Ist es besser, vor oder nach dem Finetuning zu quantisieren?
Von
Jambay Kinley, Sam Kemp19. NOVEMBER 2024
👋 Einführung
Quantisierung im maschinellen Lernen ist eine Technik zur Reduzierung der Präzision von Zahlen, die in Berechnungen verwendet werden, was zur Effizienzsteigerung von Modellen beiträgt. Anstatt hochpräzise Gleitkommazahlen (wie 32-Bit oder 16-Bit) zu verwenden, konvertiert die Quantisierung diese Zahlen in Formate mit geringerer Präzision, wie z. B. 8-Bit-Ganzzahlen. Die Hauptvorteile der Quantisierung sind eine geringere Modellgröße und schnellere Berechnungen, was besonders nützlich für die Bereitstellung von Modellen auf Geräten mit begrenzten Ressourcen ist, wie z. B. Mobiltelefonen oder eingebetteten Systemen. Diese Reduzierung der Präzision kann jedoch manchmal zu einem leichten Rückgang der Modellgenauigkeit führen.
Das Finetuning eines KI-Modells mit der LoRA (Low-Rank Adaptation)-Methode ist eine effiziente Methode, um große Sprachmodelle an spezifische Aufgaben oder Domänen anzupassen. Anstatt alle Modellparameter neu zu trainieren, modifiziert LoRA den Finetuning-Prozess, indem es die ursprünglichen Modellgewichte einfriert und Änderungen an einem separaten Satz von Gewichten vornimmt, die dann zu den ursprünglichen Parametern hinzugefügt werden. Dieser Ansatz wandelt die Modellparameter in eine niedrigere Rangdimension um, was die Anzahl der zu trainierenden Parameter reduziert und somit den Prozess beschleunigt und die Kosten senkt.
Beim Finetuning und Quantisieren eines Modells ist es wichtig, die richtige Reihenfolge festzulegen
- Ist es besser, *vor* dem Finetuning zu quantisieren oder danach?
Theoretisch sollte die Quantisierung vor dem Finetuning ein besseres Modell ergeben, da LoRA-Gewichte mit denselben quantisierten Basismodellgewichten trainiert werden, mit denen sie auch bereitgestellt werden. Dies vermeidet den Genauigkeitsverlust, der auftritt, wenn auf Float-Basistrainingsgewichten trainiert und dann mit einem quantisierten Basismodell bereitgestellt wird. In diesem Blogbeitrag demonstrieren wir, wie Olive – ein hochmoderner Toolkit zur Modelloptimierung für die ONNX-Laufzeit – Ihnen helfen kann, zu beantworten, wann quantisiert werden soll und welcher Quantisierungsalgorithmus für eine gegebene Modellarchitektur und ein gegebenes Szenario verwendet werden soll.
Darüber hinaus zeigen wir als Teil der Beantwortung der Frage, wann quantisiert werden soll, wie sich die folgenden verschiedenen Quantisierungs*algorithmen* auf die Genauigkeit auswirken:
- Activation-Aware Weight Quantization (AWQ) ist eine Technik zur Optimierung großer Sprachmodelle (LLMs) für eine effiziente Ausführung. AWQ quantisiert die Gewichte eines Modells unter Berücksichtigung der während der Inferenz erzeugten Aktivierungen. Das bedeutet, dass der Quantisierungsprozess die tatsächliche Datenverteilung in den Aktivierungen berücksichtigt, was zu einer besseren Erhaltung der Modellgenauigkeit im Vergleich zu herkömmlichen Gewichtsquantisierungsmethoden führt.
- Generalized Post-Training Quantization (GPTQ) ist eine Post-Training-Quantisierungstechnik, die für Generative Pre-trained Transformer (GPT)-Modelle entwickelt wurde. Sie quantisiert die Gewichte des Modells auf niedrigere Bitbreiten, wie z. B. 4-Bit-Ganzzahlen, um den Speicherbedarf und die Rechenanforderungen zu reduzieren, ohne die Genauigkeit des Modells erheblich zu beeinträchtigen. Diese Technik quantisiert jede Zeile der Gewichtsmatrix unabhängig, um eine Version der Gewichte zu finden, die den Fehler minimiert.
