Aufbau einer iOS-Anwendung
In diesem Tutorial untersuchen wir, wie eine iOS-Anwendung erstellt wird, die die On-Device Training-Lösung von ONNX Runtime integriert. On-Device Training bezieht sich auf den Prozess des Trainings eines Machine-Learning-Modells direkt auf einem Edge-Gerät, ohne auf Cloud-Dienste oder externe Server angewiesen zu sein.
In diesem Tutorial erstellen wir eine einfache Sprechererkennungs-App, die lernt, die Stimme eines Sprechers zu identifizieren. Wir werden uns ansehen, wie ein Modell auf dem Gerät trainiert, das trainierte Modell exportiert und das trainierte Modell für die Inferenz verwendet wird.
So wird die Anwendung aussehen

Einleitung
Wir führen Sie durch den Prozess der Erstellung einer iOS-Anwendung, die ein einfaches Audio-Klassifizierungsmodell mithilfe von On-Device-Trainingstechniken trainieren kann. Das Tutorial zeigt die Transfer Learning-Technik, bei der Wissen, das aus dem Training eines Modells für eine Aufgabe gewonnen wurde, genutzt wird, um die Leistung eines Modells für eine andere, aber verwandte Aufgabe zu verbessern. Anstatt den Lernprozess von Grund auf neu zu beginnen, ermöglicht Transfer Learning die Übertragung des Wissens oder der Merkmale, die von einem vortrainierten Modell gelernt wurden, auf eine neue Aufgabe.
In diesem Tutorial nutzen wir das wav2vec-Modell, das auf umfangreichen Promi-Sprachdaten wie VoxCeleb1 trainiert wurde. Wir werden das vortrainierte Modell verwenden, um Merkmale aus den Audiodaten zu extrahieren und einen binären Klassifikator zu trainieren, um den Sprecher zu identifizieren. Die anfänglichen Schichten des Modells dienen als Merkmalsextraktor, der die wichtigen Merkmale der Audiodaten erfasst. Nur die letzte Schicht des Modells wird trainiert, um die Klassifizierungsaufgabe durchzuführen.
Im Tutorial werden wir
- iOS-Audio-APIs verwenden, um Audiodaten für das Training zu erfassen
- Ein Modell auf dem Gerät trainieren
- Das trainierte Modell exportieren
- Das exportierte Modell für die Inferenz verwenden
Inhaltsverzeichnis
- Inhaltsverzeichnis
- Voraussetzungen
- Generierung der Trainingsartefakte
- Aufbau der iOS-Anwendung
- Ausführung der iOS-Anwendung
- Schlussfolgerung
Voraussetzungen
Um diesem Tutorial folgen zu können, sollten Sie ein grundlegendes Verständnis von maschinellem Lernen und iOS-Entwicklung haben. Sie sollten außerdem Folgendes auf Ihrem Computer installiert haben
Hinweis: Die gesamte iOS-Anwendung ist auch im GitHub-Repository
onnxruntime-training-examplesverfügbar. Sie können das Repository klonen und dem Tutorial folgen.
Generierung der Trainingsartefakte
-
Exportieren Sie das Modell nach ONNX.
Wir beginnen mit einem vortrainierten Modell von HuggingFace und exportieren es nach ONNX. Das
wav2vec-Modell wurde aufVoxCeleb1vortrainiert, das mehr als 1000 Kategorien umfasst. Für unsere Aufgabe müssen wir nur Audio in 2 Klassen klassifizieren. Daher ändern wir die letzte Schicht des Modells so, dass sie 2 Klassen ausgibt. Wir verwenden die Bibliothektransformers, um das Modell zu laden und nach ONNX zu exportieren.from transformers import Wav2Vec2ForSequenceClassification, AutoConfig import torch # load config from the pretrained model config = AutoConfig.from_pretrained("superb/wav2vec2-base-superb-sid") model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-sid") # modify last layer to output 2 classes model.classifier = torch.nn.Linear(256, 2) #export model to ONNX dummy_input = torch.randn(1, 160000, requires_grad=True) torch.onnx.export(model, dummy_input, "wav2vec.onnx",input_names=["input"], output_names=["output"], dynamic_axes={"input": {0: "batch"}, "output": {0: "batch"}}) -
Definieren Sie die trainierbaren und nicht trainierbaren Parameter
import onnx # load the onnx model onnx_model = onnx.load("wav2vec.onnx") # Define the parameters that require gradients to be computed (trainable parameters) and # those that don't (frozen/non-trainable parameters) requires_grad = ["classifier.weight", "classifier.bias"] frozen_params = [ param.name for param in onnx_model.graph.initializer if param.name not in requires_grad ] -
Generieren Sie die Trainingsartefakte.
Wir werden für dieses Tutorial den
CrossEntropyLoss-Verlust und denAdamW-Optimierer verwenden. Weitere Details zur Artefakterzeugung finden Sie hier.Da das Modell auch Logits und versteckte Zustände ausgibt, verwenden wir
onnxblock, um eine benutzerdefinierte Verlustfunktion zu definieren, die Logits aus der Modellausgabe extrahiert und an dieCrossEntropyLoss-Funktion übergibt.import onnxruntime.training.onnxblock as onnxblock from onnxruntime.training import artifacts # define the loss function class CustomCELoss(onnxblock.Block): def __init__(self): super().__init__() self.celoss = onnxblock.loss.CrossEntropyLoss() def build(self, logits, *args): return self.celoss(logits) # Generate the training artifacts artifacts.generate_artifacts( onnx_model, requires_grad=requires_grad, frozen_params=frozen_params, loss=CustomCELoss(), optimizer=artifacts.OptimType.AdamW, artifact_directory="artifacts", )Das ist alles! Die Trainingsartefakte wurden im Verzeichnis
artifactsgeneriert. Die Artefakte sind bereit für die Bereitstellung auf dem iOS-Gerät für das Training.
Aufbau der iOS-Anwendung
Xcode-Setup
Öffnen Sie Xcode und erstellen Sie ein neues Projekt. Wählen Sie iOS als Plattform und App als Vorlage. Klicken Sie auf Weiter.
