Hochleistungsfähiges Frage-Antwort-Modell mit ONNX Runtime auf AzureML bereitstellen
Dieses Tutorial verwendet ein BERT-Modell von HuggingFace, konvertiert es in ONNX und stellt das ONNX-Modell mit ONNX Runtime über AzureML bereit.
In den folgenden Abschnitten verwenden wir als Beispiel das HuggingFace BERT-Modell, das mit dem Stanford Question Answering Dataset (SQuAD) trainiert wurde. Sie können auch Ihr eigenes Frage-Antwort-Modell trainieren oder feinabstimmen.
Das Frage-Antwort-Szenario nimmt eine Frage und einen Textabschnitt (Kontext) entgegen und liefert eine Antwort, die ein aus dem Kontext entnommener Textstring ist. Dieses Szenario tokenisiert und kodiert die Frage und den Kontext, speist die Eingaben in das Transformer-Modell und generiert die Antwort, indem es die wahrscheinlichsten Start- und End-Tokens im Kontext erzeugt, die dann wieder in Wörter zurückgeführt werden.
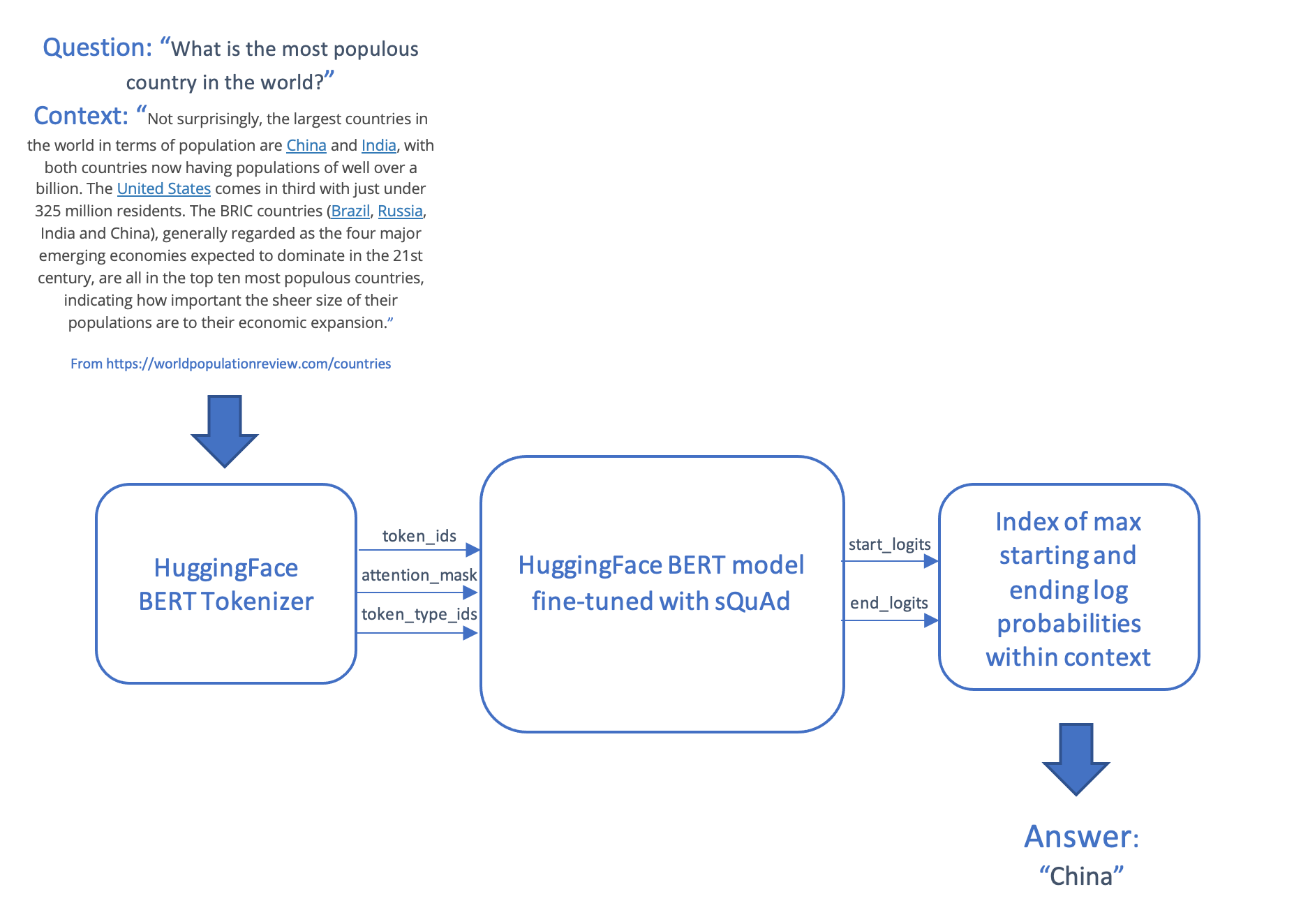
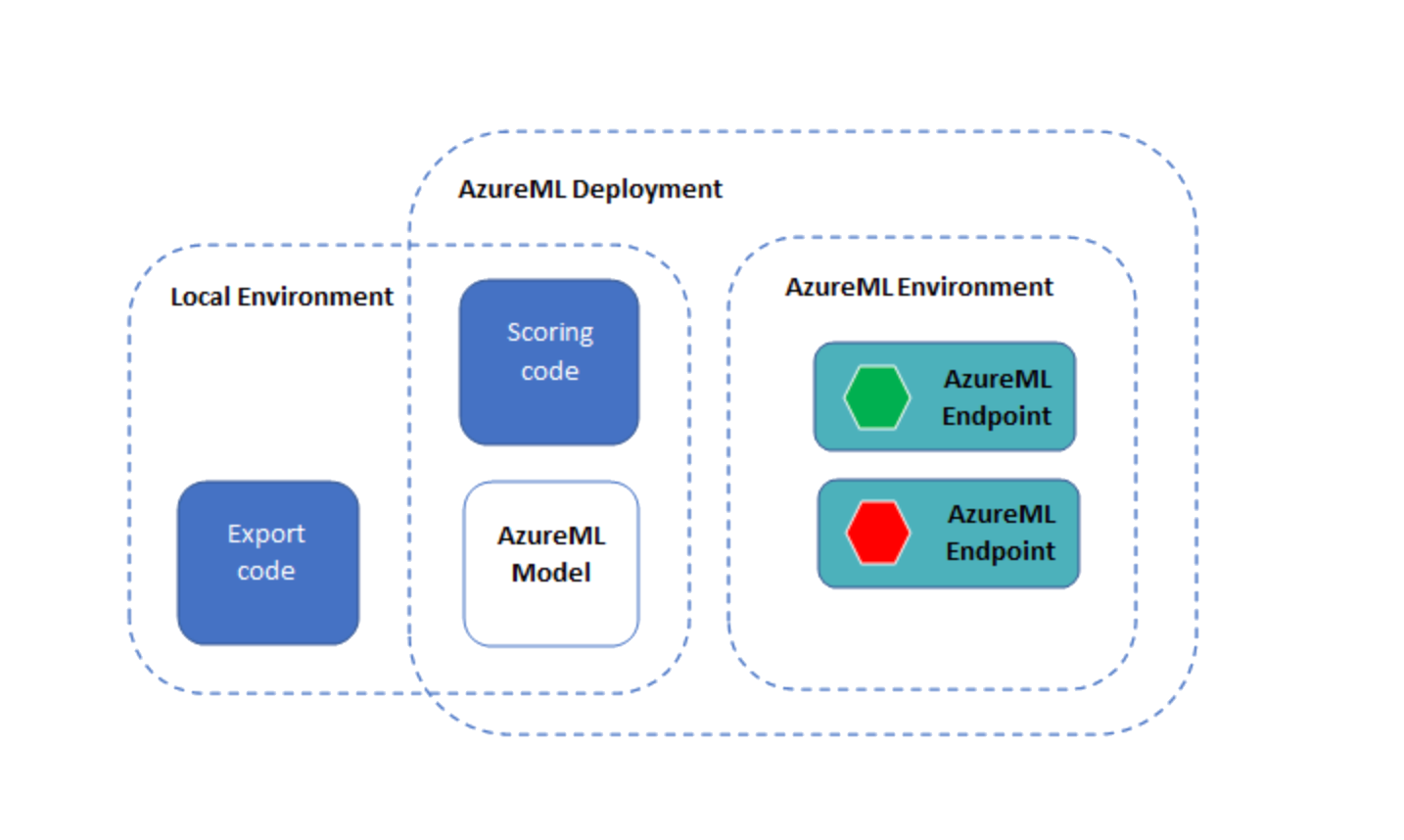
Das Modell und der Scoring-Code werden dann über einen Online-Endpunkt auf AzureML bereitgestellt.
