ONNX-Modelle quantisieren
Inhalt
- Quantisierung Übersicht
- ONNX-Quantisierungs-Darstellungsformat
- Ein ONNX-Modell quantisieren
- Transformer-basierte Modelle
- Quantisierung auf GPU
- Quantisieren auf Int4/UInt4
- FAQ
Quantisierung Übersicht
Quantisierung in ONNX Runtime bezieht sich auf die 8-Bit-Lineare-Quantisierung eines ONNX-Modells.
Während der Quantisierung werden die Gleitkommawerte auf einen 8-Bit-Quantisierungsraum abgebildet, der folgende Form hat: val_fp32 = scale * (val_quantized - zero_point)
scale ist eine positive reelle Zahl, die zur Abbildung der Gleitkommazahlen auf einen Quantisierungsraum verwendet wird. Sie wird wie folgt berechnet:
Für asymmetrische Quantisierung
scale = (data_range_max - data_range_min) / (quantization_range_max - quantization_range_min)
Für symmetrische Quantisierung
scale = max(abs(data_range_max), abs(data_range_min)) * 2 / (quantization_range_max - quantization_range_min)
zero_point repräsentiert Null im Quantisierungsraum. Es ist wichtig, dass der Gleitkomma-Nullwert im Quantisierungsraum exakt darstellbar ist. Das liegt daran, dass Zero-Padding in vielen CNNs verwendet wird. Wenn Null nach der Quantisierung nicht eindeutig darstellbar ist, führt dies zu Genauigkeitsfehlern.
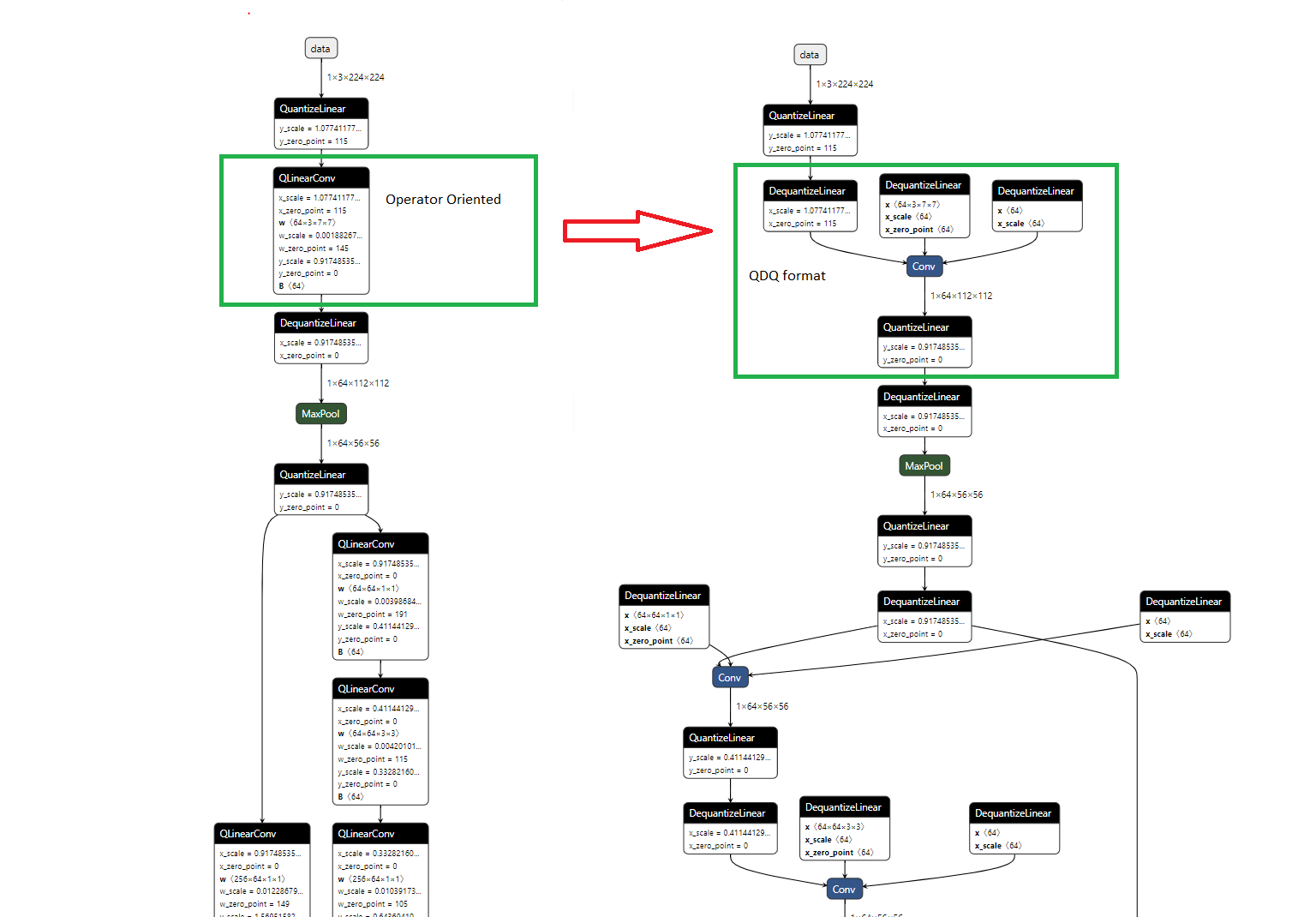
ONNX-Quantisierungs-Darstellungsformat
Es gibt zwei Möglichkeiten, quantisierte ONNX-Modelle darzustellen:
- Operator-orientiert (QOperator)
Alle quantisierten Operatoren haben ihre eigenen ONNX-Definitionen, wie QLinearConv, MatMulInteger usw. - Tensor-orientiert (QDQ; Quantize and DeQuantize)
Dieses Format fügt DeQuantizeLinear(QuantizeLinear(tensor)) zwischen die ursprünglichen Operatoren ein, um den Quantisierungs- und Dequantisierungsprozess zu simulieren.
Bei der statischen Quantisierung tragen die Operatoren QuantizeLinear und DeQuantizeLinear auch die Quantisierungsparameter.
Bei der dynamischen Quantisierung wird ein ComputeQuantizationParameters-Funktionsproto eingefügt, um die Quantisierungsparameter dynamisch zu berechnen. - Modelle, die auf folgende Weise generiert werden, liegen im QDQ-Format vor:
- Modelle, die mit quantize_static quantisiert wurden (weiter unten erklärt), mit
quant_format=QuantFormat.QDQ. - Quantization-Aware Training (QAT)-Modelle, die von Tensorflow konvertiert oder aus PyTorch exportiert wurden.
- Quantisierte Modelle, die von TFLite und anderen Frameworks konvertiert wurden.
- Modelle, die mit quantize_static quantisiert wurden (weiter unten erklärt), mit
Für die beiden letztgenannten Fälle müssen Sie das Modell nicht mit dem Quantisierungstool quantisieren. ONNX Runtime kann sie direkt als quantisiertes Modell ausführen.
Das folgende Bild zeigt die äquivalente Darstellung des QOperator- und QDQ-Formats für quantisierte Conv. Dieses End-to-End-Beispiel demonstriert die beiden Formate.
Ein ONNX-Modell quantisieren
ONNX Runtime bietet Python-APIs zur Konvertierung von 32-Bit-Gleitkommamodellen in 8-Bit-Integer-Modelle, auch bekannt als Quantisierung. Diese APIs umfassen Vorverarbeitung, dynamische/statische Quantisierung und Debugging.
Vorverarbeitung
Die Vorverarbeitung dient der Transformation eines Float32-Modells zur Vorbereitung auf die Quantisierung. Sie besteht aus den folgenden drei optionalen Schritten:
- Symbolische Forminferenz. Dies ist am besten für Transformer-Modelle geeignet.
- Modelloptimierung: Dieser Schritt verwendet die native ONNX Runtime-Bibliothek, um den Berechnungs-Graphen neu zu schreiben, einschließlich des Zusammenführens von Berechnungsknoten und der Eliminierung von Redundanzen zur Verbesserung der Laufzeiteffizienz.
- ONNX-Forminferenz.
Ziel dieser Schritte ist es, die Quantisierungsqualität zu verbessern. Unser Quantisierungstool funktioniert am besten, wenn die Form des Tensors bekannt ist. Sowohl die symbolische Forminferenz als auch die ONNX-Forminferenz helfen dabei, Tensorformen zu ermitteln. Die symbolische Forminferenz funktioniert am besten mit Transformer-basierten Modellen, während die ONNX-Forminferenz mit anderen Modellen funktioniert.