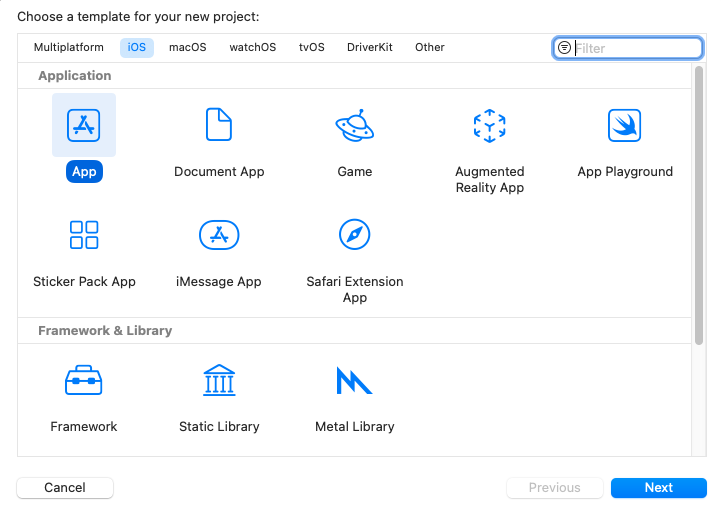
Geben Sie den Projektnamen ein. Hier nennen wir das Projekt „MyVoice“, aber Sie können es beliebig nennen. Stellen Sie sicher, dass Sie SwiftUI als Oberfläche und Swift als Sprache auswählen. Klicken Sie dann auf Weiter.
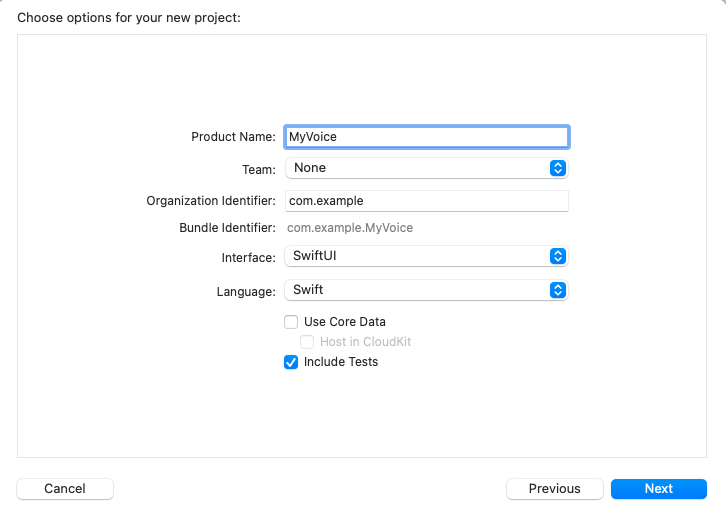
Wählen Sie den Speicherort für Ihr Projekt aus und klicken Sie auf Erstellen.
Nun müssen wir die onnxruntime-training-objc-Pods zum Projekt hinzufügen. Wir verwenden CocoaPods, um die Abhängigkeit hinzuzufügen. Wenn Sie CocoaPods nicht installiert haben, können Sie die Installationsanweisungen hier nachlesen.
Nach der Installation von CocoaPods navigieren Sie zum Projektverzeichnis und führen Sie den folgenden Befehl aus, um eine Podfile zu erstellen
pod init
Dadurch wird eine Podfile im Projektverzeichnis erstellt. Öffnen Sie die Podfile und fügen Sie die folgende Zeile nach der Zeile use_frameworks! hinzu
pod `onnxruntime-training-objc`, `~> 1.16.0`
Speichern Sie die Podfile und führen Sie den folgenden Befehl aus, um die Abhängigkeiten zu installieren
pod install
Dadurch wird eine MyVoice.xcworkspace-Datei im Projektverzeichnis erstellt. Öffnen Sie die xcworkspace-Datei in Xcode. Dies öffnet das Projekt in Xcode mit den verfügbaren CocoaPods-Abhängigkeiten.
Klicken Sie nun mit der rechten Maustaste auf die Gruppe „MyVoice“ im Projektnavigator und wählen Sie „New Group“, um eine neue Gruppe im Projekt namens artifacts zu erstellen. Ziehen Sie die im vorherigen Abschnitt generierten Artefakte per Drag & Drop in die Gruppe artifacts. Stellen Sie sicher, dass Sie die Optionen Create folder references und Copy items if needed auswählen. Dadurch werden die Artefakte zum Projekt hinzugefügt.
Klicken Sie als Nächstes mit der rechten Maustaste auf die Gruppe „MyVoice“ und wählen Sie „New Group“, um eine neue Gruppe im Projekt namens recordings zu erstellen. Diese Gruppe enthält die Audioaufnahmen, die für das Training verwendet werden. Sie können die Aufnahmen generieren, indem Sie das Skript recording_gen.py am Stamm des Projekts ausführen. Alternativ können Sie auch Sprachaufnahmen anderer Sprecher verwenden, außer des Sprechers, dessen Stimme Sie für das Training verwenden möchten. Stellen Sie sicher, dass die Aufnahmen Mono-Kanäle mit einer Länge von 10 Sekunden im .wav-Format mit einer Abtastrate von 16 kHz haben. Benennen Sie die Aufnahmen zusätzlich als other_0.wav, other_1.wav usw. und fügen Sie sie der Gruppe recordings hinzu.
Die Projektstruktur sollte so aussehen

Anwendungsübersicht
Die Anwendung besteht aus zwei Haupt-UI-Views: TrainView und InferView. Die TrainView dient zum Trainieren des Modells auf dem Gerät, und die InferView dient zur Durchführung der Inferenz mit dem trainierten Modell. Zusätzlich gibt es die ContentView, die die Startansicht der Anwendung ist und Schaltflächen zum Navigieren zur TrainView und InferView enthält.
Zusätzlich erstellen wir eine Klasse AudioRecorder, um die Aufnahme von Audio über das Mikrofon zu handhaben. Sie nimmt 10 Sekunden Audio auf und gibt die Audiodaten als Data-Objekt aus, das für Trainings- und Inferenzzwecke verwendet werden kann.
Wir haben eine Klasse Trainer, die das Training und den Export des Modells handhabt.
Schließlich erstellen wir auch eine Klasse VoiceIdentifier, die die Inferenz mit dem trainierten Modell handhabt.
Trainieren des Modells
Zuerst erstellen wir eine Klasse Trainer, die das Training und den Export des Modells handhabt. Sie lädt die Trainingsartefakte, trainiert das Modell auf gegebenem Audio und exportiert das trainierte Modell mithilfe der ONNX Runtime On-Device Training-APIs. Die detaillierte Dokumentation für die API finden Sie hier.
