ONNX Runtime Ausführungsprovider
ONNX Runtime arbeitet mit verschiedenen Hardwarebeschleunigungsbibliotheken über sein erweiterbares **Ausführungsprovider** (EP)-Framework zusammen, um ONNX-Modelle optimal auf der Hardwareplattform auszuführen. Diese Schnittstelle ermöglicht Flexibilität für den AP-Anwendungsentwickler, seine ONNX-Modelle in verschiedenen Umgebungen in der Cloud und am Edge bereitzustellen und die Ausführung zu optimieren, indem die Rechenkapazitäten der Plattform genutzt werden.
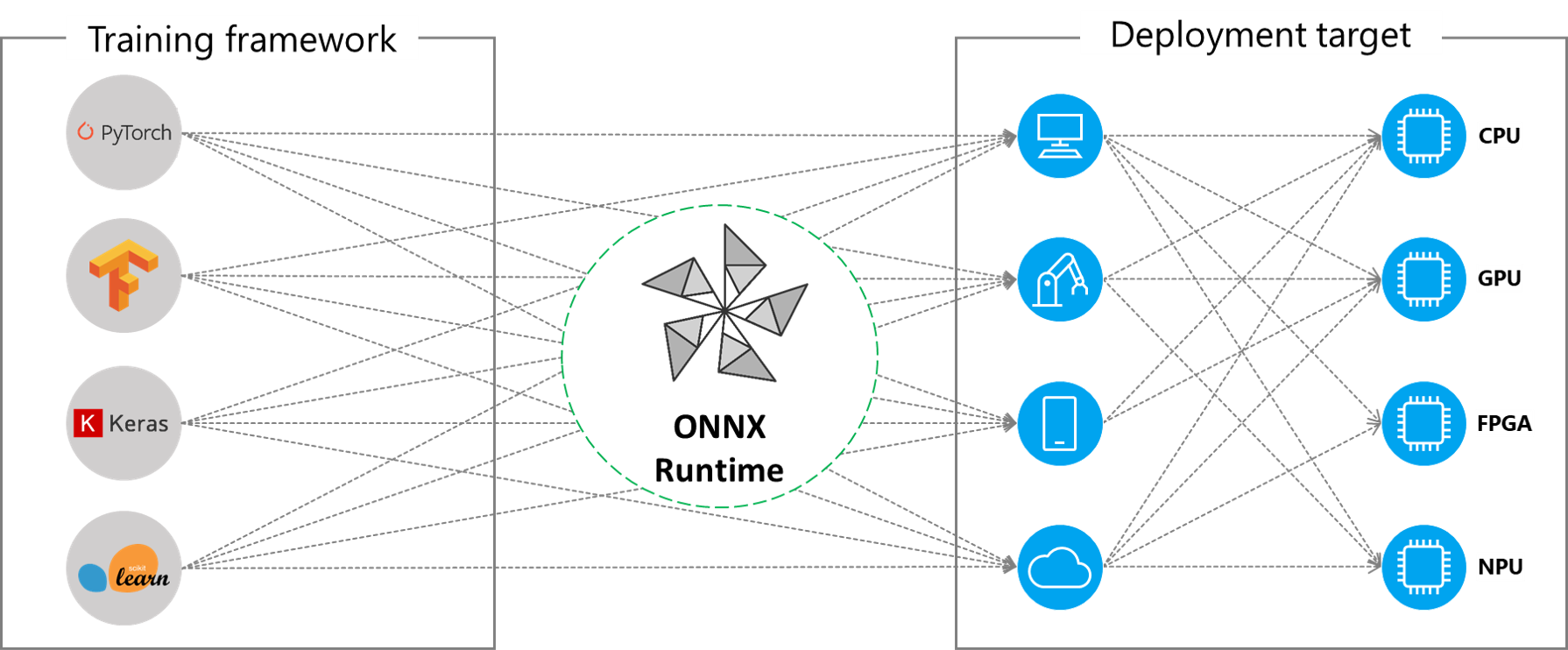
ONNX Runtime arbeitet mit dem/den Ausführungsprovider(n) über die GetCapability()-Schnittstelle zusammen, um bestimmte Knoten oder Teilgraphen für die Ausführung durch die EP-Bibliothek auf unterstützter Hardware zuzuweisen. Die EP-Bibliotheken, die in der Ausführungsumgebung vorinstalliert sind, verarbeiten und führen den ONNX-Teilgraph auf der Hardware aus. Diese Architektur abstrahiert die Details der hardware-spezifischen Bibliotheken, die für die Optimierung der Ausführung von Deep-Neural-Networks auf Hardwareplattformen wie CPU, GPU, FPGA oder spezialisierten NPUs unerlässlich sind.
