WICHTIG: DIESE INFORMATION GILT NUR FÜR ONNX RUNTIME VERSION 1.10 UND FRÜHER. BITTE VERWENDEN SIE EINE NEUERE VERSION.
ONNX Runtime Mobiltperformanz optimieren
Erfahren Sie, wie sich verschiedene Optimierungen auf die Leistung auswirken, und erhalten Sie Vorschläge für Leistungstests mit ORT-Formatmodellen.
ONNX Runtime Mobile kann verwendet werden, um ORT-Formatmodelle mithilfe von NNAPI (über den NNAPI Execution Provider (EP)) auf Android-Plattformen und CoreML (über den CoreML EP) auf iOS-Plattformen auszuführen.
Überprüfen Sie zunächst die einleitenden Details in Verwendung von NNAPI mit ONNX Runtime Mobile und Verwendung von CoreML mit ONNX Runtime.
WICHTIGER HINWEIS: Die Beispiele auf dieser Seite beziehen sich der Kürze halber auf den NNAPI EP. Die Informationen gelten gleichermaßen für den CoreML EP, sodass jede untenstehende Referenz auf „NNAPI“ durch „CoreML“ ersetzt werden kann.
Die Unterstützung für die Erstellung eines CoreML-fähigen ORT-Formatmodells, ähnlich wie bei der Erstellung eines NNAPI-fähigen ORT-Formatmodells, wurde in ONNX Runtime Version 1.9 hinzugefügt.
Inhalt
- 1. ONNX Model Optimierungsbeispiel
- 2. Initiale Leistungstests
- 3. Erstellung eines NNAPI-fähigen ORT-Formatmodells
1. ONNX Model Optimierungsbeispiel
ONNX Runtime wendet Optimierungen auf das ONNX-Modell an, um die Inferenzleistung zu verbessern. Diese Optimierungen erfolgen vor dem Exportieren eines ORT-Formatmodells. Weitere Details zu den verfügbaren Optimierungen finden Sie in der Dokumentation zur Graphenoptimierung.
Es ist wichtig zu verstehen, wie sich die verschiedenen Optimierungsstufen auf die Knoten im Modell auswirken, da dies bestimmt, wie viel des Modells mit NNAPI oder CoreML ausgeführt werden kann.
Basis
Die Basis-Optimierungen entfernen redundante Knoten und führen Constant Folding durch. Bei der Modifikation des Modells werden nur ONNX-Operatoren verwendet.
Erweitert
Die erweiterten Optimierungen ersetzen einen oder mehrere Standard-ONNX-Operatoren durch interne ONNX Runtime-Operatoren, um die Leistung zu steigern. Jede Optimierung hat eine Liste von EPs, für die sie gültig ist. Sie ersetzt nur Knoten, die diesem EP zugewiesen sind, und der Ersatzknoten wird mit demselben EP ausgeführt.
Layout
Layout-Optimierungen können hardwareabhängig sein und interne Konvertierungen zwischen dem von ONNX verwendeten Bildlayout NCHW und den Formaten NHWC oder NCHWc umfassen. Sie werden mit einem Optimierungsgrad von „all“ aktiviert.
- Für ONNX Runtime-Versionen vor 1.8 sollten Layout-Optimierungen bei der Erstellung von ORT-Formatmodellen nicht verwendet werden.
- Für ONNX Runtime Version 1.8 oder neuer können Layout-Optimierungen aktiviert werden, da die hardwareabhängigen Optimierungen automatisch deaktiviert werden.
Ergebnis von Optimierungen bei der Erstellung eines optimierten ORT-Formatmodells
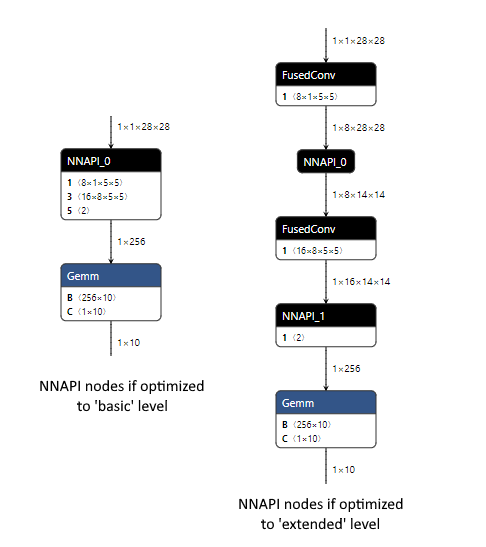
Nachfolgend ein Beispiel für die Änderungen, die bei Basis- und erweiterten Optimierungen auftreten, wenn sie auf das MNIST-Modell mit aktiviertem CPU EP angewendet werden. Der Optimierungsgrad wird bei der Erstellung des ORT-Formatmodells angegeben.
