Demokratisierung der KI-Modelloptimierung mit dem neuen Olive CLI
Von
Jambay Kinley, Hitesh Shah, Xiaoyu Zhang, Devang Patel, Sam Kemp11. NOVEMBER 2024
👋 Einführung
Auf der Build 2023 kündigte Microsoft Olive (ONNX Live) an: ein fortschrittliches Werkzeug zur Modelloptimierung, das den Prozess der Optimierung von KI-Modellen für die Bereitstellung mit der ONNX Runtime vereinfachen soll. Wie im folgenden Diagramm dargestellt, kann Olive Modelle von Frameworks wie PyTorch oder Hugging Face übernehmen und optimierte ONNX-Modelle ausgeben, die für spezifische Bereitstellungsziele maßgeschneidert sind.
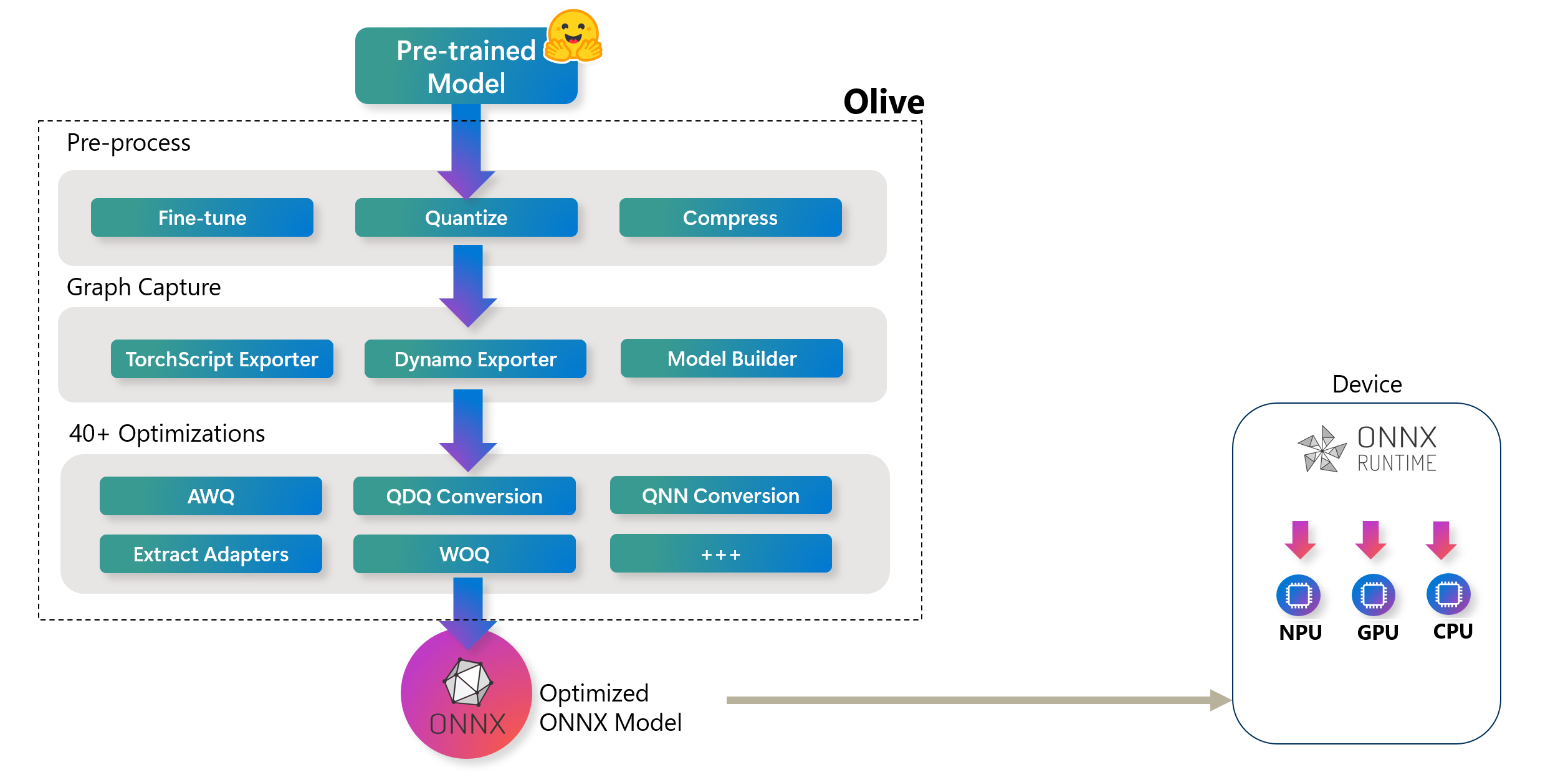 High-Level Olive Workflow. Diese Hardwareziele können verschiedene KI-Beschleuniger (GPU, CPU) umfassen, die von großen Hardwareanbietern wie Qualcomm, AMD, Nvidia und Intel bereitgestellt werden
High-Level Olive Workflow. Diese Hardwareziele können verschiedene KI-Beschleuniger (GPU, CPU) umfassen, die von großen Hardwareanbietern wie Qualcomm, AMD, Nvidia und Intel bereitgestellt werdenOlive arbeitet über einen strukturierten Workflow, der aus einer Reihe von Modelloptimierungsaufgaben besteht, die als Passes bezeichnet werden. Diese Passes können Modellkompression, Grapherfassung, Quantisierung und Graphoptimierung umfassen. Jeder Pass verfügt über einstellbare Parameter, die abgestimmt werden können, um optimale Metriken wie Genauigkeit und Latenz zu erzielen, die von den jeweiligen Evaluatoren bewertet werden. Das Werkzeug nutzt eine Suchstrategie, die Algorithmen einsetzt, um entweder einzelne Passes oder Sätze von Passes gemeinsam zu optimieren und so die bestmögliche Leistung für die Bereitstellungsziele zu gewährleisten.
