Entwicklung einer mobilen Anwendung mit ONNX Runtime
ONNX Runtime bietet Ihnen verschiedene Optionen, um maschinelles Lernen in Ihre mobile Anwendung zu integrieren. Diese Seite beschreibt den Ablauf des Entwicklungsprozesses. Sie können sich auch die Tutorials in diesem Abschnitt ansehen
- Erstellen einer Objekterkennungsanwendung unter iOS
- Erstellen einer Bildklassifizierungsanwendung unter Android
- Erstellen einer Super-Auflösungsanwendung unter iOS
- Erstellen einer Super-Auflösungsanwendung unter Android
Entwicklungsprozess für mobile ONNX Runtime-Anwendungen
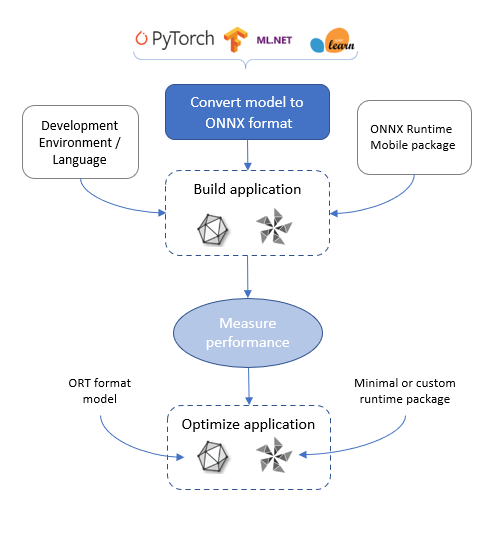
Modell beschaffen
Der erste Schritt bei der Entwicklung Ihrer mobilen Anwendung für maschinelles Lernen ist die Beschaffung eines Modells.
Sie müssen das Szenario Ihrer mobilen App verstehen und ein ONNX-Modell erhalten, das für dieses Szenario geeignet ist. Klassifiziert die App beispielsweise Bilder, führt sie Objekterkennung in einem Videostream durch, fasst sie Text zusammen oder sagt sie Text voraus, oder führt sie numerische Vorhersagen durch.
Um auf ONNX Runtime Mobile ausgeführt zu werden, muss das Modell im ONNX-Format vorliegen. ONNX-Modelle können aus dem ONNX Model Zoo bezogen werden. Wenn Ihr Modell noch nicht im ONNX-Format vorliegt, können Sie es mit einem der Konverter von PyTorch, TensorFlow und anderen Formaten in ONNX konvertieren.
Da das Modell auf dem Gerät geladen und ausgeführt wird, muss es auf dem Speicherplatz des Geräts Platz finden und in den Arbeitsspeicher des Geräts geladen werden können.
Anwendung entwickeln
Sobald Sie ein Modell haben, können Sie es mit der ONNX Runtime-API laden und ausführen.
Welche Sprach-Bindings und Laufzeitpakete Sie verwenden, hängt von Ihrer gewählten Entwicklungsumgebung und den Zielsystemen ab, für die Sie entwickeln.
- Android Java/C/C++: onnxruntime-android-Paket
- iOS C/C++: onnxruntime-c-Paket
- iOS Objective-C: onnxruntime-objc-Paket
- Android und iOS C# in MAUI/Xamarin: Microsoft.ML.OnnxRuntime und Microsoft.ML.OnnxRuntime.Managed
In der Installationsanleitung finden Sie anwendungsspezifische Anweisungen.
Die oben genannten Pakete enthalten alle vollständigen ONNX Runtime-Funktionen und Operatoren sowie Unterstützung für das ONNX-Format. Wir empfehlen Ihnen, mit diesen zu beginnen, um Ihre Anwendung zu entwickeln. Weitere Optimierungen können erforderlich sein. Diese werden unten detailliert beschrieben.
Je nach Zielplattform haben Sie die Wahl zwischen verschiedenen Hardwarebeschleunigern, die Sie in Ihrer App verwenden können.
- Alle Ziele unterstützen die CPU, und dies ist die Standardeinstellung.
