oneDNN Execution Provider
Früher „DNNL“
Beschleunigen Sie die Leistung von ONNX Runtime mithilfe der Intel® Math Kernel Library for Deep Neural Networks (Intel® DNNL) optimierten Primitiven mit dem Intel oneDNN Execution Provider.
Die Intel® oneAPI Deep Neural Network Library ist eine Open-Source-Leistungsbibliothek für Deep-Learning-Anwendungen. Die Bibliothek beschleunigt Deep-Learning-Anwendungen und -Frameworks auf Intel®-Architekturen und Intel®-Prozessorgrafikarchitekturen. Intel DNNL enthält vektorisierte und Thread-fähige Bausteine, die Sie zur Implementierung von Deep Neural Networks (DNN) mit C- und C++-Schnittstellen verwenden können.
Der oneDNN Execution Provider (EP) für ONNX Runtime wird in Partnerschaft zwischen Intel und Microsoft entwickelt.
Inhalt
Build
Anweisungen zum Build finden Sie auf der BUILD-Seite.
Verwendung
C/C++
Der DNNLExecutionProvider Execution Provider muss bei ONNX Runtime registriert werden, um ihn in der Inferenzsitzung zu aktivieren.
Ort::Env env = Ort::Env{ORT_LOGGING_LEVEL_ERROR, "Default"};
Ort::SessionOptions sf;
bool enable_cpu_mem_arena = true;
Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_Dnnl(sf, enable_cpu_mem_arena));
Die Details der C-API finden Sie hier.
Python
Wenn Sie das Python-Wheel von ONNX Runtime verwenden, das mit dem DNNL Execution Provider erstellt wurde, wird es automatisch gegenüber dem CPU Execution Provider priorisiert. Details zu den Python-APIs finden Sie hier.
Subgraph-Optimierung
DNNL verwendet Block-Layouts (z. B. nhwc mit Kanälen, die um 16 geblockt sind – nChw16c), um Vektoroperationen mit AVX512 zu nutzen. Um die beste Leistung zu erzielen, vermeiden wir Reorders (z. B. Nchw16c zu nchw) und propagieren das Block-Layout zur nächsten Primitiven.
Die Subgraph-Optimierung erreicht dies in folgenden Schritten.
- Analysiert den ONNX Runtime-Graphen und erstellt eine interne Darstellung des Subgraphen.
- Der Subgraph-Operator (DnnlFunKernel) durchläuft die DNNL-Knoten und erstellt einen Vektor von DNNL-Kernels.
- Die Compute-Funktion von DnnlFunKernel durchläuft und bindet Daten an DNNL-Primitive im Vektor und reicht den Vektor zur Ausführung ein.
Interne Darstellung des Subgraphen (IR)
DnnlExecutionProvider::GetCapability() analysiert den ONNX-Modellgraphen und erstellt die IR (interne Darstellung) von Subgraphen von DNNL-Operatoren. Jeder Subgraph enthält einen Vektor von DnnlNodes, Eingaben, Ausgaben und Attribute für alle seine DnnlNodes. Es kann Attribute mit demselben Namen geben. Daher stellen wir Attributnamen mit dem Knotennamen und seinem Index voran. Eine eindeutige ID für den Subgraphen wird als Attribut gesetzt.
DnnlNode hat einen Index zu seinen Ein- und Ausgängen sowie einen Zeiger auf seine Elternknoten. DnnlNode liest direkt aus dem geblockten Speicher seines Elternknotens, um Datenreordering zu vermeiden.

Subgraph-Klassen
Primitive wie DnnlConv, DnnlPool usw. sind von der Basisklasse DnnlKernel abgeleitet.
Das folgende UML-Diagramm erfasst die Subgraph-Klassen.