Obwohl das in Olive verwendete Workflow-Paradigma sehr flexibel ist, kann die Lernkurve für KI-Entwickler, die neu im Bereich der Modelloptimierung sind, herausfordernd sein. Um die Modelloptimierung zugänglicher zu machen, haben wir eine Reihe von Olive-Workflows für gängige Szenarien zusammengestellt und sie als einfachen Befehl in einer neuen, einfach zu bedienenden CLI für Olive bereitgestellt.
 Zuordnung der neuen Olive CLI-Befehle zu dem zugehörigen Olive-Workflow, der ausgeführt wird.
Zuordnung der neuen Olive CLI-Befehle zu dem zugehörigen Olive-Workflow, der ausgeführt wird.In diesem Blog-Artikel zeigen wir Ihnen, wie Sie Modelle für die ONNX Runtime mit dem Olive CLI vorbereiten.
🚀 Erste Schritte mit dem Olive CLI
Installieren Sie zunächst Olive mit pip
pip install olive-ai[cpu,finetune]🪄 Automatischer Optimierer
Sobald Sie Olive installiert haben, probieren Sie den automatischen Optimierer (olive auto-opt) aus. In einem einzigen Befehl wird Olive
- Das Modell von Hugging Face herunterladen
- Die Modellstruktur in einen ONNX-Graphen erfassen und die Gewichte in ONNX-Format konvertieren.
- Den ONNX-Graphen optimieren (z. B. Fusion)
- Die Modellgewichte in int4 quantisieren
Der Befehl zum Ausführen des automatischen Optimierers für das Llama-3.2-1B-Instruct-Modell auf CPU-Geräten lautet:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device cpu \
--provider CPUExecutionProvider \
--precision int4 \
--use_model_builder True \
--log_level 1
Tipp: Wenn Sie
- CUDA GPU anvisieren möchten, aktualisieren Sie
--deviceaufgpuund--provideraufCUDAExecutionProvider.- Windows DirectML, aktualisieren Sie dann
--deviceaufgpuund--provideraufDmlExecutionProvider.Olive wendet die spezifischen Optimierungen für das Gerät und den Provider an.
Mit dem Befehl auto-opt können Sie das Eingabemodell gegen ein auf Hugging Face verfügbares Modell austauschen - z. B. HuggingFaceTB/SmolLM-360M-Instruct - oder ein Modell, das sich auf der lokalen Festplatte befindet. Es ist zu beachten, dass das Argument --trust_remote_code in olive auto-opt nur für benutzerdefinierte Modelle in Hugging Face erforderlich ist, die Code auf Ihrem Rechner ausführen müssen - weitere Details finden Sie in der Hugging Face-Dokumentation zu trust_remote_code. Olive durchläuft denselben Prozess der automatischen Konvertierung (in ONNX), der Graphoptimierung und der Quantisierung der Gewichte.
🧪 Experimentieren mit verschiedenen Quantisierungsalgorithmen
Das Olive CLI ermöglicht es Ihnen, mit vielen verschiedenen Quantisierungsalgorithmen - wie AWQ, GPTQ und QuaRot - und verschiedenen Implementierungen dieser Algorithmen zu experimentieren. Zum Beispiel zur Quantisierung von Llama-3.2-1B-Instruct mit Activation Aware Quantization (AWQ)
Hinweis: Ihr Computer muss über ein CUDA GPU-Gerät und die zugehörigen Treiber installiert haben, um AWQ, GPTQ und QuaRot-Quantisierung auszuführen. Außerdem sollten Sie das AutoAWQ-Paket über
pip install autoawq
olive quantize \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--algorithm awq \
--output_path quantized-model \
--log_level 1
Der Befehl quantize gibt bei Verwendung der AWQ-Methode ein PyTorch-Modell aus, das Sie in ONNX konvertieren können, wenn Sie das Modell auf der ONNX Runtime verwenden möchten, indem Sie
olive capture-onnx-graph \
--model_name_or_path quantized-model/model \
--use_ort_genai True \
--log_level 1 \
🎚️ Fine-Tuning
Das Olive CLI bietet auch die Werkzeuge zum Fine-Tuning eines KI-Modells auf Ihren eigenen Daten für spezifische Aufgaben unter Verwendung von LoRA oder QLoRA. Das folgende Beispiel wird Llama-3.2-1B-Instruct für die Phrasenklassifizierung feinabstimmen (bei einer englischen Phrase wird eine Kategorie ausgegeben: Freude/Trauer/Angst/Überraschung).