Die Klasse Trainer hat folgende öffentliche Methoden
init()- Initialisiert die Trainingssitzung und lädt die Trainingsartefakte.train(_ trainingData: [Data])- Trainiert das Modell auf den gegebenen Audio-Daten des Benutzers. Sie nimmt ein Array vonData-Objekten entgegen, wobei jedesData-Objekt die Audiodaten des Benutzers darstellt, und verwendet diese zusammen mit einigen voraufgenommenen Audiodaten, um das Modell zu trainieren.exportModelForInference()- Exportiert das trainierte Modell für Inferenzzwecke.
-
Laden der Trainingsartefakte und Initialisieren der Trainingssitzung
Um ein Modell zu trainieren, müssen wir zuerst die Artefakte laden,
ORTEnv,ORTTrainingSessionundORTCheckpointerstellen. Diese Objekte werden zum Trainieren des Modells verwendet. Wir werden diese Objekte in derinit-Methode derTrainer-Klasse erstellen.import Foundation import onnxruntime_training_objc class Trainer { private let ortEnv: ORTEnv private let trainingSession: ORTTrainingSession private let checkpoint: ORTCheckpoint enum TrainerError: Error { case Error(_ message: String) } init() throws { ortEnv = try ORTEnv(loggingLevel: ORTLoggingLevel.warning) // get path for artifacts guard let trainingModelPath = Bundle.main.path(forResource: "training_model", ofType: "onnx") else { throw TrainerError.Error("Failed to find training model file.") } guard let evalModelPath = Bundle.main.path(forResource: "eval_model",ofType: "onnx") else { throw TrainerError.Error("Failed to find eval model file.") } guard let optimizerPath = Bundle.main.path(forResource: "optimizer_model", ofType: "onnx") else { throw TrainerError.Error("Failed to find optimizer model file.") } guard let checkpointPath = Bundle.main.path(forResource: "checkpoint", ofType: nil) else { throw TrainerError.Error("Failed to find checkpoint file.") } checkpoint = try ORTCheckpoint(path: checkpointPath) trainingSession = try ORTTrainingSession(env: ortEnv, sessionOptions: ORTSessionOptions(), checkpoint: checkpoint, trainModelPath: trainingModelPath, evalModelPath: evalModelPath, optimizerModelPath: optimizerPath) } } -
Trainieren des Modells
a. Bevor wir das Modell trainieren, müssen wir zuerst die Daten aus den zuvor erstellten WAV-Dateien extrahieren. Hier ist eine einfache Funktion, die die Daten aus der WAV-Datei extrahiert.
private func getDataFromWavFile(fileName: String) throws -> (AVAudioBuffer, Data) { guard let fileUrl = Bundle.main.url(forResource: fileName, withExtension:"wav") else { throw TrainerError.Error("Failed to find wav file: \(fileName).") } let audioFile = try AVAudioFile(forReading: fileUrl) let format = audioFile.processingFormat let totalFrames = AVAudioFrameCount(audioFile.length) guard let buffer = AVAudioPCMBuffer(pcmFormat: format, frameCapacity: totalFrames) else { throw TrainerError.Error("Failed to create audio buffer.") } try audioFile.read(into: buffer) guard let floatChannelData = buffer.floatChannelData else { throw TrainerError.Error("Failed to get float channel data.") } let data = Data( bytesNoCopy: floatChannelData[0], count: Int(buffer.frameLength) * MemoryLayout<Float>.size, deallocator: .none ) return (buffer, data) }b. Die Funktion
TrainingSession.trainStepist für das Training des Modells verantwortlich. Sie nimmt die Eingabedaten und die Labels entgegen und gibt den Verlust zurück. Die Eingaben werden alsORTValue-Objekte an ONNX Runtime übergeben. Daher müssen wir die Eingabe-Audio-Data-Objekte und Labels inORTValuekonvertieren.private func getORTValue(dataList: [Data]) throws -> ORTValue { let tensorData = NSMutableData() dataList.forEach {data in tensorData.append(data)} let inputShape: [NSNumber] = [dataList.count as NSNumber, dataList[0].count / MemoryLayout<Float>.stride as NSNumber] return try ORTValue( tensorData: tensorData, elementType: ORTTensorElementDataType.float, shape: inputShape ) } private func getORTValue(labels: [Int64]) throws -> ORTValue { let tensorData = NSMutableData(bytes: labels, length: labels.count * MemoryLayout<Int64>.stride) let inputShape: [NSNumber] = [labels.count as NSNumber] return try ORTValue ( tensorData: tensorData, elementType: ORTTensorElementDataType.int64, shape: inputShape ) }c. Wir sind bereit, die Funktion
trainStepzu schreiben, die einen Batch von Eingabedaten und Labels nimmt und einen Trainingsschritt auf dem gegebenen Batch durchführt.func trainStep(inputData: [Data], labels: [Int64]) throws { let inputs = [try getORTValue(dataList: inputData), try getORTValue(labels: labels)] try trainingSession.trainStep(withInputValues: inputs) // update the model params try trainingSession.optimizerStep() // reset the gradients try trainingSession.lazyResetGrad() }d. Schließlich haben wir alles, was wir brauchen, um die Trainingsschleife zu schreiben. Hier repräsentiert
kNumOtherRecordingsdie Anzahl der Aufnahmen im Verzeichnisrecordings, das wir zuvor erstellt haben.kNumEpochsrepräsentiert die Anzahl der Epochen, die wir das Modell auf den gegebenen Daten trainieren möchten.kUserIndexundkOtherIndexrepräsentieren die Labels für die Benutzer- und anderen Aufnahmen.Wir haben auch einen
progressCallback, der nach jedem Trainingsschritt aufgerufen wird. Wir werden diesen Callback verwenden, um die Fortschrittsanzeige in der Benutzeroberfläche zu aktualisieren.private let kNumOtherRecordings: Int = 20 private let kNumEpochs: Int = 3 let kUserIndex: Int64 = 1 let kOtherIndex: Int64 = 0 func train(_ trainingData: [Data], progressCallback: @escaping (Double) -> Void) throws { let numRecordings = trainingData.count var otherRecordings = Array(0..<kNumOtherRecordings) for e in 0..<kNumEpochs { print("Epoch: \(e)") otherRecordings.shuffle() let otherData = otherRecordings.prefix(numRecordings) for i in 0..<numRecordings { let (buffer, wavFileData) = try getDataFromWavFile(fileName: "other_\(otherData[i])") try trainStep(inputData: [trainingData[i], wavFileData], labels: [kUserIndex, kOtherIndex]) print("finished training on recording \(i)") let progress = Double((e * numRecordings) + i + 1) / Double(kNumEpochs * numRecordings) progressCallback(progress) } } } -
Exportieren des trainierten Modells
Wir können die Methode
exportModelForInferenceder KlasseORTTrainingSessionverwenden, um das trainierte Modell zu exportieren. Die Methode nimmt den Pfad entgegen, an dem das Modell exportiert werden soll, und die Ausgabennamen des Modells.Hier exportieren wir das Modell in das Verzeichnis
Libraryder Anwendung. Das exportierte Modell wird für Inferenzzwecke verwendet.func exportModelForInference() throws { guard let libraryDirectory = FileManager.default.urls(for: .libraryDirectory, in: .userDomainMask).first else { throw TrainerError.Error("Failed to find library directory ") } let modelPath = libraryDirectory.appendingPathComponent("inference_model.onnx").path try trainingSession.exportModelForInference(withOutputPath: modelPath, graphOutputNames: ["output"]) }
Die vollständige Implementierung der Trainer-Klasse finden Sie hier.