Die Modelloptimierung führt eine bestimmte Operator-Fusion durch, die die Arbeit des Quantisierungstools erleichtert. Zum Beispiel kann ein Convolution-Operator, gefolgt von BatchNormalization, zu einem zusammengeführt werden, der sehr effizient quantisiert werden kann.
Leider gibt es in ONNX Runtime ein bekanntes Problem, dass die Modelloptimierung kein Modell mit einer Größe von mehr als 2 GB ausgeben kann. Daher muss die Optimierung bei großen Modellen übersprungen werden.
Die Vorverarbeitungs-API befindet sich im Python-Modul onnxruntime.quantization.shape_inference, Funktion quant_pre_process(). Siehe shape_inference.py. Um zusätzliche Optionen und feinere Kontrollen für die Vorverarbeitung zu lesen, führen Sie den folgenden Befehl aus:
python -m onnxruntime.quantization.preprocess --help
Die Modelloptimierung kann auch während der Quantisierung durchgeführt werden. Dies wird jedoch **nicht** empfohlen, auch wenn es aus historischen Gründen das Standardverhalten ist. Die Modelloptimierung während der Quantisierung erschwert das Debugging von Genauigkeitsverlusten, die durch die Quantisierung verursacht werden und die in späteren Abschnitten erörtert werden. Daher ist es am besten, die Modelloptimierung während der Vorverarbeitung und nicht während der Quantisierung durchzuführen.
Dynamische Quantisierung
Es gibt zwei Möglichkeiten, ein Modell zu quantisieren: dynamisch und statisch. Die dynamische Quantisierung berechnet die Quantisierungsparameter (Skalierung und Nullpunkt) für Aktivierungen dynamisch. Diese Berechnungen erhöhen den Inferenzaufwand, erzielen aber normalerweise eine höhere Genauigkeit im Vergleich zu statischen.
Die Python-API für die dynamische Quantisierung befindet sich im Modul onnxruntime.quantization.quantize, Funktion quantize_dynamic()
Statische Quantisierung
Die Methode der statischen Quantisierung führt das Modell zunächst mit einer Reihe von Eingaben, den sogenannten Kalibrierungsdaten, aus. Während dieser Läufe berechnen wir die Quantisierungsparameter für jede Aktivierung. Diese Quantisierungsparameter werden als Konstanten in das quantisierte Modell geschrieben und für alle Eingaben verwendet. Unser Quantisierungstool unterstützt drei Kalibrierungsmethoden: MinMax, Entropy und Percentile. Weitere Details finden Sie in calibrate.py.
Die Python-API für die statische Quantisierung befindet sich im Modul onnxruntime.quantization.quantize, Funktion quantize_static(). Details finden Sie unter quantize.py.
Quantisierungs-Debugging
Quantisierung ist keine verlustfreie Transformation. Sie kann die Genauigkeit eines Modells negativ beeinflussen. Eine Lösung für dieses Problem besteht darin, die Gewichts- und Aktivierungstensoren des ursprünglichen Berechnungs-Graphen mit denen des quantisierten zu vergleichen, festzustellen, wo sie sich am meisten unterscheiden, und diese Tensoren nicht zu quantisieren oder eine andere Quantisierungs-/Kalibrierungsmethode zu wählen. Dies wird als Quantisierungs-Debugging bezeichnet. Um diesen Prozess zu erleichtern, stellen wir Python-APIs zum Abgleichen von Gewichts- und Aktivierungstensoren zwischen einem Float32-Modell und seinem quantisierten Gegenstück bereit.
Die API für das Debugging befindet sich im Modul onnxruntime.quantization.qdq_loss_debug, das die folgenden Funktionen enthält:
- Funktion
create_weight_matching(). Sie nimmt ein Float32-Modell und sein quantisiertes Modell entgegen und gibt ein Wörterbuch aus, das die entsprechenden Gewichte zwischen diesen beiden Modellen abgleicht. - Funktion
modify_model_output_intermediate_tensors(). Sie nimmt ein Float32- oder quantisiertes Modell entgegen und erweitert es so, dass alle seine Aktivierungen gespeichert werden. - Funktion
collect_activations(). Sie nimmt ein vonmodify_model_output_intermediate_tensors()erweitertes Modell und einen Eingabedatenleser entgegen, führt das erweiterte Modell aus, um alle Aktivierungen zu sammeln. - Funktion
create_activation_matching(). Sie können sich vorstellen, dass Siecollect_activations(modify_model_output_intermediate_tensors())sowohl für das Float32-Modell als auch für sein quantisiertes Modell ausführen, um zwei Aktivierungssätze zu sammeln. Diese Funktion nimmt diese beiden Aktivierungssätze entgegen und gleicht entsprechende ab, damit sie vom Benutzer leicht verglichen werden können.
