QNN Execution Provider
Der QNN Execution Provider für ONNX Runtime ermöglicht die hardwarebeschleunigte Ausführung auf Qualcomm-Chipsätzen. Er verwendet das Qualcomm AI Engine Direct SDK (QNN SDK), um aus einem ONNX-Modell einen QNN-Graphen zu erstellen, der von einer unterstützten Beschleuniger-Backend-Bibliothek ausgeführt werden kann. Der ONNX Runtime QNN Execution Provider kann auf Android- und Windows-Geräten mit Qualcomm Snapdragon SOCs verwendet werden.
Inhalt
- Voraussetzungen installieren (Nur Build aus Quelle)
- Build (Android und Windows)
- Vorkompilierte Pakete (nur Windows)
- Qualcomm AI Hub
- Konfigurationsoptionen
- Unterstützte ONNX-Operatoren
- Ausführen eines Modells mit dem HTP-Backend von QNN EP (Python)
- QNN-Kontext-Binärcache-Funktion
- QNN EP Gewichtsteilung
- Verwendung
- Fehlerbehandlung
- Hinzufügen neuer Operatorunterstützung in QNN EP
- Unterstützung für gemischte Präzision
- LoRAv2-Unterstützung
Voraussetzungen installieren (Nur Build aus Quelle)
Wenn Sie den QNN Execution Provider aus der Quelle erstellen, sollten Sie zuerst das Qualcomm AI Engine Direct SDK (QNN SDK) von https://qpm.qualcomm.com/#/main/tools/details/Qualcomm_AI_Runtime_SDK herunterladen.
QNN-Versionsanforderungen
Der ONNX Runtime QNN Execution Provider wurde mit QNN 2.22.x und Qualcomm SC8280, SM8350, Snapdragon X SOCs unter Android und Windows erstellt und getestet.
Build (Android und Windows)
Anweisungen zum Erstellen finden Sie auf der BUILD-Seite.
Vorkompilierte Pakete (nur Windows)
Hinweis: Ab Version 1.18.0 müssen Sie das QNN SDK nicht mehr separat herunterladen und installieren. Die erforderlichen QNN-Abhängigkeitsbibliotheken sind in den OnnxRuntime-Paketen enthalten.
- NuGet-Paket
- Das Feed für nächtliche Pakete von Microsoft.ML.OnnxRuntime.QNN finden Sie hier.
- Python-Paket
- Voraussetzungen
- Windows ARM64 (für Inferenz auf lokalen Geräten mit Qualcomm NPU)
- Windows X64 (zum Quantisieren von Modellen. siehe Erstellen eines quantisierten Modells)
- Python 3.11.x
- Numpy 1.25.2 oder >= 1.26.4
- Installieren:
pip install onnxruntime-qnn - Nächtliches Paket installieren
python -m pip install --pre --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ORT-Nightly/pypi/simple onnxruntime-qnn
- Voraussetzungen
Qualcomm AI Hub
Der Qualcomm AI Hub kann zur Optimierung und Ausführung von Modellen auf von Qualcomm gehosteten Geräten verwendet werden. Der ONNX Runtime QNN Execution Provider ist eine unterstützte Laufzeit im Qualcomm AI Hub.
Konfigurationsoptionen
Der QNN Execution Provider unterstützt eine Reihe von Konfigurationsoptionen. Diese Provider-Optionen werden als Schlüssel-Wert-Zeichenkettenpaare angegeben.
EP-Provider-Optionen
"backend_type" | Beschreibung |
|---|---|
| ‘cpu’ | Aktiviert das CPU-Backend. Nützlich für Integrationstests. Das CPU-Backend ist eine Referenzimplementierung von QNN-Operatoren. |
| ‘gpu’ | Aktiviert das GPU-Backend. |
| ‘htp’ | Aktiviert das HTP-Backend. Lagert die Berechnung auf die NPU aus. Standard. |
| ‘saver’ | Aktiviert das Saver-Backend. |
"backend_path" | Beschreibung |
|---|---|
| ‘libQnnCpu.so’ oder ‘QnnCpu.dll’ | Aktiviert das CPU-Backend. Siehe backend_type ‘cpu’. |
| ‘libQnnHtp.so’ oder ‘QnnHtp.dll’ | Aktiviert das HTP-Backend. Siehe backend_type ‘htp’. |
Hinweis: backend_path ist eine Alternative zu backend_type. Höchstens eines der beiden sollte angegeben werden. backend_path erfordert einen plattformspezifischen Pfad (z.B. libQnnCpu.so im Gegensatz zu QnnCpu.dll), erlaubt aber auch die Angabe eines beliebigen Pfades.