Inferenz mit dem trainierten Modell
Die Klasse VoiceIdentifier handhabt die Inferenz mit dem trainierten Modell. Sie lädt das trainierte Modell und führt die Inferenz auf den gegebenen Audiodaten durch. Die Klasse verfügt über die Methode evaluate(inputData: Data) -> Result<(Bool, Float), Error>, die die Audiodaten entgegennimmt und das Ergebnis der Inferenz zurückgibt. Das Ergebnis ist ein Tupel aus (Bool, Float), wobei das erste Element angibt, ob die Audiodaten als die des Benutzers identifiziert wurden, und das zweite Element den Konfidenzscore der Vorhersage angibt.
Zuerst laden wir das trainierte Modell mithilfe des ORTSession-Objekts.
class VoiceIdentifier {
private let ortEnv : ORTEnv
private let ortSession: ORTSession
private let kThresholdProbability: Float = 0.80
enum VoiceIdentifierError: Error {
case Error(_ message: String)
}
init() throws {
ortEnv = try ORTEnv(loggingLevel: ORTLoggingLevel.warning)
guard let libraryDirectory = FileManager.default.urls(for: .libraryDirectory, in: .userDomainMask).first else {
throw VoiceIdentifierError.Error("Failed to find library directory ")
}
let modelPath = libraryDirectory.appendingPathComponent("inference_model.onnx").path
if !FileManager.default.fileExists(atPath: modelPath) {
throw VoiceIdentifierError.Error("Failed to find inference model file.")
}
ortSession = try ORTSession(env: ortEnv, modelPath: modelPath, sessionOptions: nil)
}
}
Als Nächstes schreiben wir die Methode evaluate. Zuerst nimmt sie die Audiodaten entgegen und konvertiert sie in ORTValue. Dann führt sie die Inferenz mit dem Modell durch. Schließlich extrahiert sie die Logits aus der Ausgabe und wendet Softmax an, um Wahrscheinlichkeiten zu erhalten.
private func isUser(logits: [Float]) -> Float {
// apply softMax
let maxInput = logits.max() ?? 0.0
let expValues = logits.map { exp($0 - maxInput) } // Calculate e^(x - maxInput) for each element
let expSum = expValues.reduce(0, +) // Sum of all e^(x - maxInput) values
return expValues.map { $0 / expSum }[1] // Calculate the softmax probabilities
}
func evaluate(inputData: Data) -> Result<(Bool, Float), Error> {
return Result<(Bool, Float), Error> { () -> (Bool, Float) in
// convert input data to ORTValue
let inputShape: [NSNumber] = [1, inputData.count / MemoryLayout<Float>.stride as NSNumber]
let input = try ORTValue(
tensorData: NSMutableData(data: inputData),
elementType: ORTTensorElementDataType.float,
shape: inputShape)
let outputs = try ortSession.run(
withInputs: ["input": input],
outputNames: ["output"],
runOptions: nil)
guard let output = outputs["output"] else {
throw VoiceIdentifierError.Error("Failed to get model output from inference.")
}
let outputData = try output.tensorData() as Data
let probUser = outputData.withUnsafeBytes { (buffer: UnsafeRawBufferPointer) -> Float in
let floatBuffer = buffer.bindMemory(to: Float.self)
let logits = Array(UnsafeBufferPointer(start: floatBuffer.baseAddress, count: outputData.count/MemoryLayout<Float>.stride))
return isUser(logits: logits)
}
return (probUser >= kThresholdProbability, probUser)
}
}
Die vollständige Implementierung der Klasse VoiceIdentifier finden Sie hier.
Aufnehmen von Audio
Wir verwenden die Klasse AudioRecorder, um Audio über das Mikrofon aufzunehmen. Sie nimmt 10 Sekunden Audio auf und gibt die Audiodaten als Data-Objekt aus, das für Trainings- und Inferenzzwecke verwendet werden kann. Wir verwenden das Framework AVFoundation, um auf das Mikrofon zuzugreifen und das Audio aufzunehmen. Es gibt eine öffentliche Methode record(callback: @escaping RecordingDoneCallback), die das Audio aufnimmt und die Callback-Funktion mit den Audiodaten aufruft, sobald die Aufnahme abgeschlossen ist.
import AVFoundation
import Foundation
private let kSampleRate: Int = 16000
private let kRecordingDuration: TimeInterval = 10
class AudioRecorder {
typealias RecordResult = Result<Data, Error>
typealias RecordingDoneCallback = (RecordResult) -> Void
enum AudioRecorderError: Error {
case Error(message: String)
}
func record(callback: @escaping RecordingDoneCallback) {
let session = AVAudioSession.sharedInstance()
session.requestRecordPermission { allowed in
do {
guard allowed else {
throw AudioRecorderError.Error(message: "Recording permission denied.")
}
try session.setCategory(.record)
try session.setActive(true)
let tempDir = FileManager.default.temporaryDirectory
let recordingUrl = tempDir.appendingPathComponent("recording.wav")
let formatSettings: [String: Any] = [
AVFormatIDKey: kAudioFormatLinearPCM,
AVSampleRateKey: kSampleRate,
AVNumberOfChannelsKey: 1,
AVLinearPCMBitDepthKey: 16,
AVLinearPCMIsBigEndianKey: false,
AVLinearPCMIsFloatKey: false,
AVEncoderAudioQualityKey: AVAudioQuality.high.rawValue,
]
let recorder = try AVAudioRecorder(url: recordingUrl, settings: formatSettings)
self.recorder = recorder
let delegate = RecorderDelegate(callback: callback)
recorder.delegate = delegate
self.recorderDelegate = delegate
guard recorder.record(forDuration: kRecordingDuration) else {
throw AudioRecorderError.Error(message: "Failed to record.")