⚗️ Durchführung des Experiments mit Olive
Um unsere Frage zur richtigen Sequenzierung von Quantisierung und Finetuning zu beantworten, haben wir Olive (ONNX Live) genutzt – ein fortschrittliches Toolkit zur Modelloptimierung, das darauf ausgelegt ist, den Prozess der Optimierung von KI-Modellen für die Bereitstellung mit der ONNX-Laufzeit zu vereinfachen.
Hinweis: Sowohl die Quantisierung als auch das Finetuning müssen auf einer Nvidia A10 oder A100 GPU-Maschine ausgeführt werden.
1. 💾 Olive installieren
Wir haben das Olive CLI mit pip installiert.
pip install olive-ai[finetune]
pip install autoawq
pip install auto-gptq
2. 🗜️ Quantisieren
Wir quantisieren Phi-3.5-mini-instruct unter Verwendung sowohl der AWQ- als auch der GPTQ-Algorithmen mit den folgenden Olive-Befehlen:
# AWQ Quantization
olive quantize \
--algorithm awq \
--model_name_or_path microsoft/Phi-3.5-mini-instruct \
--output_path models/phi-awq
# GPTQ Quantization
olive quantize \
--algorithm gptq \
--model_name_or_path microsoft/Phi-3.5-mini-instruct \
--data_name wikitext \
--subset wikitext-2-raw-v1 \
--split train \
--max_samples 128 \
--output_path models/phi-gptq
3. 🎚️ Finetunen
Wir finetunen *die quantisierten Modelle* unter Verwendung des tiny codes Datensatzes von Hugging Face. Dies ist ein gated Datensatz und Sie müssen Zugriff beantragen. Sobald der Zugriff gewährt wurde, sollten Sie sich mit Ihrem Zugriffstoken bei Hugging Face anmelden.
huggingface-clu login --token TOKEN
Olive kann mit den folgenden Befehlen finetunen:
# Finetune AWQ model
olive finetune \
--model_name_or_path models/phi-awq \
--data_name nampdn-ai/tiny-codes \
--train_split "train[:4096]" \
--eval_split "train[4096:4224]" \
--text_template "### Language: {programming_language} \n### Question: {prompt} \n### Answer: {response}" \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--max_steps 100 \
--logging_steps 25 \
--output_path models/phi-awq-ft
# Finetune GPTQ model
olive finetune \
--model_name_or_path models/phi-gptq \
--data_name nampdn-ai/tiny-codes \
--train_split "train[:4096]" \
--eval_split "train[4096:4224]" \
--text_template "### Language: {programming_language} \n### Question: {prompt} \n### Answer: {response}" \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--max_steps 100 \
--logging_steps 25 \
--output_path models/phi-gptq-ft
Hinweis: Wir haben auch die umgekehrte Sequenz durchgeführt, bei der wir zuerst finetuned und dann quantisiert haben. Es sind dieselben Befehle, nur in anderer Reihenfolge.