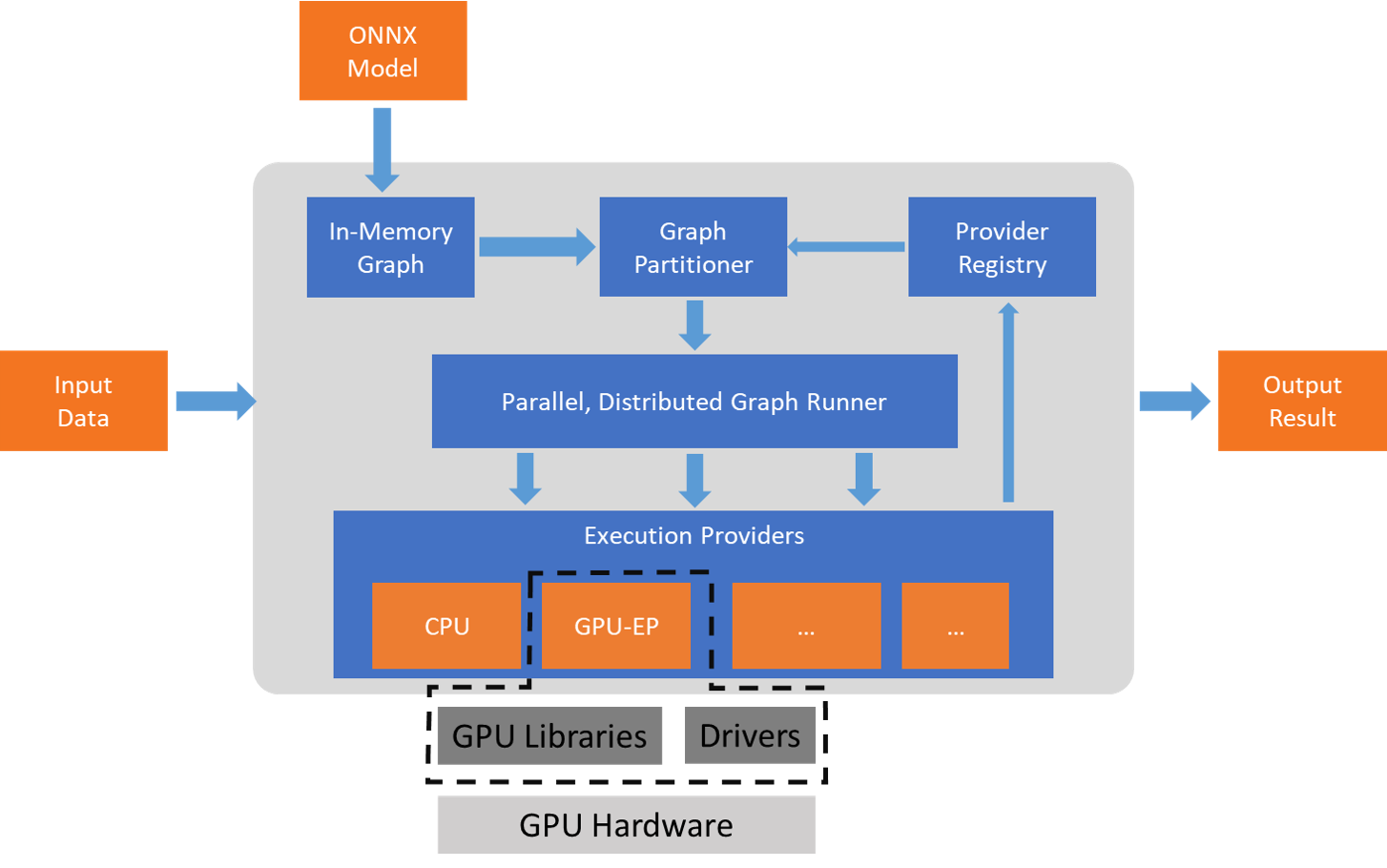
ONNX Runtime unterstützt heute viele verschiedene Ausführungsprovider. Einige der EPs sind für den Live-Betrieb in Produktion, während andere in der Vorschau veröffentlicht werden, um Entwicklern die Entwicklung und Anpassung ihrer Anwendungen mit den verschiedenen Optionen zu ermöglichen.