}
// control should resume in recorder.delegate.audioRecorderDidFinishRecording()
} catch {
callback(.failure(error))
}
}
}
private var recorderDelegate: RecorderDelegate?
private var recorder: AVAudioRecorder?
private class RecorderDelegate: NSObject, AVAudioRecorderDelegate {
private let callback: RecordingDoneCallback
init(callback: @escaping RecordingDoneCallback) {
self.callback = callback
}
func audioRecorderDidFinishRecording(
_ recorder: AVAudioRecorder,
successfully flag: Bool
) {
let recordResult = RecordResult { () -> Data in
guard flag else {
throw AudioRecorderError.Error(message: "Recording was unsuccessful.")
}
let recordingUrl = recorder.url
let recordingFile = try AVAudioFile(forReading: recordingUrl)
guard
let format = AVAudioFormat(
commonFormat: .pcmFormatFloat32,
sampleRate: recordingFile.fileFormat.sampleRate,
channels: 1,
interleaved: false)
else {
throw AudioRecorderError.Error(message: "Failed to create audio format.")
}
guard
let recordingBuffer = AVAudioPCMBuffer(
pcmFormat: format,
frameCapacity: AVAudioFrameCount(recordingFile.length))
else {
throw AudioRecorderError.Error(message: "Failed to create audio buffer.")
}
try recordingFile.read(into: recordingBuffer)
guard let recordingFloatChannelData = recordingBuffer.floatChannelData else {
throw AudioRecorderError.Error(message: "Failed to get float channel data.")
}
return Data(bytes: recordingFloatChannelData[0], count: Int(recordingBuffer.frameLength) * MemoryLayout<Float>.size)
}
callback(recordResult)
}
func audioRecorderEncodeErrorDidOccur(
_ recorder: AVAudioRecorder,
error: Error?
) {
if let error = error {
callback(.failure(error))
} else {
callback(.failure(AudioRecorderError.Error(message: "Encoding was unsuccessful.")))
}
}
}
}
TrainView
Die TrainView wird verwendet, um das Modell mit der Stimme des Benutzers zu trainieren. Zuerst fordert sie den Benutzer auf, kNumRecordings Aufnahmen seiner Stimme zu machen. Dann trainiert sie das Modell mit der Stimme des Benutzers und einigen voraufgenommenen Aufnahmen von Stimmen anderer Sprecher. Schließlich exportiert sie das trainierte Modell für Inferenzzwecke.
import SwiftUI
struct TrainView: View {
enum ViewState {
case recordingTrainingData, trainingInProgress, trainingComplete
}
private static let sentences = [
"In the embrace of nature's beauty, I find peace and tranquility. The gentle rustling of leaves soothes my soul, and the soft sunlight kisses my skin. As I breathe in the fresh air, I am reminded of the interconnectedness of all living things, and I feel a sense of oneness with the world around me.",
"Under the starlit sky, I gaze in wonder at the vastness of the universe. Each twinkle represents a story yet untold, a dream yet to be realized. With every new dawn, I am filled with hope and excitement for the opportunities that lie ahead. I embrace each day as a chance to grow, to learn, and to create beautiful memories.",
"A warm hug from a loved one is a precious gift that warms my heart. In that tender embrace, I feel a sense of belonging and security. Laughter and tears shared with dear friends create a bond that withstands the test of time. These connections enrich my life and remind me of the power of human relationships.",
"Life's journey is like a beautiful melody, with each note representing a unique experience. As I take each step, I harmonize with the rhythm of existence. Challenges may come my way, but I face them with resilience and determination, knowing they are opportunities for growth and self-discovery.",
"With every page turned in a book, I open the door to new worlds and ideas. The written words carry the wisdom of countless souls, and I am humbled by the knowledge they offer. In stories, I find a mirror to my own experiences and a beacon of hope for a better tomorrow.",
"Life's trials may bend me, but they will not break me. Through adversity, I discover the strength within my heart. Each obstacle is a chance to learn, to evolve, and to emerge as a better version of myself. I am grateful for every lesson, for they shape me into the person I am meant to be.",
"The sky above is an ever-changing canvas of colors and clouds. In its vastness, I realize how small I am in the grand scheme of things, and yet, I know my actions can ripple through the universe. As I walk this Earth, I seek to leave behind a positive impact and a legacy of love and compassion.",
"In the stillness of meditation, I connect with the depth of my soul. The external noise fades away, and I hear the whispers of my inner wisdom. With each breath, I release tension and embrace serenity. Meditation is my sanctuary, a place where I can find clarity and renewed energy.",
"Kindness is a chain reaction that spreads like wildfire. A simple act of compassion can brighten someone's day and inspire them to pay it forward. Together, we can create a wave of goodness that knows no boundaries, reaching even the farthest corners of the world.",
"As the sun rises on a new day, I am filled with gratitude for the gift of life. Every moment is a chance to make a difference, to love deeply, and to embrace joy. I welcome the adventures that await me and eagerly embrace the mysteries yet to be uncovered."
]
private let kNumRecordings = 5
private let audioRecorder = AudioRecorder()
private let trainer = try! Trainer()
@State private var trainingData: [Data] = []
@State private var viewState: ViewState = .recordingTrainingData
@State private var readyToRecord: Bool = true
@State private var trainingProgress: Double = 0.0
private func recordVoice() {
audioRecorder.record { recordResult in
switch recordResult {
case .success(let recordingData):
trainingData.append(recordingData)
print("Successfully completed Recording")
case .failure(let error):
print("Error: \(error)")
}
readyToRecord = true
if trainingData.count == kNumRecordings {
viewState = .trainingInProgress
trainAndExportModel()
}
}
}
private func updateProgressBar(progress: Double) {
DispatchQueue.main.async {
trainingProgress = progress
}
}
private func trainAndExportModel() {
Task {
do {
try trainer.train(trainingData, progressCallback: updateProgressBar)
try trainer.exportModelForInference()
DispatchQueue.main.async {
viewState = .trainingComplete
print("Training is complete")
}
} catch {
DispatchQueue.main.async {
viewState = .trainingComplete
print("Training Failed: \(error)")
}
}
}
}
var body: some View {
VStack {
switch viewState {
case .recordingTrainingData:
Text("\(trainingData.count + 1) of \(kNumRecordings)")
.font(.caption)
.foregroundColor(.secondary)
.padding()
ProgressView(value: Double(trainingData.count),
total: Double(kNumRecordings))
.progressViewStyle(LinearProgressViewStyle(tint: .purple))
.frame(height: 10)
.cornerRadius(5)
Spacer()
Text(TrainView.sentences[trainingData.count % TrainView.sentences.count])
.font(.body)
.padding()
.multilineTextAlignment(.center)
.fontDesign(.monospaced)
Spacer()
ZStack(alignment: .center) {
Image(systemName: "mic.fill")
.resizable()
.aspectRatio(contentMode: .fit)
.frame(width: 100, height: 100)
.foregroundColor( readyToRecord ? .gray: .red)
.transition(.scale)
.animation(.easeIn, value: 1)
}
Spacer()
Button(action: {
readyToRecord = false
recordVoice()
}) {
Text(readyToRecord ? "Record" : "Recording ...")