4. 🎯 Perplexität ausführen
Wir haben eine Perplexitätsmetrik auf den Modellen mit Olive ausgeführt. Zuerst definierten wir die folgende Olive-Konfiguration in einer Datei namens perplexity-config.yaml, die die Bewertungsfunktion von Olive verwendet:
input_model:
type: HfModel
model_path: models/phi-awq-ft/model
adapter_path: models/phi-awq-ft/adapter
systems:
local_system:
type: LocalSystem
accelerators:
- device: gpu
execution_providers:
- CUDAExecutionProvider
data_configs:
- name: tinycodes_ppl
type: HuggingfaceContainer
load_dataset_config:
data_name: nampdn-ai/tiny-codes
split: 'train[5000:6000]'
pre_process_data_config:
text_template: |-
### Language: {programming_language}
### Question: {prompt}
### Answer: {response}
strategy: line-by-line
max_seq_len: 1024
dataloader_config:
batch_size: 8
evaluators:
common_evaluator:
metrics:
- name: tinycodes_ppl
type: accuracy
sub_types:
- name: perplexity
data_config: tinycodes_ppl
passes: {}
auto_optimizer_config:
disable_auto_optimizer: true
evaluator: common_evaluator
host: local_system
target: local_system
output_dir: models/eval
Hinweis: Wir definieren die gleichen Konfigurationen für die anderen Modelle, haben aber das
input_modelaktualisiert.
