ONNX Runtime 1.17: CUDA 12 Unterstützung, Phi-2 Optimierungen, WebGPU und mehr!
Von
Sophie Schoenmeyer, Parinita Rahi, Kshama Pawar, Caroline Zhu, Chad Pralle, Emma Ning, Natalie Kershaw, Jian Chen28. FEBRUAR 2024
Kürzlich haben wir ONNX Runtime 1.17 veröffentlicht, das eine Vielzahl neuer Funktionen enthält, um die Inferenz und das Training von Machine-Learning-Modellen auf verschiedenen Plattformen schneller als je zuvor zu optimieren. Die Veröffentlichung enthält Verbesserungen an einigen unserer bestehenden Funktionen sowie spannende neue Funktionen wie Phi-2-Optimierungen, das Trainieren eines Modells im Browser mit On-Device-Training, ONNX Runtime Web mit WebGPU und mehr.
Eine vollständige Liste der neuen Funktionen sowie verschiedene Assets finden Sie in der Version 1.17 und unserem kürzlichen 1.17.1 Patch-Release auf GitHub.
Modelloptimierung
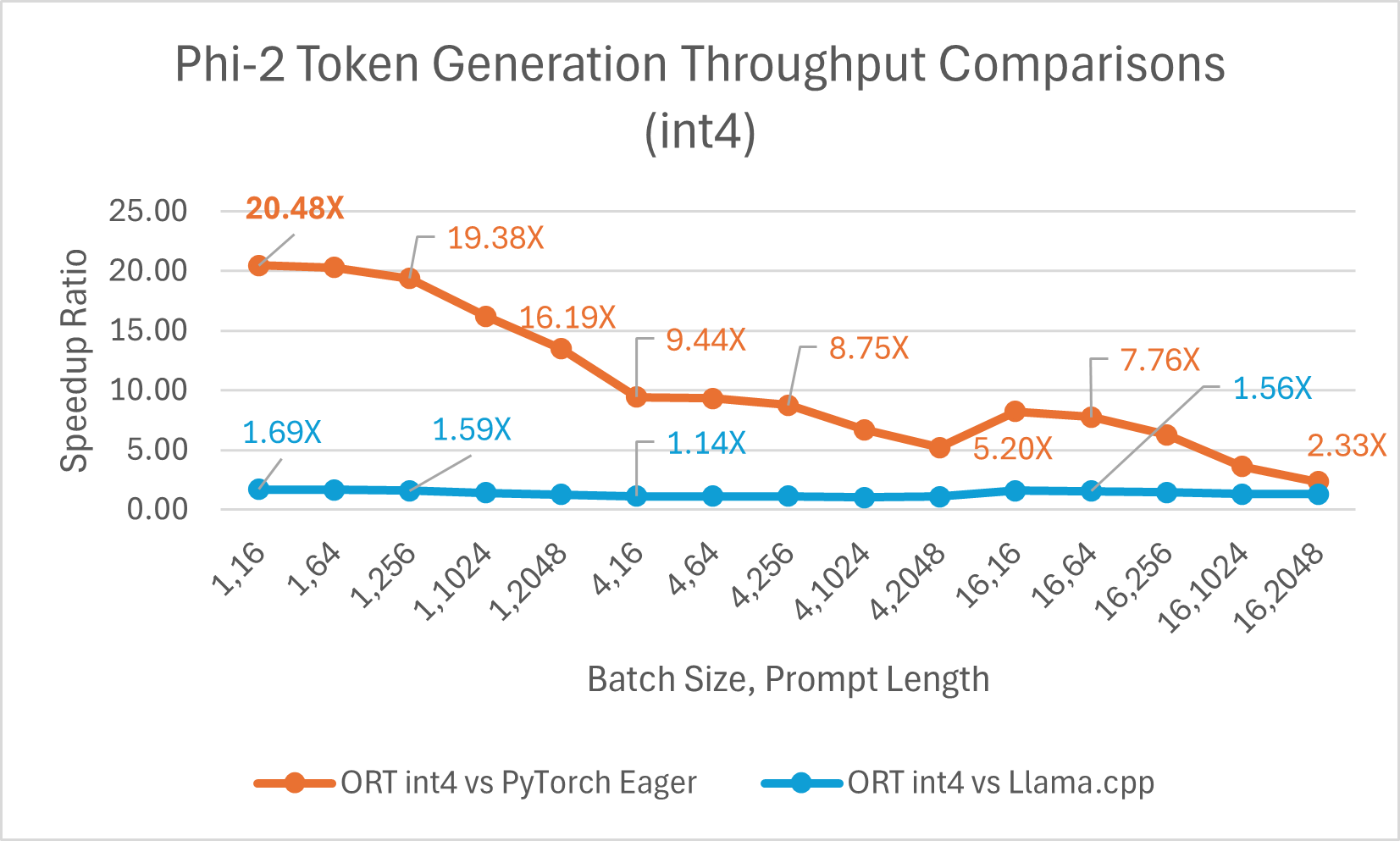
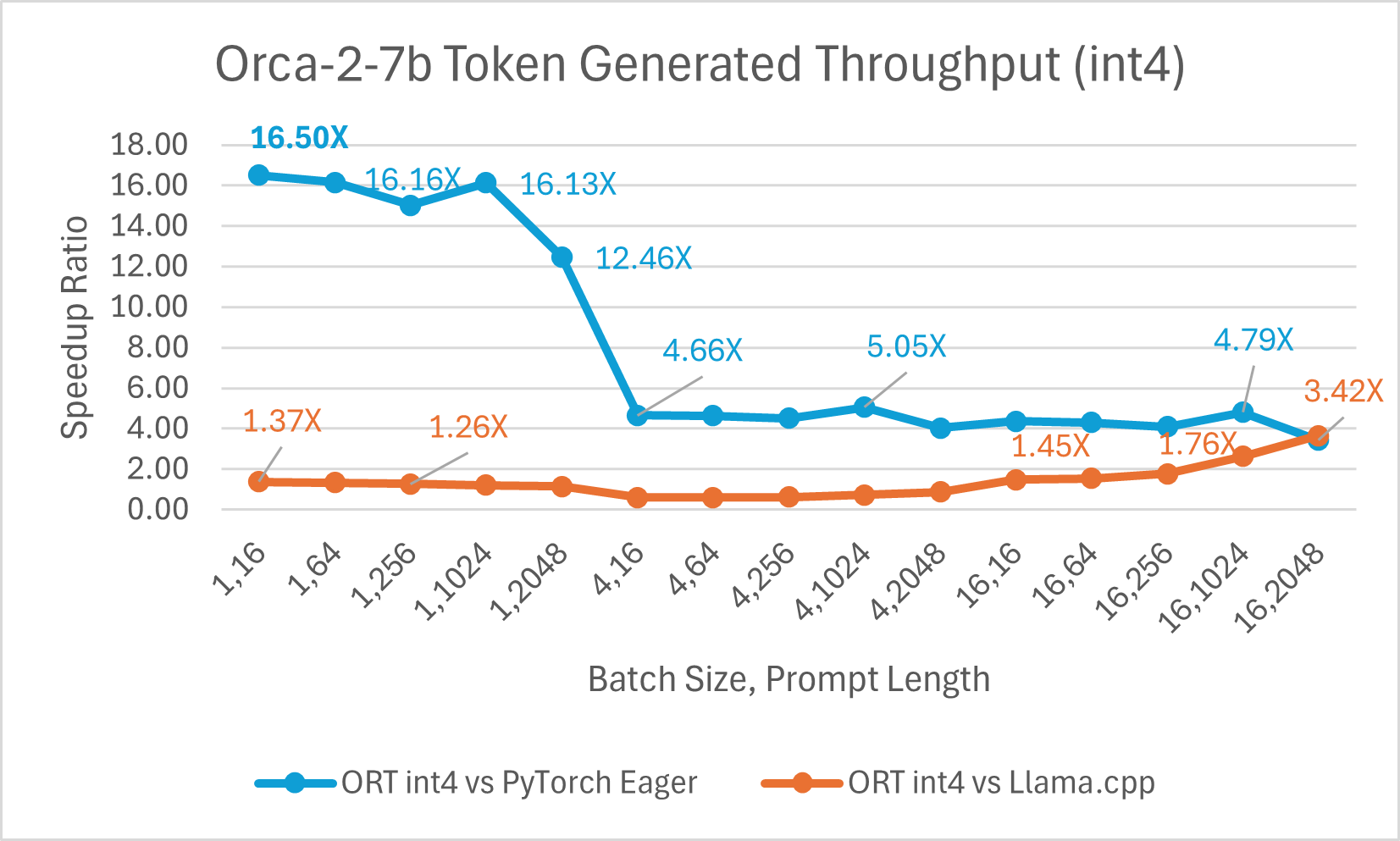