.font(.title)
.padding()
.background(readyToRecord ? .green : .gray)
.foregroundColor(.white)
.cornerRadius(10)
}.disabled(!readyToRecord)
case .trainingInProgress:
VStack {
Spacer()
ProgressView(value: trainingProgress,
total: 1.0,
label: {Text("Training")},
currentValueLabel: {Text(String(format: "%.0f%%", trainingProgress * 100))})
.padding()
Spacer()
}
case .trainingComplete:
Spacer()
Text("Training successfully finished!")
.font(.title)
.padding()
.multilineTextAlignment(.center)
.fontDesign(.monospaced)
Spacer()
NavigationLink(destination: InferView()) {
Text("Infer")
.font(.title)
.padding()
.background(.purple)
.foregroundColor(.white)
.cornerRadius(10)
}
.padding(.leading, 20)
}
Spacer()
}
.padding()
.navigationTitle("Train")
}
}
struct TrainView_Previews: PreviewProvider {
static var previews: some View {
TrainView()
}
}
Die vollständige Implementierung der TrainView finden Sie hier.
InferView
Schließlich erstellen wir die InferView, die zur Durchführung von Inferenz mit dem trainierten Modell verwendet wird. Sie fordert den Benutzer auf, seine Stimme aufzunehmen und führt die Inferenz mit dem trainierten Modell durch. Dann zeigt sie das Ergebnis der Inferenz an.
import SwiftUI
struct InferView: View {
enum InferResult {
case user, other, notSet
}
private let audioRecorder = AudioRecorder()
@State private var voiceIdentifier: VoiceIdentifier? = nil
@State private var readyToRecord: Bool = true
@State private var inferResult: InferResult = InferResult.notSet
@State private var probUser: Float = 0.0
@State private var showAlert = false
@State private var alertMessage = ""
private func recordVoice() {
audioRecorder.record { recordResult in
let recognizeResult = recordResult.flatMap { recordingData in
return voiceIdentifier!.evaluate(inputData: recordingData)
}
endRecord(recognizeResult)
}
}
private func endRecord(_ result: Result<(Bool, Float), Error>) {
DispatchQueue.main.async {
switch result {
case .success(let (isMatch, confidence)):
print("Your Voice with confidence: \(isMatch), \(confidence)")
inferResult = isMatch ? .user : .other
probUser = confidence
case .failure(let error):
print("Error: \(error)")
}
readyToRecord = true
}
}
var body: some View {
VStack {
Spacer()
ZStack(alignment: .center) {
Image(systemName: "mic.fill")
.resizable()
.aspectRatio(contentMode: .fit)
.frame(width: 100, height: 100)
.foregroundColor( readyToRecord ? .gray: .red)
.transition(.scale)
.animation(.easeInOut, value: 1)
}
Spacer()
Button(action: {
readyToRecord = false
recordVoice()
}) {
Text(readyToRecord ? "Record" : "Recording ...")
.font(.title)
.padding()
.background(readyToRecord ? .green : .gray)
.foregroundColor(.white)
.cornerRadius(10)
}.disabled(voiceIdentifier == nil || !readyToRecord)
.opacity(voiceIdentifier == nil ? 0.5: 1.0)
if inferResult != .notSet {
Spacer()
ZStack (alignment: .center) {
Image(systemName: inferResult == .user ? "person.crop.circle.fill.badge.checkmark": "person.crop.circle.fill.badge.xmark")
.resizable()
.aspectRatio(contentMode: .fit)
.frame(width: 100, height: 100)
.foregroundColor(inferResult == .user ? .green : .red)
.animation(.easeInOut, value: 2)
}
Text("Probability of User : \(String(format: "%.2f", probUser*100.0))%")
.multilineTextAlignment(.center)
.fontDesign(.monospaced)
}
Spacer()
}
.padding()
.navigationTitle("Infer")
.onAppear {
do {
voiceIdentifier = try VoiceIdentifier()
} catch {
alertMessage = "Error initializing inference session, make sure that training is completed: \(error)"
showAlert = true
}
}
.alert(isPresented: $showAlert) {
Alert(title: Text("Error"), message: Text(alertMessage), dismissButton: .default(Text("OK")))
}
}
}
struct InferView_Previews: PreviewProvider {
static var previews: some View {
InferView()
}
}
Die vollständige Implementierung der InferView finden Sie hier.
ContentView
Schließlich aktualisieren wir die Standard-ContentView, sodass sie Schaltflächen enthält, um zur TrainView und InferView zu navigieren.
import SwiftUI
struct ContentView: View {
var body: some View {
NavigationView {
VStack {
Text("My Voice")
.font(.largeTitle)
.padding(.top, 50)
Spacer()
ZStack(alignment: .center) {
Image(systemName: "waveform.circle.fill")
.resizable()
.aspectRatio(contentMode: .fit)
.frame(width: 100, height: 100)
.foregroundColor(.purple)
}
Spacer()
HStack {
NavigationLink(destination: TrainView()) {
Text("Train")
.font(.title)
.padding()
.background(Color.purple)
.foregroundColor(.white)
.cornerRadius(10)
}
.padding(.trailing, 20)
NavigationLink(destination: InferView()) {
Text("Infer")
.font(.title)
.padding()
.background(.purple)
.foregroundColor(.white)
.cornerRadius(10)
}
.padding(.leading, 20)
}
Spacer()
}
.padding()
}
}
}
struct ContentView_Previews: PreviewProvider {
static var previews: some View {
ContentView()
}
}
Die vollständige Implementierung der ContentView finden Sie hier.