Anschließend haben wir die Olive-Konfiguration mit folgendem Befehl ausgeführt:
olive run --config perplexity-config.yaml📊 Ergebnisse
Phi-3.5-Mini-Instruct
Die folgende Tabelle zeigt die Perplexitätsmetriken für die
- Unterschiedlichen Quantisierungs- und Finetuning-Sequenzen (Magenta)
- Phi-3.5-Mini-Instruct Basismodell (gestrichelte grüne Linie), welches nicht quantisiert ist
- Phi-3.5-Mini-Instruct Finetuned Modell (durchgezogene grüne Linie), welches nicht quantisiert ist
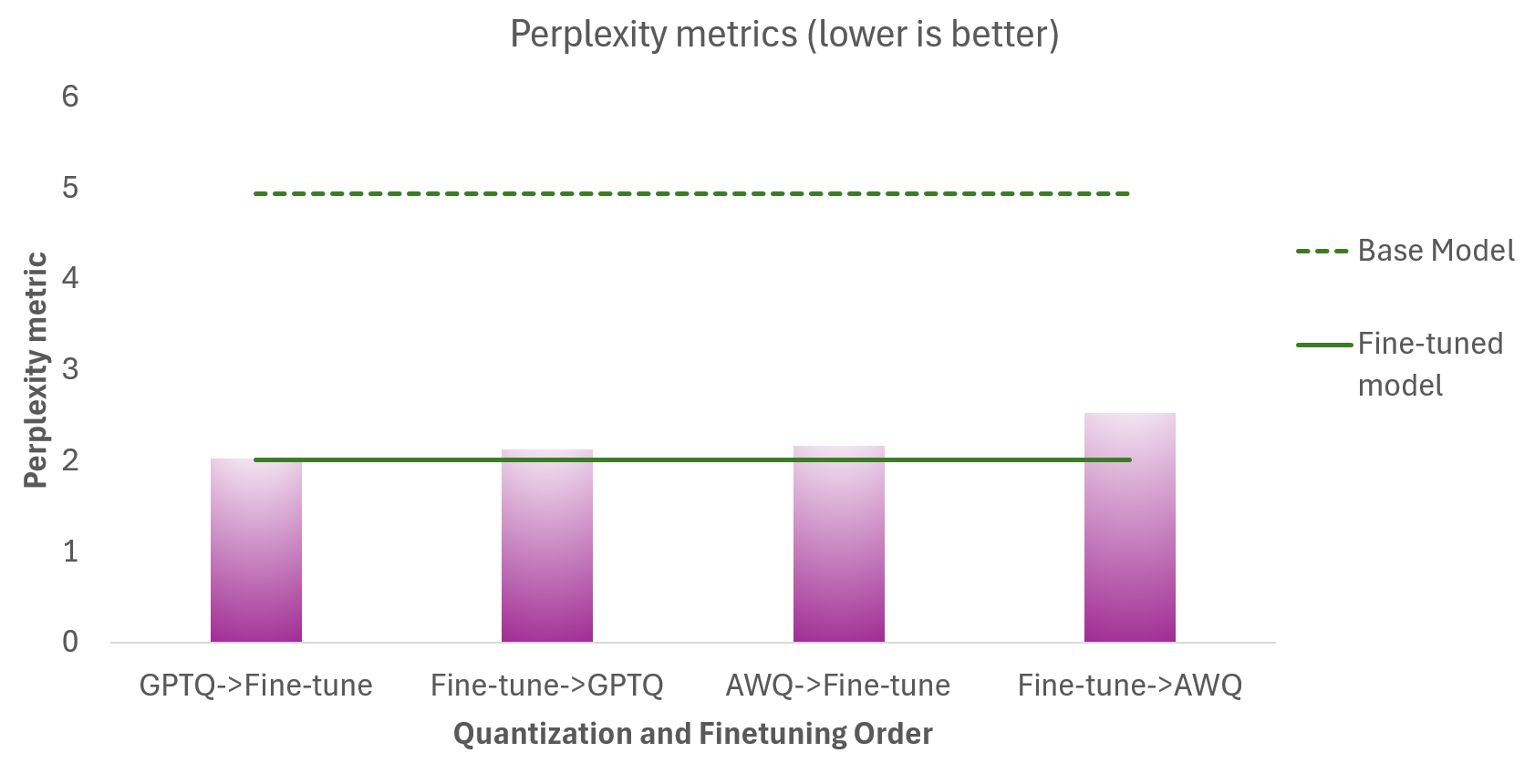
Ziel ist es, dass die quantisierten Modelle so nah wie möglich am Finetuned Modell (durchgezogene grüne Linie) liegen. Es gibt mehrere Erkenntnisse:
- Die Quantisierung hat keine signifikante Auswirkung auf die Modellqualität – wie die Nähe der Perplexitätswerte für quantisierte Modelle zum Finetuned Basismodell zeigt.
- Die Quantisierung *vor* dem Finetuning liefert bessere Ergebnisse als die Quantisierung nach dem Finetuning.
- GPTQ bietet in diesem Szenario eine bessere Genauigkeit als AWQ.
Llama-3.1-8B-Instruct
Die folgende Tabelle zeigt die Perplexitätsmetriken für die
- Unterschiedliche Quantisierungs- und Finetuning-Sequenzen (Blau)
- Llama-3.1-8B-Instruct Basismodell (gestrichelte grüne Linie), welches nicht quantisiert ist