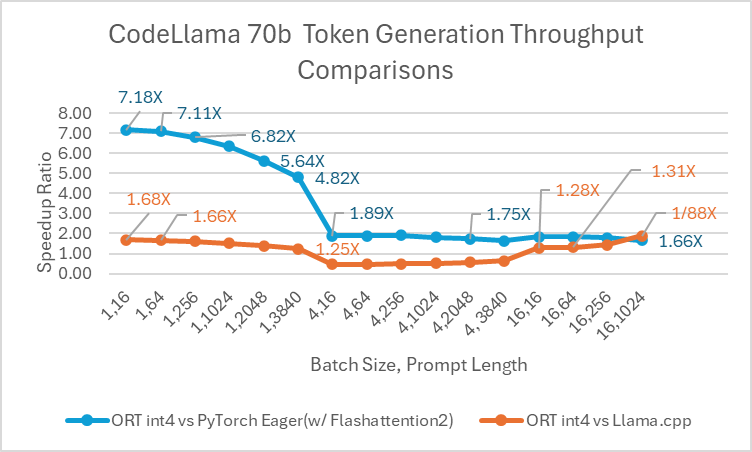
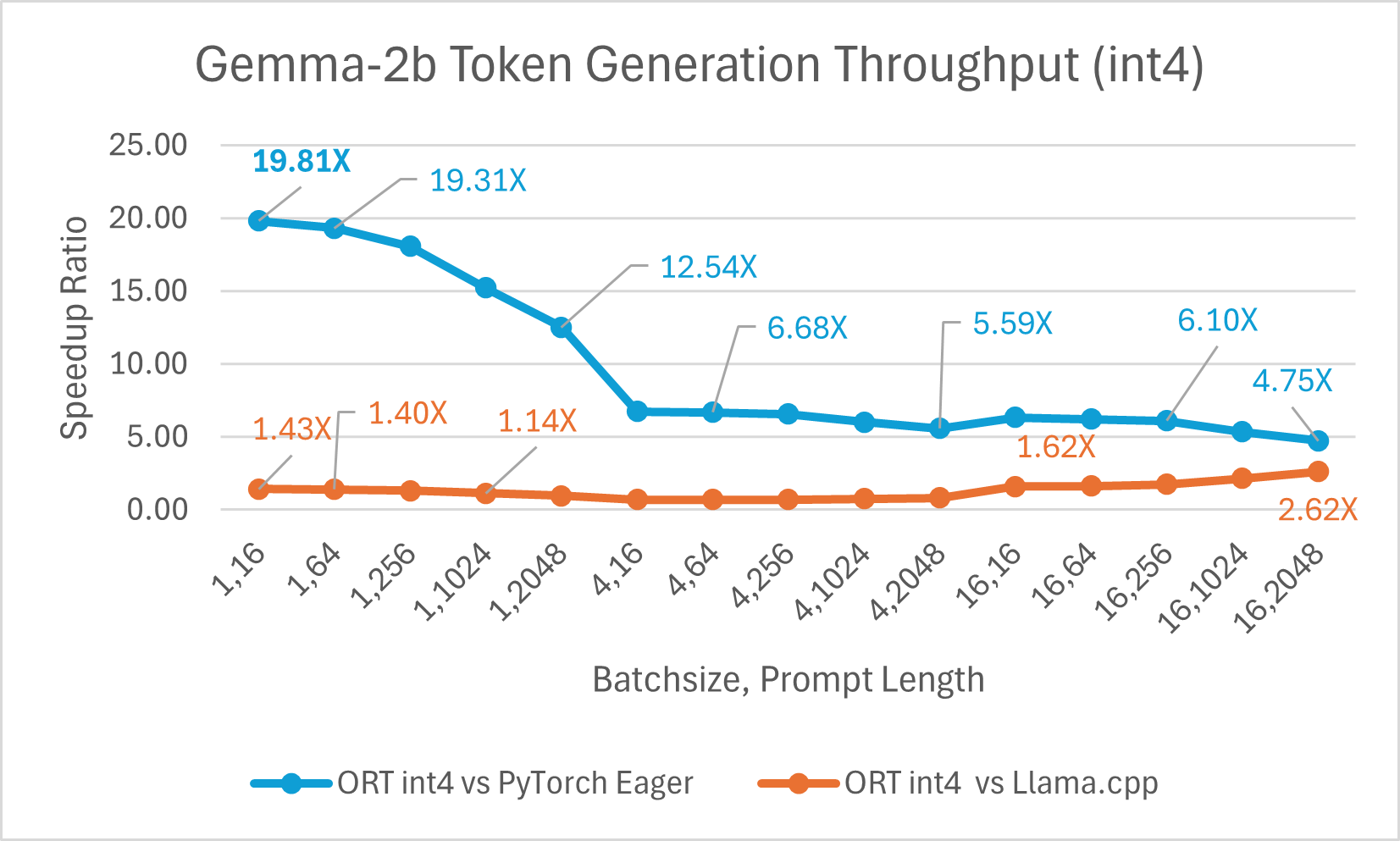
Die ORT 1.17-Veröffentlichung von ONNX Runtime bietet eine verbesserte Inferenzleistung für mehrere Modelle wie Phi-2, Mistral, CodeLlama, Googles Gemma, SDXL-Turbo und mehr durch den Einsatz modernster Fusions- und Kerneloptimierungen sowie Unterstützung für Float16 und Int4-Quantisierung. Die spezifischen ORT-Optimierungen, die in dieser Version hinzugefügt wurden, sind Änderungen an den Kernels für Attention, Multi-Head Attention, Grouped-Query Attention und Rotary Embedding. ORT übertrifft andere Frameworks wie PyTorch, DeepSpeed und Llama.cpp in Bezug auf Prompt- und Token-Generierungsdurchsatz mit Geschwindigkeitssteigerungen von bis zu **20x schneller**. Insbesondere beobachten wir Leistungssteigerungen von bis zu **20,5x für Phi-2**, **16,0x für Orca-2** und **19,8x für Gemma** (siehe verlinkten Blogbeitrag unten für weitere Details zu jedem Modell). ONNX