Phi-3 Small und Medium Modelle sind jetzt mit ONNX Runtime und DirectML optimiert
21. Mai 2024
Wir haben zuvor die Optimierungsunterstützung für Phi-3 mini vorgestellt. Nun präsentieren wir optimierte ONNX-Varianten der neu eingeführten Phi-3-Modelle. Die neuen Phi-3-Small und Phi-3-Medium übertreffen Sprachmodelle gleicher Größe sowie deutlich größere Modelle. Phi-3-small schlägt GPT-3.5T in einer Vielzahl von Sprach-, Logik-, Code- und Mathematik-Benchmarks. Die neuen Modelle statten Entwickler mit einem Baustein für generative KI-Anwendungen aus, die starke Logik, begrenzte Rechenleistung und latenzgebundene Szenarien erfordern.
Phi-3-Medium ist ein Sprachmodell mit 14 Milliarden Parametern. Es ist in Varianten mit kurzem (4K) und langem (128K) Kontext verfügbar. Sie finden nun die optimierten Modelle Phi-3-medium-4k-instruct-onnx und Phi-3-medium-128K-instruct-onnx mit ONNX Runtime und DML auf Huggingface! Schauen Sie in der Phi-3 Collection nach den ONNX-Modellen.
Wir haben auch Unterstützung für Phi-3 Small-Modelle für CUDA-fähige Nvidia-GPUs hinzugefügt, weitere Varianten folgen bald. Wir haben Unterstützung für Phi-3 Small-Modelle für CUDA-fähige Nvidia-GPUs hinzugefügt, weitere Varianten folgen bald. Wir haben auch Unterstützung für Phi-3 Small-Modelle für CUDA-fähige Nvidia-GPUs hinzugefügt, weitere Varianten folgen bald. Dies beinhaltet die Unterstützung für den Block Sparse Kernel in der neu veröffentlichten ONNX Runtime 1.18 Release über die ONNX Runtime generate() API.
ONNXRuntime 1.18 fügt neue Features hinzu, wie verbesserte 4-Bit-Quantisierungsunterstützung, verbesserte MultiheadAttention-Performance auf der CPU und Verbesserungen der ONNX Runtime generate() API, um einfachere und effizientere Ausführung auf verschiedenen Geräten zu ermöglichen.
Wir freuen uns auch mitzuteilen, dass das neue optimierte ONNX Phi-3-mini für Web-Deployment jetzt verfügbar ist. Sie können Phi3-mini-4K vollständig im Browser ausführen! Sehen Sie sich das Modell hier an. Darüber hinaus haben wir die optimierte ONNX-Version für CPU und Mobilgeräte mit noch besserer Leistung aktualisiert. Und verpassen Sie nicht diesen Blogbeitrag darüber, wie Sie Phi-3 auf Ihrem Handy und im Browser ausführen.
Ausführung von Phi-3-Medium und Small mit ONNX Runtime
Sie können die ONNX Runtime generate() API nutzen, um diese Modelle nahtlos auszuführen. Die detaillierten Anweisungen finden Sie hier. Sie können auch die Chat-Anwendung lokal ausführen.
