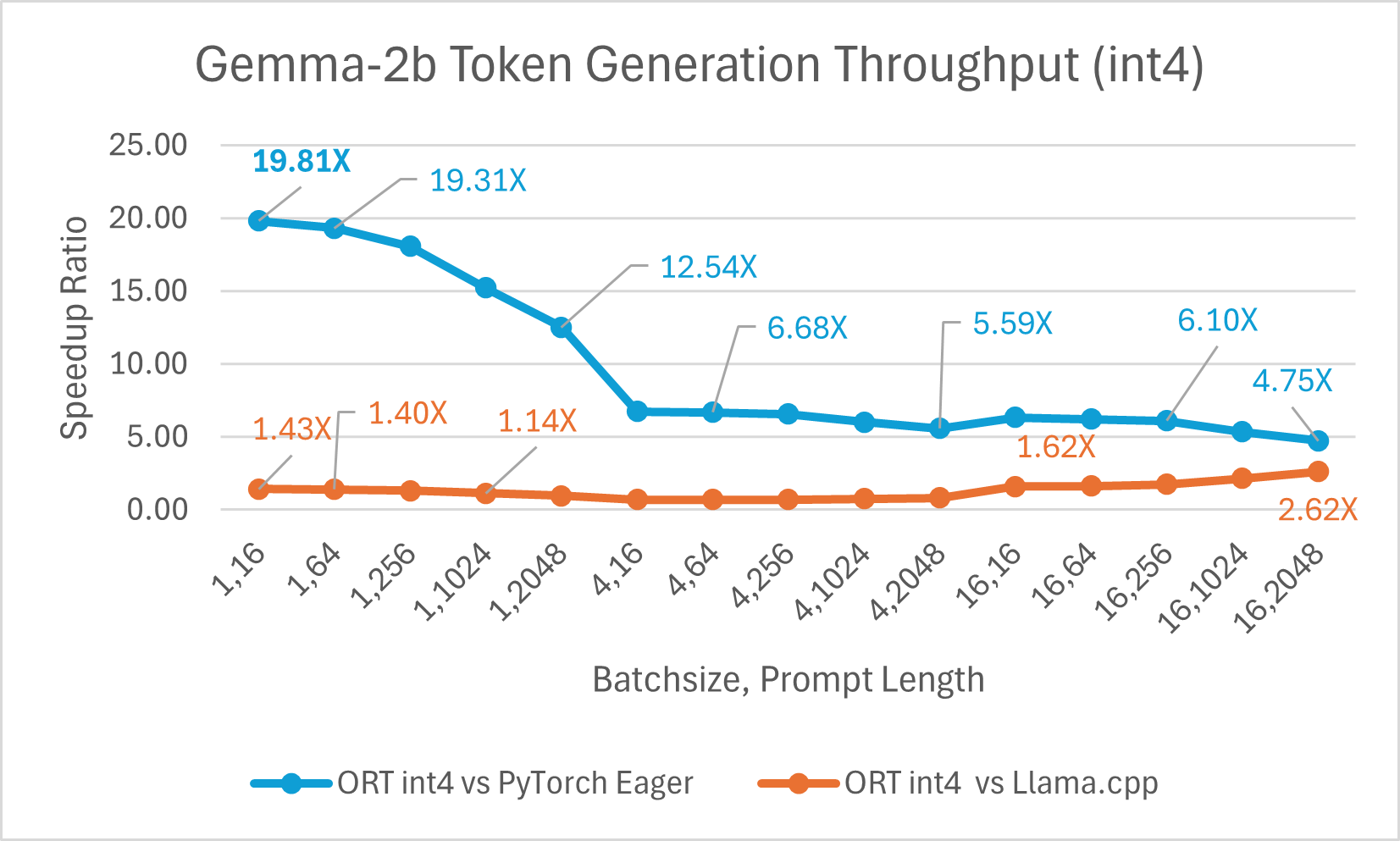
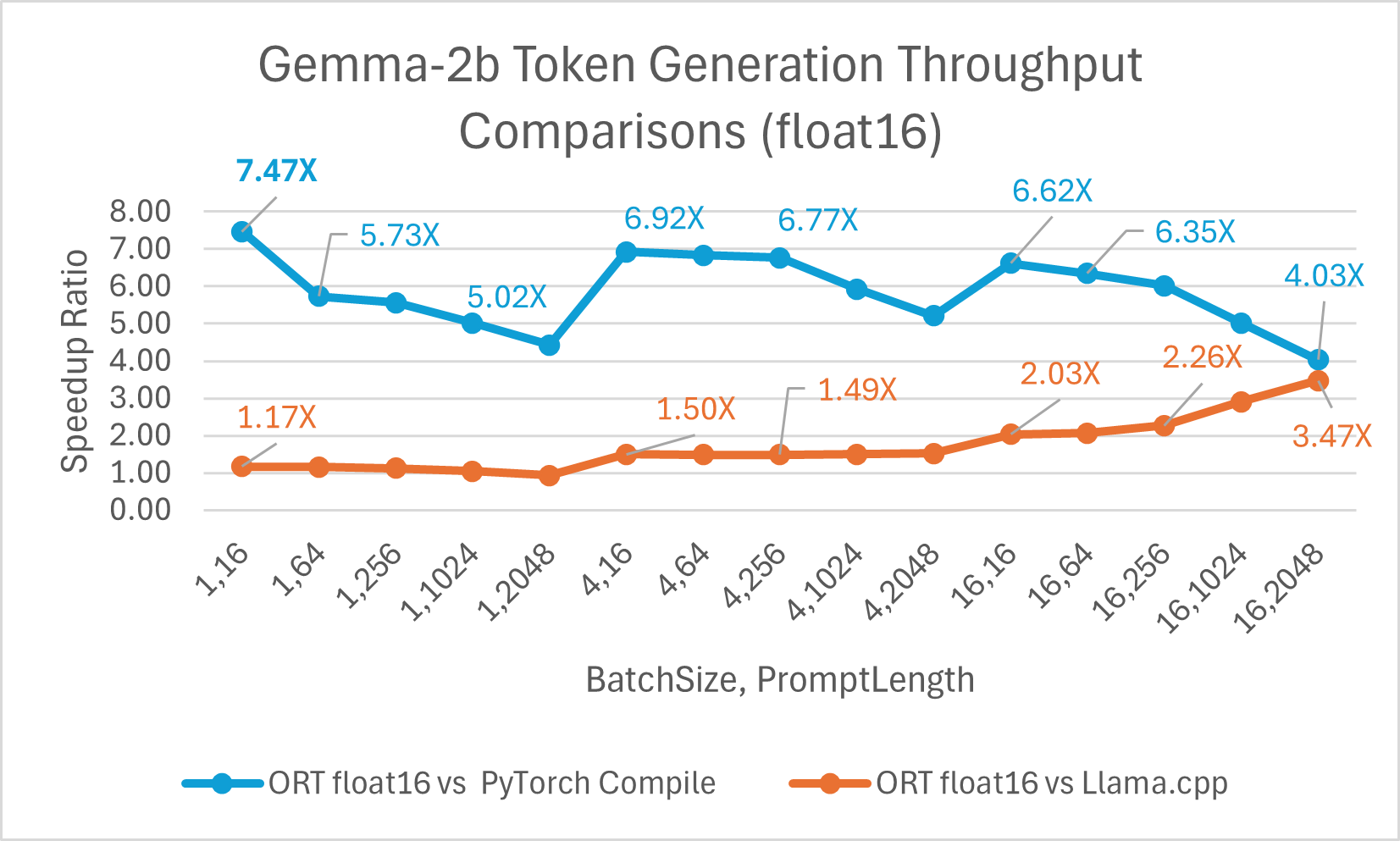
Gemma ist eine Familie von leichten, offenen Modellen, die auf der Forschung und Technologie basieren, die Google zur Erstellung der Gemini-Modelle verwendet hat. Es ist in zwei Größen erhältlich: 2B und 7B. Jede Größe wird mit vortrainierten und anweisungsgestimmten Varianten veröffentlicht. ONNX Runtime kann verwendet werden, um jedes Open-Source-Modell zu optimieren und effizient auszuführen. Wir haben das Modell Gemma-2B verglichen, und ONNX Runtime mit Float16 ist **bis zu 7,47x** schneller als PyTorch Compile und **bis zu 3,47x** schneller als Llama.cpp. ORT mit Int4-Quantisierung ist **bis zu 19,81x** schneller als PyTorch Eager und **2,62x** schneller als Llama.cpp.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass ONNX Runtime (ORT) signifikante Leistungsverbesserungen für mehrere Modelle bietet, darunter Phi-2, Mistral, CodeLlama, SDXL-Turbo, Llama-2, Orca-2 und Gemma. ORT bietet modernste Fusions- und Kernel-Optimierungen, einschließlich Unterstützung für Float16- und Int4-Quantisierung, was zu schnelleren Inferenzgeschwindigkeiten und niedrigeren Kosten führt. ORT übertrifft andere Frameworks wie PyTorch und Llama.cpp in Bezug auf Prompt- und Token-Generierungsdurchsatz. ORT zeigt auch signifikante Vorteile für das Training von LLMs, mit zunehmenden Gewinnen für größere Batch-Größen, und lässt sich gut mit modernen Techniken kombinieren, um effizientes Training großer Modelle zu ermöglichen.