Zusammenfassend lässt sich sagen, dass ONNX Runtimes Python-APIs zum Abgleichen entsprechender Gewichts- und Aktivierungstensoren zwischen einem Float32-Modell und seinem quantisierten Gegenstück bereitstellt. Dies ermöglicht dem Benutzer, sie leicht zu vergleichen, um die größten Unterschiede zu lokalisieren.
Die Modelloptimierung während der Quantisierung erschwert diesen Debugging-Prozess, da sie den Berechnungs-Graphen erheblich verändern kann, was zu einem quantisierten Modell führt, das sich stark vom Original unterscheidet. Dies erschwert das Abgleichen von entsprechenden Tensoren aus den beiden Modellen. Daher empfehlen wir, die Modelloptimierung während der Vorverarbeitung anstelle des Quantisierungsprozesses durchzuführen.
Beispiel
- Dynamische Quantisierung
import onnx
from onnxruntime.quantization import quantize_dynamic, QuantType
model_fp32 = 'path/to/the/model.onnx'
model_quant = 'path/to/the/model.quant.onnx'
quantized_model = quantize_dynamic(model_fp32, model_quant)
- Statische Quantisierung: Bitte beachten Sie die End-to-End-Beispiele.
Methodenauswahl
Der Hauptunterschied zwischen dynamischer und statischer Quantisierung liegt in der Berechnung der Skalierung und des Nullpunkts von Aktivierungen. Bei der statischen Quantisierung werden sie im Voraus (offline) mithilfe eines Kalibrierungsdatensatzes berechnet. Die Aktivierungen haben somit während jedes Forward-Passes dieselbe Skalierung und denselben Nullpunkt. Bei der dynamischen Quantisierung werden sie dynamisch (online) berechnet und sind für jeden Forward-Pass spezifisch. Sie sind daher genauer, verursachen aber zusätzlichen Rechenaufwand.
Im Allgemeinen wird empfohlen, dynamische Quantisierung für RNNs und Transformer-basierte Modelle und statische Quantisierung für CNN-Modelle zu verwenden.
Wenn keine der Post-Training-Quantisierungsmethoden Ihr Genauigkeitsziel erreicht, können Sie versuchen, Quantization-Aware Training (QAT) zu verwenden, um das Modell neu zu trainieren. ONNX Runtime bietet derzeit kein Retraining an, aber Sie können Ihre Modelle mit dem ursprünglichen Framework neu trainieren und sie zurück in ONNX konvertieren.
Datentyptauswahl
Die quantisierten Werte sind 8 Bit breit und können entweder vorzeichenbehaftet (int8) oder vorzeichenlos (uint8) sein. Wir können die Vorzeichen von Aktivierungen und Gewichten getrennt wählen, sodass das Datenformat (Aktivierungen: uint8, Gewichte: uint8), (Aktivierungen: uint8, Gewichte: int8) usw. sein kann. Verwenden wir U8U8 als Kurzform für (Aktivierungen: uint8, Gewichte: uint8), U8S8 für (Aktivierungen: uint8, Gewichte: int8) und ähnlich S8U8 und S8S8 für die verbleibenden zwei Formate.
ONNX Runtime-Quantisierung auf der CPU kann U8U8, U8S8 und S8S8 ausführen. S8S8 mit QDQ ist die Standardeinstellung und bietet ein Gleichgewicht zwischen Leistung und Genauigkeit. Es sollte die erste Wahl sein. Nur in Fällen, in denen die Genauigkeit stark abfällt, können Sie U8U8 versuchen. Beachten Sie, dass S8S8 mit QOperator auf x86-64-CPUs langsam ist und im Allgemeinen vermieden werden sollte. ONNX Runtime-Quantisierung auf der GPU unterstützt nur S8S8.
Wann und warum sollte ich U8U8 ausprobieren?