- Llama-3.1-8B-Instruct Finetuned Modell (durchgezogene grüne Linie), welches nicht quantisiert ist
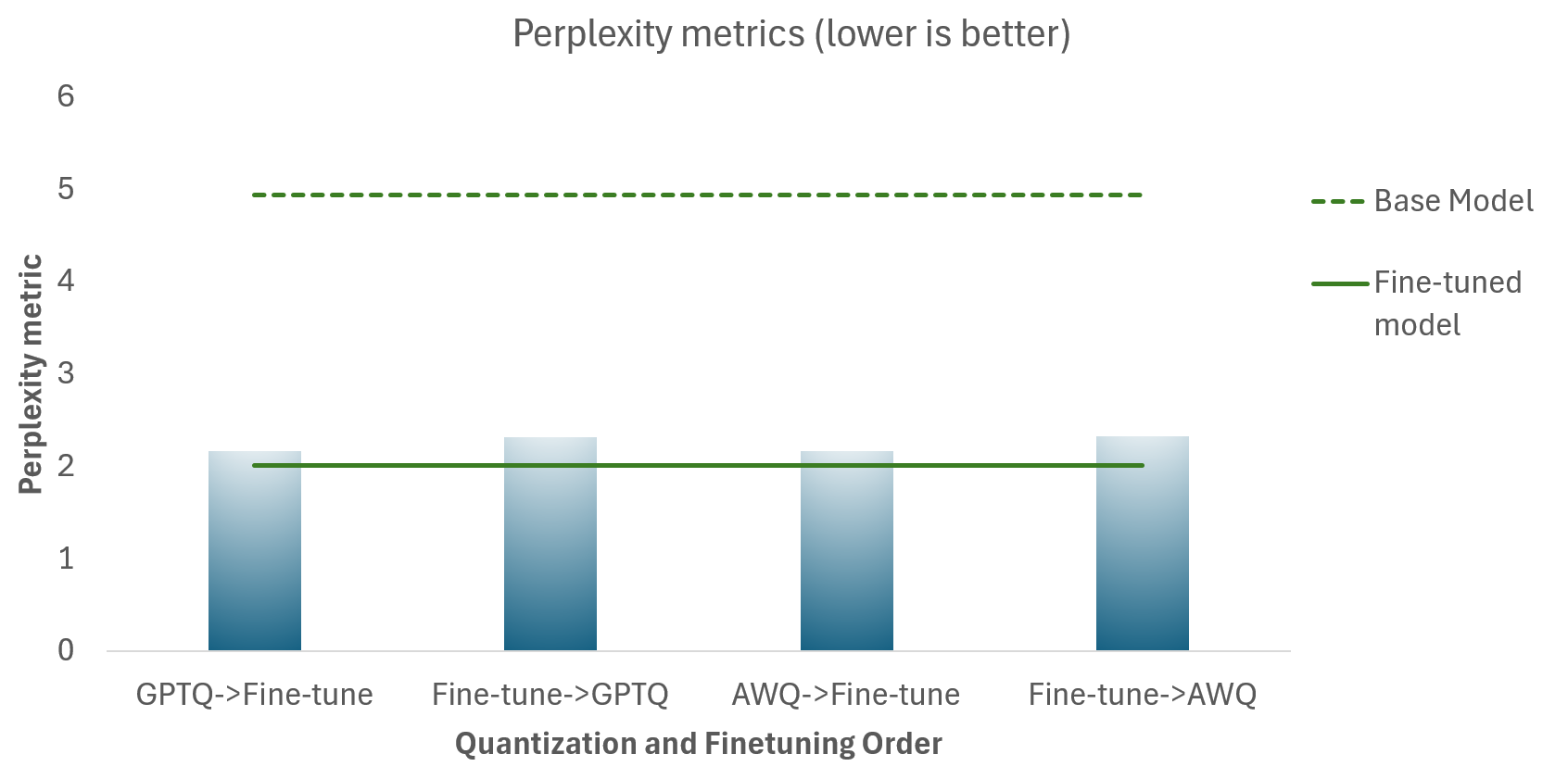
Ziel ist es, dass die quantisierten Modelle so nah wie möglich am Finetuned Modell (durchgezogene grüne Linie) liegen. Es gibt mehrere Erkenntnisse:
- Die Quantisierung hat keine signifikante Auswirkung auf die Modellqualität – wie die Nähe der Perplexitätswerte für quantisierte Modelle zum Finetuned Basismodell zeigt.
- Die Quantisierung *vor* dem Finetuning liefert bessere Ergebnisse als die Quantisierung nach dem Finetuning.
- GPTQ und AWQ liefern ähnliche Ergebnisse bei der Modellqualität.
Schlussfolgerung
In diesem Blogbeitrag haben wir gezeigt, wie wir Olive zur Beantwortung gängiger Fragen zur Optimierung von KI-Modellen genutzt haben. Unsere Ergebnisse zeigten, dass die Quantisierung vor dem Finetuning die Modellqualität sowohl für Phi-3.5-mini-instruct als auch für Llama-3.1-8B-Instruct verbessert. Diese quantisierten Varianten entsprechen der Qualität ihrer Full-Precision (FP32)-Pendants sehr gut und benötigen dabei weniger Speicher und Speicherplatz. Dies unterstreicht das Potenzial von On-Device-KI, qualitativ hochwertige Leistung mit einem reduzierten Ressourcen-Footprint zu liefern.