Ausführung der iOS-Anwendung
Nun sind wir bereit, die Anwendung auszuführen. Sie können die Anwendung auf dem Simulator oder auf dem Gerät ausführen. Weitere Informationen zur Ausführung der Anwendung auf dem Simulator und dem Gerät finden Sie hier.
a. Wenn Sie nun die Anwendung ausführen, sollten Sie den folgenden Bildschirm sehen
b. Klicken Sie als Nächstes auf die Schaltfläche Train, um zur TrainView zu navigieren. Die TrainView fordert Sie auf, Ihre Stimme aufzunehmen. Sie müssen Ihre Stimme kNumRecordings Mal aufnehmen.
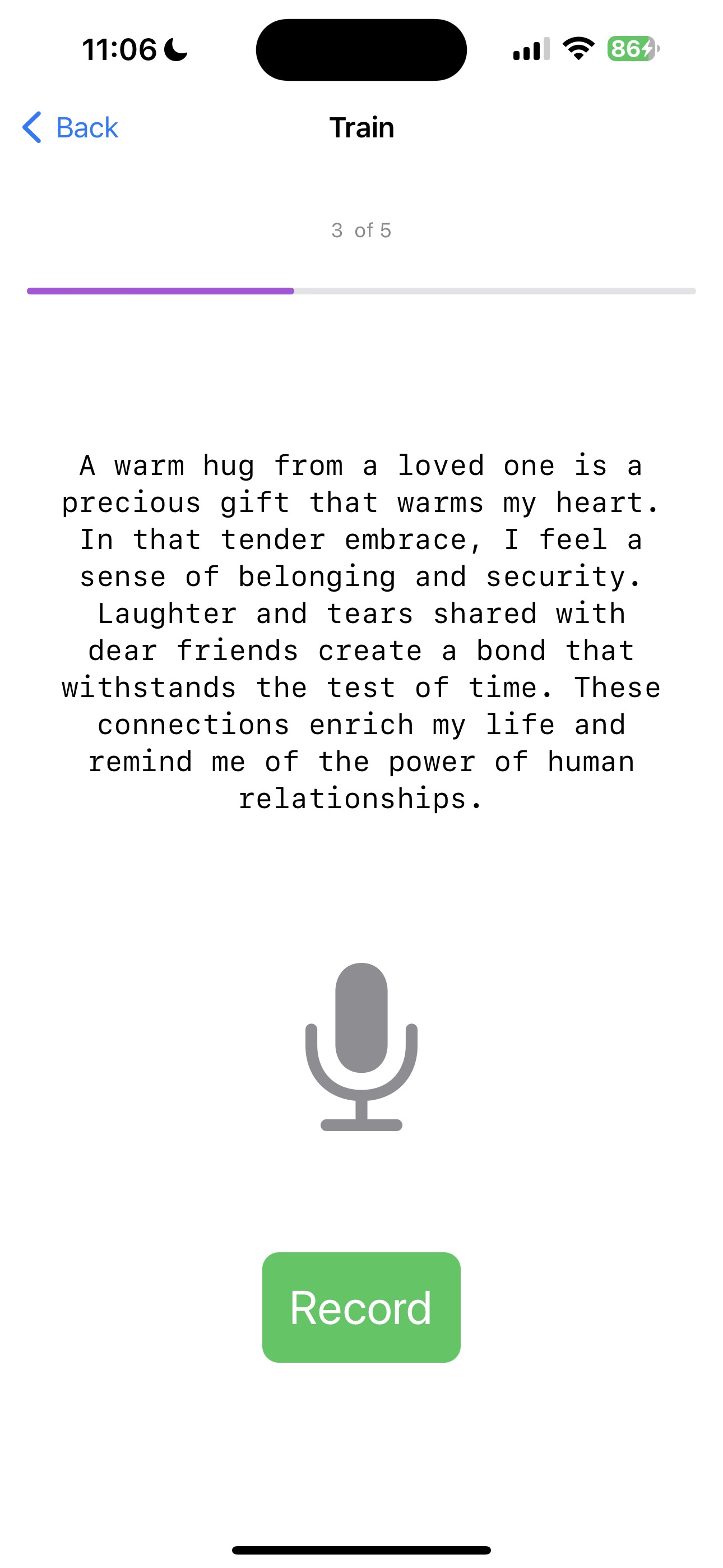
c. Sobald alle Aufnahmen abgeschlossen sind, trainiert die Anwendung das Modell auf den gegebenen Daten. Sie sehen eine Fortschrittsanzeige, die den Fortschritt des Trainings anzeigt.