Auf x86-64-Maschinen mit AVX2- und AVX512-Erweiterungen verwendet ONNX Runtime die VPMADDUBSW-Instruktion für U8S8 zur Leistungssteigerung. Diese Instruktion kann Probleme mit Sättigung haben: Es kann vorkommen, dass die Ausgabe nicht in einen 16-Bit-Integer passt und geklemmt (gesättigt) werden muss, um zu passen. Im Allgemeinen ist dies kein großes Problem für das Endergebnis. Wenn Sie jedoch einen großen Genauigkeitsabfall feststellen, kann dieser durch Sättigung verursacht werden. In diesem Fall können Sie entweder versuchen, reduce_range zu verwenden oder das U8U8-Format, das keine Sättigungsprobleme aufweist.
Auf anderen CPU-Architekturen (x64 mit VNNI und Arm®) gibt es kein solches Problem.
Liste unterstützter quantisierter Operatoren
Bitte beachten Sie das Registry für die Liste der unterstützten Operatoren.
Quantisierung und Modell-Opset-Versionen
Modelle müssen mindestens Opset 10 haben, um quantisiert werden zu können. Modelle mit Opset < 10 müssen aus ihrem ursprünglichen Framework mit einem späteren Opset neu in ONNX konvertiert werden.
Transformer-basierte Modelle
Es gibt spezielle Optimierungen für Transformer-basierte Modelle, wie z. B. QAttention für die Quantisierung von Attention-Schichten. Um diese Optimierungen nutzen zu können, müssen Sie Ihre Modelle mit dem Transformer Model Optimization Tool optimieren, bevor Sie das Modell quantisieren.
Dieses Notebook demonstriert den Prozess.
Quantisierung auf GPU
Hardwareunterstützung ist erforderlich, um eine bessere Leistung bei der Quantisierung auf GPUs zu erzielen. Sie benötigen ein Gerät, das Tensor-Core-Int8-Berechnungen unterstützt, wie z. B. T4 oder A100. Ältere Hardware profitiert nicht von der Quantisierung.
ONNX Runtime nutzt nun den TensorRT Execution Provider für die Quantisierung auf GPU. Im Gegensatz zum CPU Execution Provider nimmt TensorRT ein Modell in voller Präzision und ein Kalibrierungsergebnis für Eingaben entgegen. Es entscheidet, wie es mit eigener Logik quantisiert. Der allgemeine Ablauf zur Nutzung der TensorRT EP-Quantisierung ist:
- Implementieren Sie einen CalibrationDataReader.
- Berechnen Sie die Quantisierungsparameter mithilfe eines Kalibrierungsdatensatzes. Hinweis: Um alle Tensoren aus dem Modell für eine bessere Kalibrierung einzubeziehen, führen Sie zuerst
symbolic_shape_infer.pyaus. Weitere Informationen finden Sie hier. - Speichern Sie die Quantisierungsparameter in einer Flatbuffer-Datei
- Laden Sie das Modell und die Quantisierungsparameterdatei und führen Sie sie mit dem TensorRT EP aus.
Wir stellen zwei End-to-End-Beispiele bereit: Yolo V3 und resnet50.
Quantisieren auf Int4/UInt4
ONNX Runtime kann bestimmte Operatoren in einem Modell auf 4-Bit-Integer-Typen quantisieren. Eine Block-weise reine Gewichtsquantisierung wird auf die Operatoren angewendet. Die unterstützten Operatortypen sind:
- MatMul:
- Der Knoten wird nur quantisiert, wenn die Eingabe
Bkonstant ist. - Unterstützt QOperator- oder QDQ-Format.
- Wenn QOperator ausgewählt ist, wird der Knoten in einen MatMulNBits-Knoten umgewandelt. Das Gewicht
Bwird blockweise quantisiert und im neuen Knoten gespeichert. Die Algorithmen HQQ, GPTQ und RTN (Standard) werden unterstützt. - Wenn QDQ ausgewählt ist, wird der MatMul-Knoten durch ein DequantizeLinear -> MatMul-Paar ersetzt. Das Gewicht
Bwird blockweise quantisiert und im DequantizeLinear-Knoten als Initialisierer gespeichert.