- Anwendungen, die unter Android ausgeführt werden, unterstützen auch NNAPI und XNNPACK.
- Anwendungen, die unter iOS ausgeführt werden, unterstützen auch CoreML und XNNPACK.
Beschleuniger werden in ONNX Runtime als "Execution Providers" bezeichnet.
Wenn das Modell quantisiert ist, beginnen Sie mit dem CPU-Ausführungsanbieter. Wenn das Modell nicht quantisiert ist, beginnen Sie mit XNNPACK. Diese sind am einfachsten und konsistentesten, da alles auf der CPU ausgeführt wird.
Wenn CPU/XNNPACK nicht die Leistungsergebnisse der Anwendung erfüllen, versuchen Sie NNAPI/CoreML. Die Leistung mit diesen Ausführungsanbietern ist geräte- und modellspezifisch. Wenn das Modell aufgrund von Operatoren, die der Ausführungsanbieter nicht unterstützt (z. B. aufgrund älterer NNAPI-Versionen), in mehrere Partitionen aufgeteilt wird, kann die Leistung abnehmen.
Spezifische Ausführungsanbieter werden in den `SessionOptions` konfiguriert, wenn die ONNXRuntime-Sitzung erstellt und das Modell geladen wird. Weitere Details finden Sie in der API-Dokumentation Ihrer Sprache.
Leistung der Anwendung messen
Messen Sie die Leistung der Anwendung anhand der Anforderungen Ihrer Zielplattform. Dazu gehören
- Binärgröße der Anwendung
- Modellgröße
- Anwendungs-Latenz
- Energieverbrauch
Wenn die Anwendung die Anforderungen nicht erfüllt, können Optimierungen vorgenommen werden.
Anwendung optimieren
Modellgröße reduzieren
Eine Methode zur Reduzierung der Modellgröße ist die Quantisierung des Modells. Dies reduziert ein ursprüngliches Modell mit 32-Bit-Gewichten um etwa den Faktor 4, da die Gewichte auf 8-Bit reduziert werden. Anweisungen dazu finden Sie in der Quantisierungsanleitung von ONNX Runtime.
Eine weitere Möglichkeit, die Modellgröße zu reduzieren, besteht darin, ein neues Modell mit denselben Ein- und Ausgaben und derselben Architektur zu finden, das bereits für mobile Geräte optimiert wurde. Beispiele hierfür sind MobileNet und MobileBert.
Binärgröße der Anwendung reduzieren
Um die ONNX Runtime-Binärgröße zu reduzieren, können Sie eine benutzerdefinierte Laufzeit basierend auf Ihrem Modell/Ihren Modellen erstellen.
Beziehen Sie sich auf den Prozess zur Erstellung einer benutzerdefinierten Laufzeit.
Eines der Ausgabeergebnisse der ORT-Formatkonvertierung ist eine Build-Konfigurationsdatei, die eine Liste von Operatoren aus Ihrem Modell/Ihren Modellen und deren Typen enthält. Sie können diese Konfigurationsdatei als Eingabe für den Build der benutzerdefinierten Laufzeit-Binärdatei verwenden.
Um einen Eindruck von der Binärgrößendifferenz zwischen dem vorab erstellten Paket und einem benutzerdefinierten Build zu geben
| Datei | Größe des vorab erstellten Pakets (Bytes) 1.18.0 | Größe des benutzerdefinierten Builds (Bytes) 1.18.0 |
|---|---|---|
| AAR | 24415212 | 7532309 |
jni/arm64-v8a/libonnxruntime.so, unkomprimiert | 16276832 | 3962832 |
jni/x86_64/libonnxruntime.so, unkomprimiert | 18222208 | 4240864 |
Dieser benutzerdefinierte Build unterstützt die Operatoren, die zum Ausführen eines ResNet50-Modells erforderlich sind. Er erfordert die Verwendung von ORT-Formatmodellen (da er mit --minimal_build=extended erstellt wurde). Er unterstützt die NNAPI- und XNNPACK-Ausführungsanbieter.