d. Nach Abschluss des Trainings sehen Sie den folgenden Bildschirm
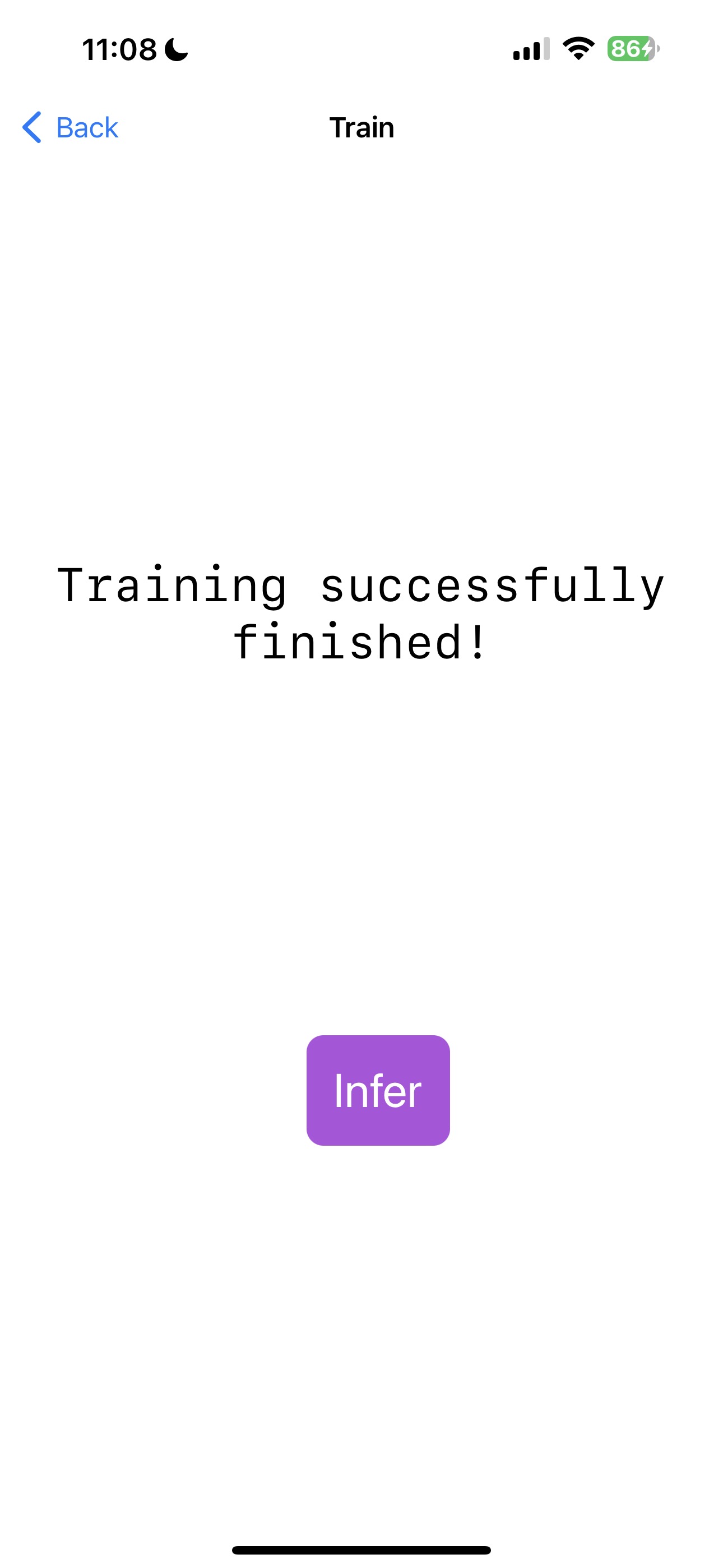
e. Klicken Sie nun auf die Schaltfläche Infer, um zur InferView zu navigieren. Die InferView fordert Sie auf, Ihre Stimme aufzunehmen. Sobald die Aufnahme abgeschlossen ist, wird die Inferenz mit dem trainierten Modell durchgeführt und das Ergebnis angezeigt.
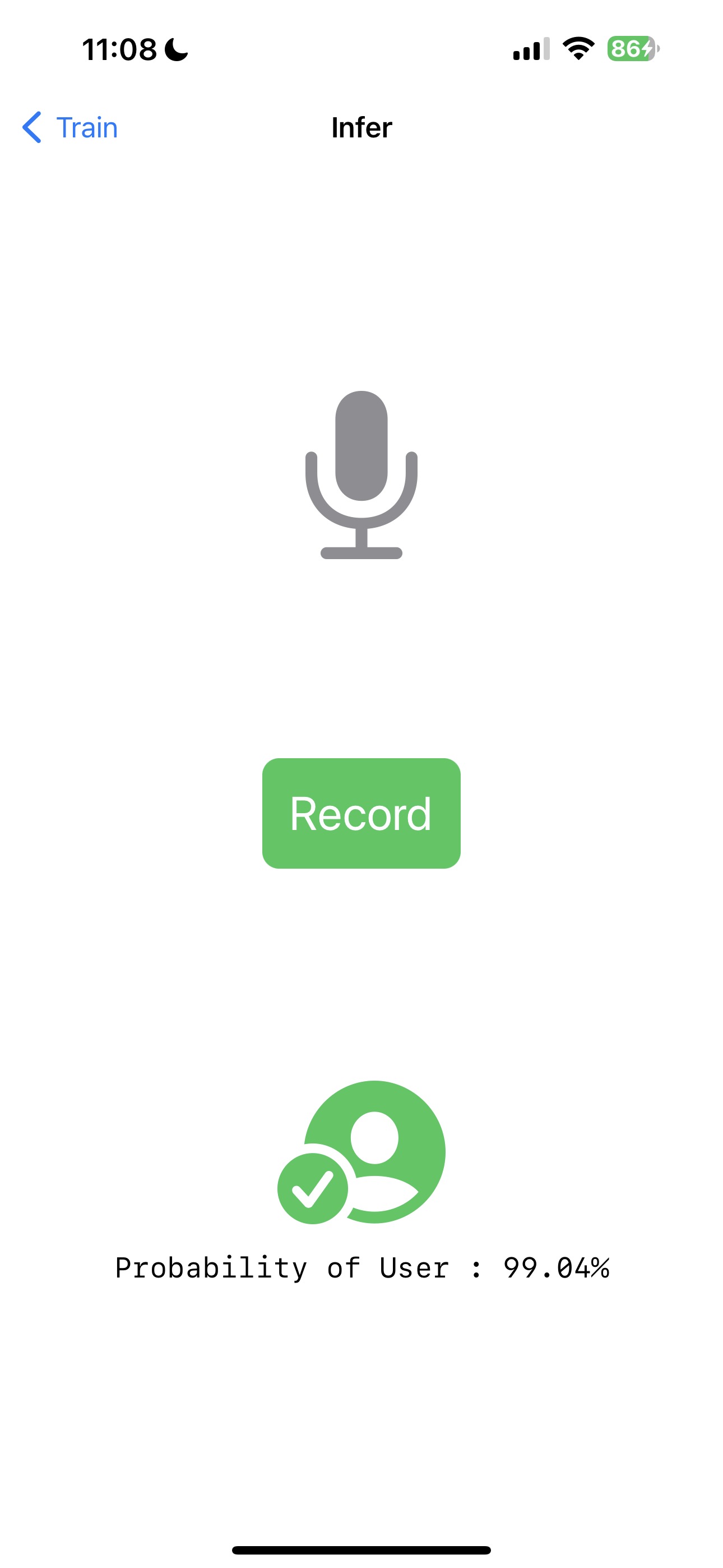
Das ist alles! Hoffentlich hat sie Ihre Stimme korrekt identifiziert.
Fazit
Herzlichen Glückwunsch! Sie haben erfolgreich eine iOS-Anwendung erstellt, die ein einfaches Audio-Klassifizierungsmodell mithilfe von On-Device-Trainingstechniken trainieren kann. Sie können die Anwendung nun verwenden, um ein Modell mit Ihrer eigenen Stimme zu trainieren und die Inferenz mit dem trainierten Modell durchzuführen. Die Anwendung ist auch auf GitHub unter onnxruntime-training-examples verfügbar.