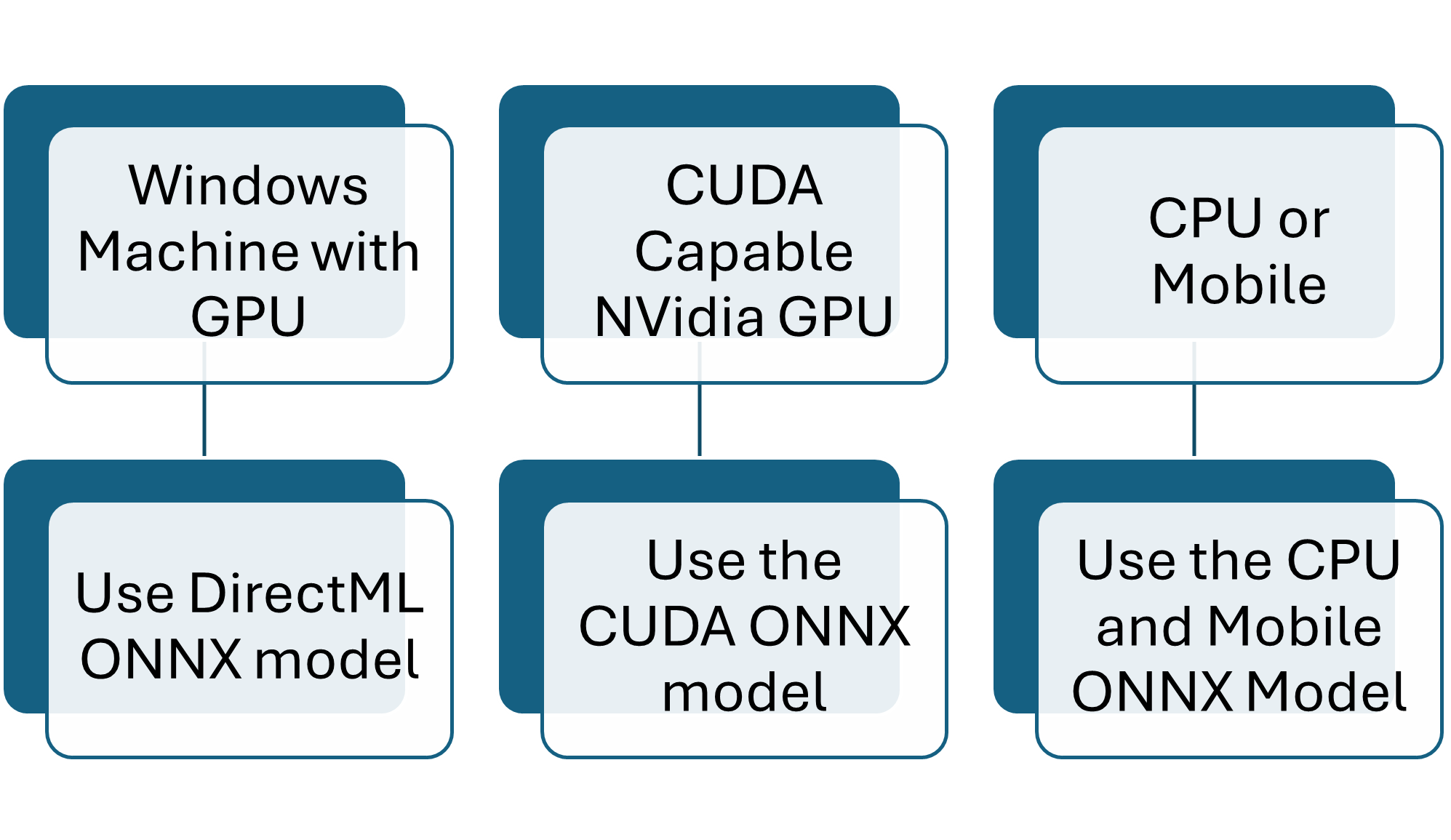
Nur eine Paket- und Modellkombination ist basierend auf Ihrer Hardware erforderlich.
3 einfache Schritte zur Ausführung
- Modell herunterladen
- Die generate() API installieren
- Modell mit phi3-qa.py ausführen
Führen Sie nur die für Ihre Hardware benötigten Schritte aus.
Optimiert für Ihre Plattform
Phi-3 Small 8K ONNX Modell
Phi-3 Medium 4k ONNX Modelle
- microsoft/Phi-3-medium-4k-instruct-onnx-cpu
- microsoft/Phi-3-medium-4k-instruct-onnx-cuda
- microsoft/Phi-3-medium-4k-instruct-onnx-directml
Phi-3 Medium 128k ONNX Modelle
- microsoft/Phi-3-medium-128k-instruct-onnx-cpu
- microsoft/Phi-3-medium-128k-instruct-onnx-cuda
- microsoft/Phi-3-medium-128k-instruct-onnx-directml
Leistung
Die ONNX Runtime Modelle können bis zu 10-mal schneller ausgeführt werden als die PyTorch-Varianten. Der Token-Generierungsdurchsatz in Tokens/Sekunde ist unten für verschiedene Varianten aufgeführt.