Runtime mit Int4-Quantisierung erzielt aufgrund einer speziellen GemV-Kernel-Implementierung die beste Leistung bei Batch-Größe 1. Insgesamt zeigt ONNX Runtime signifikante Leistungssteigerungen über verschiedene Batch-Größen und Prompt-Längen hinweg.
ONNX Runtime zeigt auch erhebliche Vorteile beim Training von LLMs, und diese Vorteile steigen typischerweise mit der Batch-Größe. Zum Beispiel ist ORT mit LoRA auf 2 A100-GPUs **1,2x schneller** als PyTorch Eager Mode und **1,5x schneller** als torch.compile für Phi-2. ORT zeigt auch Vorteile für andere LLMs wie Llama, Mistral und Orca-2 mit Kombinationen aus LoRA oder QLoRA.
Um mehr über die Verbesserung der Leistung generativer KI-Modelle mit ONNX Runtime 1.17 zu erfahren, lesen Sie unseren kürzlichen Beitrag im ONNX Runtime Blog: Beschleunigung von Phi-2, CodeLlama, Gemma und anderen Gen-KI-Modellen mit ONNX Runtime.
Training im Browser
On-Device-Training ermöglicht es Ihnen, das Benutzererlebnis für Entwickleranwendungen mit Gerätedaten zu verbessern. Es unterstützt Szenarien wie Federated Learning, bei dem ein globales Modell anhand von Daten auf dem Gerät trainiert wird. Mit der Version 1.17 ermöglicht ORT nun das Trainieren von Machine-Learning-Modellen im Browser mithilfe von On-Device-Training.
Um mehr über das Trainieren eines Modells im Browser mit On-Device-Training zu erfahren, lesen Sie diesen kürzlichen Beitrag im Microsoft Open Source Blog: On-Device-Training: Trainieren eines Modells im Browser.
DirectML NPU-Unterstützung
Mit der Veröffentlichung von DirectML 1.13.1 und ONNX Runtime 1.17 ist die Entwicklervorschau-Unterstützung für Neural Processing Unit (NPU)-Beschleunigung in DirectML, der Machine-Learning-Plattform-API für Windows, verfügbar. Diese Entwicklervorschau ermöglicht die Unterstützung einer Teilmenge von Modellen auf neuen Windows 11-Geräten mit Intel® Core™ Ultra Prozessoren mit Intel® AI Boost.