Inhalt
- Voraussetzungen
- Umgebung
- PyTorch-Modell abrufen und in das ONNX-Format konvertieren
- Modell mit ONNX Runtime über AzureML bereitstellen
Voraussetzungen
Der Quellcode für dieses Tutorial ist auf GitHub veröffentlicht.
Um auf AzureML ausführen zu können, benötigen Sie
- ein Azure-Abonnement
- einen Azure Machine Learning Workspace (siehe das AzureML-Konfigurations-Notebook zur Erstellung des Workspaces, falls Sie noch keinen haben)
- das Azure Machine Learning SDK
- die Azure CLI und die Azure Machine Learning CLI-Erweiterung (> Version 2.2.2)
Folgende Ressourcen könnten ebenfalls nützlich sein
- Verständnis der von Azure Machine Learning eingeführten Architektur und Begriffe
- Das Azure Portal ermöglicht es Ihnen, den Status Ihrer Bereitstellungen zu verfolgen.
Wenn Sie keinen Zugriff auf ein AzureML-Abonnement haben, können Sie dieses Tutorial lokal ausführen.
Umgebung
Um Abhängigkeiten zu installieren, führen Sie Folgendes aus
pip install torch
pip install transformers
pip install azureml azureml.core
pip install onnxruntime
pip install matplotlib
Um einen Jupyter-Kernel aus Ihrer Conda-Umgebung zu erstellen, führen Sie Folgendes aus. Ersetzen Sie
conda install -c anaconda ipykernel
python -m ipykernel install --user --name=<kernel name>
Installieren Sie die AzureML CLI-Erweiterung, die in den folgenden Bereitstellungsschritten verwendet wird
az login
az extension add --name ml
# Remove the azure-cli-ml extension if it is installed, as it is not compatible with the az ml extension
az extension remove azure-cli-ml
PyTorch-Modell abrufen und in das ONNX-Format konvertieren
Im folgenden Code rufen wir ein BERT-Modell ab, das für die Beantwortung von Fragen mit dem SQUAD-Datensatz von HuggingFace feinabgestimmt wurde.
Wenn Sie ein BERT-Modell von Grund auf vortrainieren möchten, folgen Sie den Anweisungen in BERT-Modell vortrainieren. Und wenn Sie das Modell mit Ihren eigenen Daten feinabstimmen möchten, beziehen Sie sich auf AzureML BERT Eval Squad oder AzureML BERT Eval GLUE.
Modell exportieren
Verwenden Sie den PyTorch ONNX-Exporter, um ein Modell im ONNX-Format zu erstellen, das mit ONNX Runtime ausgeführt werden soll.
import torch
from transformers import BertForQuestionAnswering
model_name = "bert-large-uncased-whole-word-masking-finetuned-squad"
model_path = "./" + model_name + ".onnx"
model = BertForQuestionAnswering.from_pretrained(model_name)
# set the model to inference mode
# It is important to call torch_model.eval() or torch_model.train(False) before exporting the model,
# to turn the model to inference mode. This is required since operators like dropout or batchnorm
# behave differently in inference and training mode.
model.eval()
# Generate dummy inputs to the model. Adjust if necessary
inputs = {
'input_ids': torch.randint(32, [1, 32], dtype=torch.long), # list of numerical ids for the tokenized text
'attention_mask': torch.ones([1, 32], dtype=torch.long), # dummy list of ones
'token_type_ids': torch.ones([1, 32], dtype=torch.long) # dummy list of ones
}
symbolic_names = {0: 'batch_size', 1: 'max_seq_len'}
torch.onnx.export(model, # model being run
(inputs['input_ids'],
inputs['attention_mask'],
inputs['token_type_ids']), # model input (or a tuple for multiple inputs)
model_path, # where to save the model (can be a file or file-like object)
opset_version=11, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names=['input_ids',
'input_mask',
'segment_ids'], # the model's input names
output_names=['start_logits', "end_logits"], # the model's output names
dynamic_axes={'input_ids': symbolic_names,
'input_mask' : symbolic_names,
'segment_ids' : symbolic_names,
'start_logits' : symbolic_names,
'end_logits': symbolic_names}) # variable length axes
ONNX-Modell mit ONNX Runtime ausführen
Der folgende Code führt das ONNX-Modell mit ONNX Runtime aus. Sie können es lokal testen, bevor Sie es in Azure Machine Learning bereitstellen.
Die Funktion init() wird beim Start aufgerufen und führt einmalige Operationen durch, wie z. B. die Erstellung des Tokenizers und der ONNX Runtime-Sitzung.
Die Funktion run() wird aufgerufen, wenn wir das Modell über den Azure ML-Endpunkt ausführen. Fügen Sie notwendige preprocess()- und postprocess()-Schritte hinzu.