Zusammenfassung der unterstützten Ausführungsprovider
| CPU | GPU | IoT/Edge/Mobile | Andere |
|---|---|---|---|
| Standard-CPU | NVIDIA CUDA | Intel OpenVINO | Rockchip NPU (Vorschau) |
| Intel DNNL | NVIDIA TensorRT | Arm Compute Library (Vorschau) | Xilinx Vitis-AI (Vorschau) |
| TVM (Vorschau) | DirectML | Android Neural Networks API | Huawei CANN (Vorschau) |
| Intel OpenVINO | AMD MIGraphX | Arm NN (Vorschau) | AZURE (Vorschau) |
| XNNPACK | Intel OpenVINO | CoreML (Vorschau) | |
| AMD ROCm | TVM (Vorschau) | ||
| TVM (Vorschau) | Qualcomm QNN | ||
| XNNPACK |
Einen Ausführungsprovider hinzufügen
Entwickler von spezialisierten HW-Beschleunigungslösungen können sich in ONNX Runtime integrieren, um ONNX-Modelle auf ihrem Stack auszuführen. Um einen EP zur Schnittstellenbildung mit ONNX Runtime zu erstellen, müssen Sie zuerst einen eindeutigen Namen für den EP identifizieren. Siehe: Neuen Ausführungsprovider hinzufügen für detaillierte Anweisungen.
ONNX Runtime-Paket mit EPs erstellen
Das ONNX Runtime-Paket kann mit jeder Kombination von EPs zusammen mit dem Standard-CPU-Ausführungsprovider erstellt werden. **Beachten Sie**, dass bei Kombination mehrerer EPs im selben ONNX Runtime-Paket alle abhängigen Bibliotheken in der Ausführungsumgebung vorhanden sein müssen. Die Schritte zur Erstellung des ONNX Runtime-Pakets mit verschiedenen EPs sind hier dokumentiert.
APIs für Ausführungsprovider
Dieselbe ONNX Runtime-API wird für alle EPs verwendet. Dies bietet die konsistente Schnittstelle für Anwendungen, um mit verschiedenen HW-Beschleunigungsplattformen zu arbeiten. Die APIs zum Festlegen von EP-Optionen sind über Python, C/C++/C#, Java und Node.js verfügbar.
**Hinweis**: Wir aktualisieren unsere API-Unterstützung, um die Konsistenz über alle Sprachbindungen hinweg zu gewährleisten, und werden die Details hier aktualisieren.
`get_providers`: Return list of registered execution providers.
`get_provider_options`: Return the registered execution providers' configurations.
`set_providers`: Register the given list of execution providers. The underlying session is re-created.
The list of providers is ordered by Priority. For example ['CUDAExecutionProvider', 'CPUExecutionProvider']
means execute a node using CUDAExecutionProvider if capable, otherwise execute using CPUExecutionProvider.
Ausführungsprovider verwenden
import onnxruntime as rt
#define the priority order for the execution providers
# prefer CUDA Execution Provider over CPU Execution Provider
EP_list = ['CUDAExecutionProvider', 'CPUExecutionProvider']
# initialize the model.onnx
sess = rt.InferenceSession("model.onnx", providers=EP_list)
# get the outputs metadata as a list of :class:`onnxruntime.NodeArg`
output_name = sess.get_outputs()[0].name
# get the inputs metadata as a list of :class:`onnxruntime.NodeArg`
input_name = sess.get_inputs()[0].name
# inference run using image_data as the input to the model
detections = sess.run([output_name], {input_name: image_data})[0]
print("Output shape:", detections.shape)
# Process the image to mark the inference points
image = post.image_postprocess(original_image, input_size, detections)
image = Image.fromarray(image)
image.save("kite-with-objects.jpg")
# Update EP priority to only CPUExecutionProvider
sess.set_providers(['CPUExecutionProvider'])
cpu_detection = sess.run(...)