Um mehr über die NPU-Unterstützung in DirectML zu erfahren, lesen Sie diesen kürzlichen Beitrag im Windows Developer Blog: Einführung der Unterstützung für Neural Processor Unit (NPU) in DirectML (Entwicklervorschau).
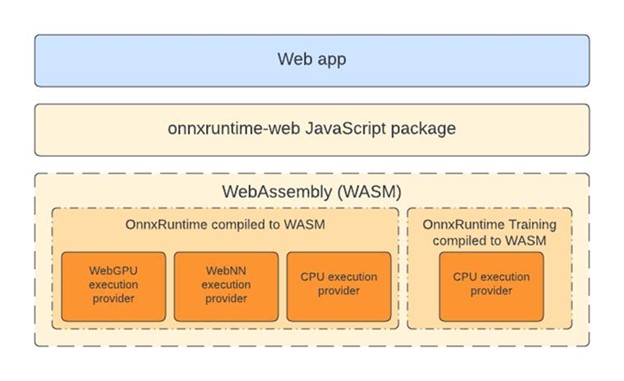
WebGPU mit ONNX Runtime Web
WebGPU ermöglicht es Webentwicklern, GPU-Hardware für Hochleistungsberechnungen zu nutzen. Die Veröffentlichung von ONNX Runtime 1.17 markiert den offiziellen Start des WebGPU-Ausführungsanbieters in ONNX Runtime Web, wodurch anspruchsvolle Modelle vollständig und effizient im Browser ausgeführt werden können (siehe die Liste der WebGPU-Browserkompatibilität). Dieser Fortschritt, demonstriert durch die effektive Ausführung von Modellen wie SD-Turbo, eröffnet neue Möglichkeiten in Szenarien, in denen CPU-basiertes In-Browser-Machine-Learning Schwierigkeiten hat, Leistungsstandards zu erfüllen.
Um mehr darüber zu erfahren, wie ONNX Runtime Web das In-Browser-Machine-Learning mit WebGPU weiter beschleunigt, lesen Sie unseren kürzlichen Beitrag im Microsoft Open Source Blog: ONNX Runtime Web entfesselt generative KI im Browser mithilfe von WebGPU.
YOLOv8 Pose Estimation-Szenario mit ONNX Runtime Mobile
Diese Version fügt Unterstützung für die Ausführung des YOLOv8-Modells zur Pose Estimation hinzu. Pose Estimation umfasst die Verarbeitung von Objekten, die in einem Bild erkannt wurden, und die Identifizierung der Position und Ausrichtung von Personen im Bild. Das Kern-YOLOv8-Modell gibt eine Reihe von Schlüsselpunkten zurück, die spezifische Teile des Körpers der erkannten Person darstellen, wie z. B. Gelenke und andere markante Merkmale. Die Einbeziehung der Vor- und Nachverarbeitung in das ONNX-Modell ermöglicht es Entwicklern, direkt ein Eingabebild entweder in gängigen Bildformaten oder als rohe RGB-Werte zu liefern und das Bild mit Bounding Boxes und Schlüsselpunkten auszugeben.
Um mehr darüber zu erfahren, wie man ONNX-Modelle auf Mobilgeräten mit integrierter Vor- und Nachverarbeitung für Objekterkennung und Pose Estimation erstellt und ausführt, lesen Sie unser kürzliches Tutorial in der ONNX Runtime Dokumentation: Objekterkennung und Pose Estimation mit YOLOv8.

CUDA 12 Pakete
Als Teil der 1.17-Veröffentlichung gewährleistet ONNX Runtime nun die Kompatibilität über mehrere Versionen des Nvidia CUDA Execution Providers hinweg, indem es CUDA 12-Pakete für Python und NuGet einführt. Mit dieser flexibleren Methodik erhalten Benutzer nun Zugang zu CUDA 11 und CUDA 12, was eine nahtlosere Integration von bahnbrechenden Hardwarebeschleunigungstechnologien ermöglicht.
Um CUDA 12 für ONNX Runtime GPU zu installieren, beachten Sie die Anweisungen in der ONNX Runtime Dokumentation: Installieren von ONNX Runtime GPU (CUDA 12.X).