Zum lokalen Testen und Vergleichen können Sie auch das PyTorch-Modell ausführen.
import os
import logging
import json
import numpy as np
import onnxruntime
import transformers
import torch
# The pre process function take a question and a context, and generates the tensor inputs to the model:
# - input_ids: the words in the question encoded as integers
# - attention_mask: not used in this model
# - token_type_ids: a list of 0s and 1s that distinguish between the words of the question and the words of the context
# This function also returns the words contained in the question and the context, so that the answer can be decoded into a phrase.
def preprocess(question, context):
encoded_input = tokenizer(question, context)
tokens = tokenizer.convert_ids_to_tokens(encoded_input.input_ids)
return (encoded_input.input_ids, encoded_input.attention_mask, encoded_input.token_type_ids, tokens)
# The post process function maps the list of start and end log probabilities onto a text answer, using the text tokens from the question
# and context.
def postprocess(tokens, start, end):
results = {}
answer_start = np.argmax(start)
answer_end = np.argmax(end)
if answer_end >= answer_start:
answer = tokens[answer_start]
for i in range(answer_start+1, answer_end+1):
if tokens[i][0:2] == "##":
answer += tokens[i][2:]
else:
answer += " " + tokens[i]
results['answer'] = answer.capitalize()
else:
results['error'] = "I am unable to find the answer to this question. Can you please ask another question?"
return results
# Perform the one-off initialization for the prediction. The init code is run once when the endpoint is setup.
def init():
global tokenizer, session, model
model_name = "bert-large-uncased-whole-word-masking-finetuned-squad"
model = transformers.BertForQuestionAnswering.from_pretrained(model_name)
# use AZUREML_MODEL_DIR to get your deployed model(s). If multiple models are deployed,
# model_path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), '$MODEL_NAME/$VERSION/$MODEL_FILE_NAME')
model_dir = os.getenv('AZUREML_MODEL_DIR')
if model_dir == None:
model_dir = "./"
model_path = os.path.join(model_dir, model_name + ".onnx")
# Create the tokenizer
tokenizer = transformers.BertTokenizer.from_pretrained(model_name)
# Create an ONNX Runtime session to run the ONNX model
session = onnxruntime.InferenceSession(model_path, providers=["CPUExecutionProvider"])
# Run the PyTorch model, for functional and performance comparison
def run_pytorch(raw_data):
inputs = json.loads(raw_data)
model.eval()
logging.info("Question:", inputs["question"])
logging.info("Context: ", inputs["context"])
input_ids, input_mask, segment_ids, tokens = preprocess(inputs["question"], inputs["context"])
model_outputs = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([segment_ids]))
return postprocess(tokens, model_outputs.start_logits.detach().numpy(), model_outputs.end_logits.detach().numpy())
# Run the ONNX model with ONNX Runtime
def run(raw_data):
logging.info("Request received")
inputs = json.loads(raw_data)
logging.info(inputs)
# Preprocess the question and context into tokenized ids
input_ids, input_mask, segment_ids, tokens = preprocess(inputs["question"], inputs["context"])
logging.info("Running inference")
# Format the inputs for ONNX Runtime
model_inputs = {
'input_ids': [input_ids],
'input_mask': [input_mask],
'segment_ids': [segment_ids]
}
outputs = session.run(['start_logits', 'end_logits'], model_inputs)
logging.info("Post-processing")
# Post process the output of the model into an answer (or an error if the question could not be answered)
results = postprocess(tokens, outputs[0], outputs[1])
logging.info(results)
return results
if __name__ == '__main__':
init()
input = "{\"question\": \"What is Dolly Parton's middle name?\", \"context\": \"Dolly Rebecca Parton is an American singer-songwriter\"}"
run_pytorch(input)
print(run(input))
Modell mit ONNX Runtime über AzureML bereitstellen
Nachdem wir nun das ONNX-Modell und den Code zum Ausführen mit ONNX Runtime haben, können wir es mit Azure ML bereitstellen.
Umgebung überprüfen
import azureml.core
import onnxruntime
import torch
import transformers
print("Transformers version: ", transformers.__version__)
torch_version = torch.__version__
print("Torch (ONNX exporter) version: ", torch_version)
print("Azure SDK version:", azureml.core.VERSION)
print("ONNX Runtime version: ", onnxruntime.__version__)
Azure ML Workspace laden
Wir beginnen mit der Instanziierung eines Workspace-Objekts aus dem bestehenden Workspace, der zuvor im Konfigurations-Notebook erstellt wurde.