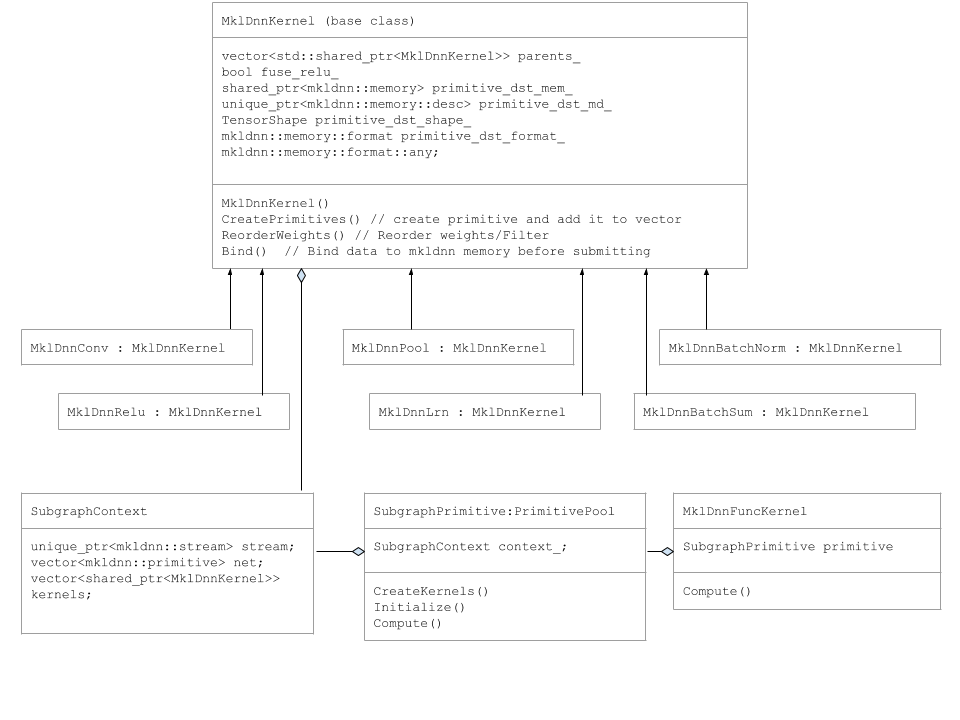
Subgraph-Ausführung
Die Funktion DnnlExecutionProvider::Compute() erstellt DnnlFuncKernel und ruft dessen Compute-Funktion auf.
Die Funktion DnnlFuncKernel::Compute() erstellt einen SubgraphPrimitve-Pool und fügt das Objekt einer Map hinzu.
Der SubgraphPrimitve-Konstruktor ruft die folgenden Member-Funktionen auf.
SubgraphPrimitve::CreatePrimitives()
for (auto& mklnode : mklnodes) {
if (mklnode.name == "Conv") {
kernel.reset(new DnnlConv());
kernels.push_back(kernel);
} else if (mklnode.name == "BatchNormalization-Relu") {
kernel.reset(new DnnlBatchNorm());
context_.kernels.push_back(kernel);
} else if (mklnode.name == "MaxPool") {
kernel.reset(new DnnlPool());
context_.kernels.push_back(kernel);
}
.
.
.
In der Methode CreatePrimitives durchlaufen wir DnnlNodes und erstellen DnnlKernel-Objekte und fügen DNNL-Primitive einem Vektor hinzu. Außerdem werden Attribute gelesen. Dies geschieht nur einmal, bei der ersten Iteration.
SubgraphPrimitve::Compute()
for (auto& kernel : kernels) {
kernel->Bind(input_tensors, output_tensors);
}
stream->submit(net);
In der Methode SubgraphPrimitve::Compute() durchlaufen wir Dnnl Kernels, binden Eingabedaten und übermitteln dann den Vektor von Primitiven an den DNNL-Stream.
Support-Abdeckung
Unterstützte Betriebssysteme
- Ubuntu 16.04
- Windows 10
- Mac OS X
Unterstützte Backends
- CPU