- Der Knoten wird nur quantisiert, wenn die Eingabe
- Sammeln:
- Der Knoten wird nur quantisiert, wenn die Eingabe
datakonstant ist. - Unterstützt QOperator
- Gather wird zu einem GatherBlockQuantized-Knoten quantisiert. Die Eingabe
datawird blockweise quantisiert und im neuen Knoten gespeichert. Unterstützt nur das RTN-Algorithmus.
- Der Knoten wird nur quantisiert, wenn die Eingabe
Da Int4/UInt4-Typen in ONNX Opset 21 eingeführt wurden, wird die ONNX-Domänenversion des Modells, falls sie < 21 ist, auf Opset 21 hochgestuft. Bitte stellen Sie sicher, dass die Operatoren im Modell mit ONNX Opset 21 kompatibel sind.
Um ein Modell mit GatherBlockQuantized-Knoten auszuführen, wird ONNX Runtime 1.20 benötigt.
Codebeispiele
from onnxruntime.quantization import (
matmul_4bits_quantizer,
quant_utils,
quantize
)
from pathlib import Path
model_fp32_path="path/to/orignal/model.onnx"
model_int4_path="path/to/save/quantized/model.onnx"
quant_config = matmul_4bits_quantizer.DefaultWeightOnlyQuantConfig(
block_size=128, # 2's exponential and >= 16
is_symmetric=True, # if true, quantize to Int4. otherwise, quantize to uint4.
accuracy_level=4, # used by MatMulNbits, see https://github.com/microsoft/onnxruntime/blob/main/docs/ContribOperators.md#attributes-35
quant_format=quant_utils.QuantFormat.QOperator,
op_types_to_quantize=("MatMul","Gather"), # specify which op types to quantize
quant_axes=(("MatMul", 0), ("Gather", 1),) # specify which axis to quantize for an op type.
model = quant_utils.load_model_with_shape_infer(Path(model_fp32_path))
quant = matmul_4bits_quantizer.MatMul4BitsQuantizer(
model,
nodes_to_exclude=None, # specify a list of nodes to exclude from quantization
nodes_to_include=None, # specify a list of nodes to force include from quantization
algo_config=quant_config,)
quant.process()
quant.model.save_model_to_file(
model_int4_path,
True) # save data to external file
Für die Verwendung der AWQ- und GPTQ-Quantisierung beachten Sie bitte den Gen-AI Model Builder.
FAQ
Warum sehe ich keine Leistungsverbesserungen?
Die Leistungsverbesserung hängt von Ihrem Modell und Ihrer Hardware ab. Der Leistungsgewinn durch Quantisierung hat zwei Aspekte: Berechnung und Speicher. Alte Hardware hat keine oder nur wenige der erforderlichen Anweisungen, um eine effiziente Inferenz in INT8 durchzuführen. Und die Quantisierung hat einen Overhead (durch Quantisierung und Dequantisierung), daher ist es nicht ungewöhnlich, auf älteren Geräten eine schlechtere Leistung zu erzielen.
x86-64 mit VNNI, GPUs mit Tensor-Core-INT8-Unterstützung und ARM®-basierte Prozessoren mit Dot-Product-Instruktionen können im Allgemeinen eine bessere Leistung erzielen.
Welche Quantisierungsmethode sollte ich wählen, dynamisch oder statisch?
Bitte beachten Sie den Abschnitt Methodenauswahl.
Wann sollten Reduce-Range und Per-Channel-Quantisierung verwendet werden?
Reduce-Range quantisiert die Gewichte auf 7 Bit. Es ist für das U8S8-Format auf AVX2- und AVX512- (nicht VNNI) Maschinen konzipiert, um Sättigungsprobleme zu mildern. Dies ist auf Maschinen mit VNNI-Unterstützung nicht erforderlich.
Per-Channel-Quantisierung kann die Genauigkeit von Modellen mit großen Gewichtsbereichen verbessern. Probieren Sie es aus, wenn der Genauigkeitsverlust groß ist. Auf AVX2- und AVX512-Maschinen müssen Sie im Allgemeinen auch Reduce-Range aktivieren, wenn Per-Channel aktiviert ist.
Warum werden Operatoren wie MaxPool nicht quantisiert?
Die Unterstützung für 8-Bit-Datentypen für bestimmte Operatoren wie MaxPool wurde in ONNX Opset 12 hinzugefügt. Bitte überprüfen Sie Ihre Modellversion und aktualisieren Sie sie auf Opset 12 oder höher.