- Auf Basisebene kombinieren wir die Knoten Conv und Add (die Addition erfolgt über den „B“-Eingang von Conv), wir kombinieren MatMul und Add zu einem einzigen Gemm-Knoten (die Addition erfolgt über den „C“-Eingang von Gemm) und führen Constant Folding durch, um einen der Reshape-Knoten zu entfernen.
python <ORT-Repository-Stammverzeichnis>/tools/python/convert_onnx_models_to_ort.py --optimization_level basic /dir_with_mnist_onnx_model
- Auf erweiterter Ebene fusionieren wir zusätzlich die Conv- und Relu-Knoten mithilfe des internen ONNX Runtime FusedConv-Operators.
python <ORT-Repository-Stammverzeichnis>/tools/python/convert_onnx_models_to_ort.py --optimization_level extended /dir_with_mnist_onnx_model

Ergebnis der Ausführung eines optimierten ORT-Formatmodells mit dem NNAPI EP
Wenn der NNAPI EP zur Laufzeit registriert ist, erhält er die Möglichkeit, die Knoten im geladenen Modell auszuwählen, die er ausführen kann. Dabei gruppiert er so viele Knoten wie möglich zusammen, um den Overhead für das Kopieren von Daten zwischen CPU und NNAPI zur Ausführung der Knoten zu minimieren. Jede Knotengruppe kann als Subgraph betrachtet werden. Je mehr Knoten in jedem Subgraph und je weniger Subgraphen, desto besser wird die Leistung sein.
Für jeden Subgraph erstellt der NNAPI EP ein NNAPI-Modell, das die Verarbeitung der ursprünglichen Knoten repliziert. Es wird eine Funktion erstellt, die dieses NNAPI-Modell ausführt und alle erforderlichen Datenkopien zwischen CPU und NNAPI durchführt. ONNX Runtime ersetzt die ursprünglichen Knoten im geladenen Modell durch einen einzigen Knoten, der diese Funktion aufruft.
Wenn der NNAPI EP nicht registriert ist oder einen Knoten nicht verarbeiten kann, wird der Knoten mit dem CPU EP ausgeführt.
Nachfolgend ein Beispiel für das MNIST-Modell, das vergleicht, was zur Laufzeit mit den ORT-Formatmodellen passiert, wenn der NNAPI EP registriert ist.
Da die Basis-Optimierungen zu einem Modell führen, das nur ONNX-Operatoren verwendet, kann der NNAPI EP den Großteil des Modells verarbeiten, da NNAPI die Conv-, Relu- und MaxPool-Knoten ausführen kann. Dies geschieht mit einem einzigen NNAPI-Modell, da alle von NNAPI zu handhabenden Knoten miteinander verbunden sind. Wir erwarten Leistungsgewinne durch die Verwendung von NNAPI mit diesem Modell, da der Overhead der Geräte-Kopien zwischen CPU und NNAPI für einen einzelnen NNAPI-Knoten wahrscheinlich von der Zeit übertroffen wird, die durch die gleichzeitige Ausführung mehrerer Operationen mit NNAPI eingespart wird.
Die erweiterten Optimierungen führen die benutzerdefinierten FusedConv-Knoten ein, die der NNAPI EP ignoriert, da er nur Knoten mit ONNX-Operatoren akzeptiert, die NNAPI verarbeiten kann. Dies führt zu zwei Knoten, die NNAPI verwenden, von denen jeder eine einzelne MaxPool-Operation verarbeitet. Die Leistung dieses Modells wird wahrscheinlich beeinträchtigt, da der Overhead der Geräte-Kopien zwischen CPU und NNAPI (die vor und nach jedem der beiden NNAPI-Knoten erforderlich sind) wahrscheinlich nicht durch die Zeit aufgewogen wird, die durch die wiederholte Ausführung einer einzelnen MaxPool-Operation mit NNAPI eingespart wird. Eine bessere Leistung kann erzielt werden, indem der NNAPI EP nicht registriert wird, sodass alle Knoten im Modell mit dem CPU EP ausgeführt werden.
2. Initiale Leistungstests
Die besten Optimierungseinstellungen sind modellabhängig. Einige Modelle funktionieren mit NNAPI besser, andere nicht. Da die Leistung modellabhängig ist, müssen Sie Leistungstests durchführen, um die beste Kombination für Ihr Modell zu ermitteln.