Beachten Sie, dass der folgende Code davon ausgeht, dass Sie eine config.json-Datei mit den Abonnementinformationen im selben Verzeichnis wie das Notebook oder in einem Unterverzeichnis namens .azureml haben. Sie können auch den Workspace-Namen, den Abonnementnamen und die Ressourcengruppe explizit über die Methode Workspace.get() angeben.
import os
from azureml.core import Workspace
ws = Workspace.from_config()
print(ws.name, ws.location, ws.resource_group, ws.subscription_id, sep = '\n')
Register your model with Azure ML
Now we upload the model and register it in the workspace.
from azureml.core.model import Model
model = Model.register(model_path = model_path, # Name of the registered model in your workspace.
model_name = model_name, # Local ONNX model to upload and register as a model
model_framework=Model.Framework.ONNX , # Framework used to create the model.
model_framework_version=torch_version, # Version of ONNX used to create the model.
tags = {"onnx": "demo"},
description = "HuggingFace BERT model fine-tuned with SQuAd and exported from PyTorch",
workspace = ws)
Registrierte Modelle anzeigen
Sie können alle Modelle auflisten, die Sie in diesem Workspace registriert haben.
models = ws.models
for name, m in models.items():
print("Name:", name,"\tVersion:", m.version, "\tDescription:", m.description, m.tags)
# # If you'd like to delete the models from workspace
# model_to_delete = Model(ws, name)
# model_to_delete.delete()
Modell und Scoring-Code als AzureML-Endpunkt bereitstellen
Hinweis: Die Endpunkt-Schnittstelle des Python SDK wurde noch nicht öffentlich veröffentlicht, daher verwenden wir für diesen Abschnitt die Azure ML CLI.
Es gibt drei YML-Dateien im Ordner yml
env.yml: Eine Spezifikation für die Conda-Umgebung, aus der die Ausführungsumgebung des Endpunkts generiert wirdendpoint.yml: Die Endpunktspezifikation, die einfach den Namen des Endpunkts und die Autorisierungsmethode enthältdeployment.yml: Die Bereitstellungsspezifikation, die Spezifikationen für den Scoring-Code, das Modell und die Umgebung enthält. Sie können mehrere Bereitstellungen pro Endpunkt erstellen und unterschiedliche Mengen an Datenverkehr an die Bereitstellungen leiten. Für dieses Beispiel erstellen wir nur eine Bereitstellung.
Die Bereitstellung kann bis zu 15 Minuten dauern. Beachten Sie auch, dass alle Dateien im Verzeichnis mit dem Notebook in den Docker-Container hochgeladen werden, der die Basis Ihres Endpunkts bildet, einschließlich aller lokalen Kopien des ONNX-Modells (das bereits im vorherigen Schritt auf AzureML bereitgestellt wurde). Um die Bereitstellungszeit zu verkürzen, entfernen Sie alle lokalen Kopien großer Dateien, bevor Sie den Endpunkt erstellen.
az ml online-endpoint create --name question-answer-ort --file yml/endpoint.yml --subscription {ws.subscription_id} --resource-group {ws.resource_group} --workspace-name {ws.name}
az ml online-deployment create --endpoint-name question-answer-ort --name blue --file yml/deployment.yml --all-traffic --subscription {ws.subscription_id} --resource-group {ws.resource_group} --workspace-name {ws.name}
Bereitgestellten Endpunkt testen
Der folgende Befehl führt das bereitgestellte Frage-Antwort-Modell aus. Es gibt eine Testfrage in der Datei test-data.json. Sie können diese Datei mit Ihrer eigenen Frage und Ihrem Kontext bearbeiten.
az ml online-endpoint invoke --name question-answer-ort --request-file test-data.json --subscription {ws.subscription_id} --resource-group {ws.resource_group} --workspace-name {ws.name}
Wenn Sie es bis hierher geschafft haben, haben Sie einen funktionierenden Endpunkt bereitgestellt, der eine Frage mit einem ONNX-Modell beantwortet.
Sie können Ihre eigenen Fragen und Kontexte angeben, um eine Frage zu beantworten!
Azure-Ressourcen bereinigen
Der folgende Befehl löscht den von Ihnen bereitgestellten AzureML-Endpunkt. Möglicherweise möchten Sie auch Ihren AzureML Workspace, Compute und registrierte Modelle bereinigen.
az ml online-endpoint delete --name question-answer-ort --yes --subscription {ws.subscription_id} --resource-group {ws.resource_group} --workspace-name {ws.name}