"profiling_level" | Beschreibung |
|---|---|
| ‘off’ | Standard. |
| ‘basic’ | |
| ‘detailed’ |
"profiling_file_path" | Beschreibung |
|---|---|
| ‘your_qnn_profile_path.csv’ | Gibt den Pfad zur CSV-Datei an, in die die QNN-Profiling-Ereignisse geschrieben werden sollen. |
Weitere Informationen zum Profiling finden Sie unter Profiling-Tools.
Alternativ zur Festlegung des Profiling-Levels zur Kompilierzeit kann das Profiling dynamisch mit ETW (Windows) aktiviert werden. Weitere Details finden Sie unter Tracing.
"rpc_control_latency" | Beschreibung |
|---|---|
| Mikrosekunden (Zeichenkette) | Ermöglicht dem Client, die RPC-Steuerlatenz in Mikrosekunden festzulegen. |
"vtcm_mb" | Beschreibung |
|---|---|
| Größe in MB (Zeichenkette) | QNN VTCM-Größe in MB, Standard ist 0 (nicht gesetzt). |
"htp_performance_mode" | Beschreibung |
|---|---|
| ‘burst’ | |
| ‘balanced’ | |
| ‘default’ | Standard. |
| ‘high_performance’ | |
| ‘high_power_saver’ | |
| ‘low_balanced’ | |
| ‘low_power_saver’ | |
| ‘power_saver’ | |
| ‘sustained_high_performance’ |
"qnn_saver_path" | Beschreibung |
|---|---|
| Pfad zu ‘QnnSaver.dll’ oder ‘libQnnSaver.so’ | Pfad zur QNN Saver-Backend-Bibliothek. Schreibt QNN-API-Aufrufe zur Wiederholung/Fehlerbehebung auf die Festplatte. |
"qnn_context_priority" | Beschreibung |
|---|---|
| ‘low’ | |
| ‘normal’ | Standard. |
| ‘normal_high’ | |
| ‘high’ |
"htp_graph_finalization_optimization_mode" | Beschreibung |
|---|---|
| ‘0’ | Standard. |
| ‘1’ | Schnellere Vorbereitungszeit, weniger optimaler Graph. |
| ‘2’ | Längere Vorbereitungszeit, wahrscheinlich noch optimalerer Graph. |
| ‘3’ | Längste Vorbereitungszeit, höchstwahrscheinlich noch optimalerer Graph. |
"soc_model" | Beschreibung |
|---|---|
| Modellnummer (Zeichenkette) | Die SoC-Modellnummer. Gültige Werte finden Sie in der QNN SDK-Dokumentation. Standard ist „0“ (unbekannt). |
"htp_arch" | Beschreibung |
|---|---|
| Hardware-Architektur | HTP-Architektur-Nummer. Gültige Werte finden Sie in der QNN SDK-Dokumentation. Standard (keine) |
"device_id" | Beschreibung |
|---|---|
| Geräte-ID (Zeichenkette) | Die ID des Geräts, das bei der Einstellung von htp_arch verwendet werden soll. Standard ist „0“ (für ein einzelnes Gerät). |
"enable_htp_fp16_precision" | Beschreibung Beispiel |
|---|---|
| ‘0’ | Deaktiviert. Inferenziert mit fp32-Präzision, wenn es sich um ein fp32-Modell handelt. |
| ‘1’ | Standard. Aktiviert die Inferenz eines Float32-Modells mit fp16-Präzision. |
"offload_graph_io_quantization" | Beschreibung |
|---|---|
| ‘0’ | Deaktiviert. QNN EP übernimmt die Quantisierung und Dequantisierung von Graph-E/A. |
| ‘1’ | Standard. Aktiviert. Lagert die Quantisierung und Dequantisierung von Graph-E/A auf CPU EP aus. |
"enable_htp_shared_memory_allocator" | Beschreibung |
|---|---|