Es wird empfohlen, Leistungstests durchzuführen
- mit aktiviertem NNAPI und einem mit Basis-Optimierung erstellten ORT-Formatmodell
- mit deaktiviertem NNAPI und einem mit erweiterter oder aller Optimierungsstufe erstellten ORT-Formatmodell
- verwenden Sie all für ONNX Runtime Version 1.8 oder neuer und extended für frühere Versionen
Für die meisten Szenarien wird erwartet, dass einer dieser beiden Ansätze die beste Leistung erzielt.
Wenn ein ORT-Formatmodell mit Basis-Optimierungen und NNAPI eine gleichwertige oder bessere Leistung erzielt, ist es *möglich*, die Leistung weiter zu verbessern, indem ein NNAPI-fähiges ORT-Formatmodell erstellt wird. Der Unterschied bei diesem Modell besteht darin, dass die übergeordneten Optimierungen nur auf Knoten angewendet werden, die nicht mit NNAPI ausgeführt werden können. Ob Knoten in diese Kategorie fallen, ist modellabhängig.
3. Erstellung eines NNAPI-fähigen ORT-Formatmodells
Ein NNAPI-fähiges ORT-Formatmodell behält alle Knoten aus dem ONNX-Modell, die mit NNAPI ausgeführt werden können, und ermöglicht die Anwendung von erweiterten Optimierungen auf verbleibende Knoten.
Für unser MNIST-Modell würde dies bedeuten, dass nach Anwendung der Basis-Optimierungen die Knoten in roter Schattierung unverändert bleiben und auf die Knoten in grüner Schattierung erweiterte Optimierungen angewendet werden könnten.

Um ein NNAPI-fähiges ORT-Formatmodell zu erstellen, befolgen Sie diese Schritte.
-
Erstellen Sie einen „Full“-Build von ONNX Runtime mit dem NNAPI EP, indem Sie ONNX Runtime aus der Quelle erstellen.
Dieser Build kann auf jeder Plattform erfolgen, da der NNAPI EP verwendet werden kann, um das ORT-Formatmodell zu erstellen, ohne die Android NNAPI-Bibliothek zu benötigen, da bei diesem Prozess keine Modellausführung stattfindet. Fügen Sie beim Erstellen die Flags `--use_nnapi --build_shared_lib --build_wheel` hinzu, falls diese fehlen.
Fügen Sie NICHT das Flag `--minimal_build` hinzu.
- Windows
<ONNX Runtime repository root>\build.bat --config RelWithDebInfo --use_nnapi --build_shared_lib --build_wheel --parallel - Linux
<ONNX Runtime repository root>/build.sh --config RelWithDebInfo --use_nnapi --build_shared_lib --build_wheel --parallel
HINWEIS: Für ONNX Runtime Version 1.10 und früher, wenn Sie zuvor einen Minimal-Build mit reduzierten Operator-Kernels durchgeführt haben, müssen Sie
git reset --hardausführen, um sicherzustellen, dass alle Operator-Kernel-Ausschlüsse aufgehoben werden, bevor Sie den „Full“-Build durchführen. Andernfalls können Sie das ONNX-Formatmodell aufgrund fehlender Kernels möglicherweise nicht laden. - Windows
- Installieren Sie das Python-Wheel aus dem Build-Ausgabeverzeichnis.
- Windows: Dies befindet sich unter
build/Windows/<config>/<config>/dist/<package name>.whl. - Linux: Dies befindet sich unter
build/Linux/<config>/dist/<package name>.whl. Der Paketname variiert je nach Plattform, Python-Version und Build-Parametern. `` ist der Wert des `--config`-Parameters aus dem Build-Befehl. pip install -U build\Windows\RelWithDebIfo\RelWithDebIfo\dist\onnxruntime_noopenmp-1.7.0-cp37-cp37m-win_amd64.whl
- Windows: Dies befindet sich unter
- Erstellen Sie ein NNAPI-fähiges ORT-Formatmodell, indem Sie `convert_onnx_models_to_ort.py` gemäß den Standardanweisungen ausführen, mit aktiviertem NNAPI (`--use_nnapi`) und dem auf erweitert oder all gesetzten Optimierungsgrad (z. B. `--optimization_level extended`). Dadurch können übergeordnete Optimierungen auf Knoten angewendet werden, die NNAPI nicht verarbeiten kann.
python <ORT repository root>/tools/python/convert_onnx_models_to_ort.py --use_nnapi --optimization_level extended /modelsDas Python-Paket aus Ihrem „Full“-Build mit aktiviertem NNAPI muss installiert sein, damit `--use_nnapi` eine gültige Option ist.
Das erstellte ORT-Modell kann mit einem Minimal-Build verwendet werden, der den NNAPI EP enthält.