| Modell | Batch-Größe, Prompt-Länge | Modellvariante | Token-Generierungsdurchsatz (Tokens/Sekunde) |
|---|---|---|---|
| Phi-3 Medium 4K | |||
| Phi-3 Medium 4K 14B ONNX CUDA | 1, 16 | FP16 CUDA GPU mit ONNX Runtime | 47.32 |
| Phi-3 Medium 4K 14B ONNX CUDA | 16, 64 | FP16 CUDA GPU mit ONNX Runtime | 698.22 |
| Phi-3 Medium 4K 14B ONNX CUDA | 1, 16 | INT4 RTN CUDA GPU mit ONNX Runtime | 115.68 |
| Phi-3 Medium 4K 14B ONNX CUDA | 16, 64 | INT4 RTN CUDA GPU mit ONNX Runtime | 339.45 |
| Phi-3 Medium 4K 14B ONNX DML | 1, 16 | DML INT4 AWQ mit ONNX Runtime | 72.39 |
| Phi-3 Medium 4K 14B ONNX CPU | 16, 64 | INT4 RTN CPU mit ONNX Runtime | 20.77 |
| Phi-3 Medium 128K | |||
| Phi-3 Medium 128K 14B ONNX CUDA | 1, 16 | FP16 CUDA GPU mit ONNX Runtime | 46.27 |
| Phi-3 Medium 128K 14B ONNX CUDA | 16, 64 | FP16 CUDA GPU mit ONNX Runtime | 662.23 |
| Phi-3 Medium 128K 14B ONNX CUDA | 1, 16 | INT4 RTN CUDA GPU mit ONNX Runtime | 108.59 |
| Phi-3 Medium 128K 14B ONNX CUDA | 16, 64 | INT4 RTN CUDA GPU mit ONNX Runtime | 332.57 |
| Phi-3 Medium 128K 14B ONNX DML | 1, 16 | DML INT4 AWQ mit ONNX Runtime | 72.26 |
| Modell | Batch-Größe, Prompt-Länge | Modellvariante | Token-Generierungsdurchsatz (Tokens/Sekunde) |
|---|---|---|---|
| Phi-3 Small 8k | |||
| Phi-3 Small 8K 7B ONNX CUDA | 1, 16 | FP16 CUDA GPU mit ONNX Runtime | 74.62 |
| Phi-3 Small 8K 7B ONNX CUDA | 16, 64 | FP16 CUDA GPU mit ONNX Runtime | 1036.93 |
| Phi-3 Small 8K 7B ONNX CUDA | 1, 16 | INT4 RTN CUDA GPU mit ONNX Runtime | 140.68 |
| Phi-3 Small 8K 7B ONNX CUDA | 16, 64 | INT4 RTN CUDA GPU mit ONNX Runtime | 582.07 |
| Phi-3 Small 128k | |||
| Phi-3 Small 128K 7B ONNX CUDA | 1, 16 | FP16 CUDA GPU mit ONNX Runtime | 68.26 |
| Phi-3 Small 128K 7B ONNX CUDA | 16, 64 | FP16 CUDA GPU mit ONNX Runtime | 577.41 |
| Phi-3 Small 128K 7B ONNX CUDA | 1, 16 | INT4 RTN CUDA GPU mit ONNX Runtime | 73.60 |
| Phi-3 Small 128K 7B ONNX CUDA | 16, 64 | INT4 RTN CUDA GPU mit ONNX Runtime | 1008.35 |
Geräte
- CUDA: A100 GPU, SKU: Standard_ND96amsr_A100_v4
- DML: Nvidia GeForce RTX 4080 (Dedizierter Speicher 16 GB/Gemeinsamer Speicher 24 GB)
- CPU: Intel(R) Core(TM) i9-10920X CPU @ 3,50 GHz
Pakete
- onnxruntime-gpu: 1.18.0
Jetzt loslegen
Um optimiertes Phi-3 selbst zu erleben, können Sie diese Modelle jetzt einfach mit der ONNX Runtime generate() API-Anleitung ausführen. Um mehr zu erfahren, besuchen Sie uns bei den ONNX Runtime-, DML- und Phi-3-Sitzungen auf der Build!