olive finetune \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path models/llama3.2/ft \
--data_name xxyyzzz/phrase_classification \
--text_template "<|start_header_id|>user<|end_header_id|>\n{phrase}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n{tone}" \
--method qlora \
--max_steps 30 \
--log_level 1 \
Der Befehl finetune gibt einen Hugging Face PEFT-Adapter aus, den Sie für die ONNX Runtime vorbereiten können mit
# Step 1 - capture the ONNX graph of the base model and adapter
olive capture-onnx-graph \
--model_name_or_path models/llama3.2/ft/model \
--adapter_path models/llama3.2/ft/adapter \
--use_ort_genai \
--output_path models/llama3.2/onnx \
--log_level 1
# Step 2 - Extract adapter weights from ONNX model and store in separate file for ORT
olive generate-adapter \
--model_name_or_path models/llama3.2/onnx \
--output_path adapter-onnx \
--log_level 1
🤝 Inferenz Ihrer optimierten KI-Modelle mit der Generate API für ONNX Runtime
Der folgende Python-Code erstellt eine einfache konsolenbasierte Chat-Oberfläche, die Ihr optimiertes Modell mit der Generate API für ONNX Runtime inferiert.
Tipp: Andere Sprach-Bindings – wie C#, C/C++, Java – mit weiteren bald. Eine aktuelle Liste finden Sie auf der Generate API für ONNX Runtime Github-Seite
import onnxruntime_genai as og
import numpy as np
import os
model_folder = "optimized-model/model"
# Load the base model and tokenizer
model = og.Model(model_folder)
tokenizer = og.Tokenizer(model)
tokenizer_stream = tokenizer.create_stream()
# Set the max length to something sensible by default,
# since otherwise it will be set to the entire context length
search_options = {}
search_options['max_length'] = 200
search_options['past_present_share_buffer'] = False
chat_template = """<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""
text = input("Input: ")
# Keep asking for input phrases
while text != "exit":
if not text:
print("Error, input cannot be empty")
exit
# generate prompt (prompt template + input)
prompt = f'{chat_template.format(input=text)}'
# encode the prompt using the tokenizer
input_tokens = tokenizer.encode(prompt)
params = og.GeneratorParams(model)
params.set_search_options(**search_options)
params.input_ids = input_tokens
generator = og.Generator(model, params)
print("Output: ", end='', flush=True)
# stream the output
try:
while not generator.is_done():
generator.compute_logits()
generator.generate_next_token()
new_token = generator.get_next_tokens()[0]
print(tokenizer_stream.decode(new_token), end='', flush=True)
except KeyboardInterrupt:
print(" --control+c pressed, aborting generation--")
print()
text = input("Input: ")Schlussfolgerung
In diesem Blog haben wir gezeigt, wie Sie Modelle für die ONNX Runtime mit dem neuen Olive CLI komponieren und diese Modelle dann mit der Generate API für ONNX Runtime inferieren können. Die Olive CLI-Befehle führen einen kuratierten Olive-Workflow für Sie aus, was bedeutet, dass Sie weiterhin all die folgenden Vorteile genießen
- Reduzieren Sie Frustration und Zeit für den manuellen Versuch-und-Irrtum-Experimenten mit verschiedenen Techniken für Graphoptimierung, Kompression und Quantisierung. Definieren Sie Ihre Qualitäts- und Leistungsanforderungen und lassen Sie Olive automatisch das beste Modell für Sie finden.
- Über 40 integrierte Modelloptimierungs-Komponenten, die modernste Techniken in den Bereichen Quantisierung, Kompression, Graphoptimierung und Fine-Tuning abdecken.
- Unterstützt die Erstellung von Modellen, die mit dem Multi LoRA-Paradigma bereitgestellt werden können.
- Integrationen mit Hugging Face und Azure AI.
- Integrierter Caching-Mechanismus zur Kosteneinsparung und Verbesserung der Teamzusammenarbeit. Wie wir in einem früheren Blog-Artikel mitteilten, unterstützt Olive auch einen gemeinsamen Cache.