| ‘0’ | Standard. Deaktiviert. |
| ‘1’ | Aktiviert den QNN HTP Shared Memory Allocator. Erfordert die Verfügbarkeit von libcdsprpc.so/dll. Codebeispiel |
Ausführungsoptionen
"qnn.lora_config" | Beschreibung |
|---|---|
| Konfigurationspfad | Pfad zur LoRAv2-Konfigurationsdatei. Das Format der Konfiguration wird in der Beschreibung von LoRAv2-Unterstützung erläutert. |
Unterstützte ONNX-Operatoren
| Operator | Hinweise |
|---|---|
| ai.onnx:Abs | |
| ai.onnx:Add | |
| ai.onnx:And | |
| ai.onnx:ArgMax | |
| ai.onnx:ArgMin | |
| ai.onnx:Asin | |
| ai.onnx:Atan | |
| ai.onnx:AveragePool | |
| ai.onnx:BatchNormalization | fp16 unterstützt seit 1.18.0 |
| ai.onnx:Cast | |
| ai.onnx:Clip | fp16 unterstützt seit 1.18.0 |
| ai.onnx:Concat | |
| ai.onnx:Conv | 3D unterstützt seit 1.18.0 |
| ai.onnx:ConvTranspose | 3D unterstützt seit 1.18.0 |
| ai.onnx:Cos | |
| ai.onnx:DepthToSpace | |
| ai.onnx:DequantizeLinear | |
| ai.onnx:Div | |
| ai.onnx:Elu | |
| ai.onnx:Equal | |
| ai.onnx:Exp | |
| ai.onnx:Expand | |
| ai.onnx:Flatten | |
| ai.onnx:Floor | |
| ai.onnx:Gather | Unterstützt nur positive Indizes |
| ai.onnx:Gelu | |
| ai.onnx:Gemm | |
| ai.onnx:GlobalAveragePool | |
| ai.onnx:Greater | |
| ai.onnx:GreaterOrEqual | |
| ai.onnx:GridSample | |
| ai.onnx:HardSwish | |
| ai.onnx:InstanceNormalization | |
| ai.onnx:LRN | |
| ai.onnx:LayerNormalization | |
| ai.onnx:LeakyRelu | |
| ai.onnx:Less | |
| ai.onnx:LessOrEqual | |
| ai.onnx:Log | |
| ai.onnx:LogSoftmax | |
| ai.onnx:LpNormalization | p == 2 |
| ai.onnx:MatMul | Unterstützte Eingabedatentypen im HTP-Backend: (uint8, uint8), (uint8, uint16), (uint16, uint8) |
| ai.onnx:Max | |
| ai.onnx:MaxPool | |
| ai.onnx:Min | |
| ai.onnx:Mul | |
| ai.onnx:Neg | |
| ai.onnx:Not | |
| ai.onnx:Or | |
| ai.onnx:Prelu | fp16, int32 unterstützt seit 1.18.0 |
| ai.onnx:Pad | |
| ai.onnx:Pow | |
| ai.onnx:QuantizeLinear | |
| ai.onnx:ReduceMax | |
| ai.onnx:ReduceMean | |
| ai.onnx:ReduceMin | |
| ai.onnx:ReduceProd | |
| ai.onnx:ReduceSum | |
| ai.onnx:Relu | |
| ai.onnx:Resize | |
| ai.onnx:Round | |
| ai.onnx:Sigmoid | |
| ai.onnx:Sign | |
| ai.onnx:Sin | |
| ai.onnx:Slice | |
| ai.onnx:Softmax | |
| ai.onnx:SpaceToDepth | |
| ai.onnx:Split | |
| ai.onnx:Sqrt | |
| ai.onnx:Squeeze | |
| ai.onnx:Sub | |
| ai.onnx:Tanh | |
| ai.onnx:Tile | |
| ai.onnx:TopK | |
| ai.onnx:Transpose | |
| ai.onnx:Unsqueeze | |
| ai.onnx:Where | |
| com.microsoft:DequantizeLinear | Bietet Unterstützung für die Dequantisierung von 16-Bit-Ganzzahlen. |
| com.microsoft:Gelu | |
| com.microsoft:QuantizeLinear | Bietet Unterstützung für die Quantisierung von 16-Bit-Ganzzahlen. |
Die unterstützten Datentypen variieren je nach Operator und QNN-Backend. Weitere Informationen finden Sie in der QNN SDK-Dokumentation.
Ausführen eines Modells mit dem HTP-Backend von QNN EP (Python)
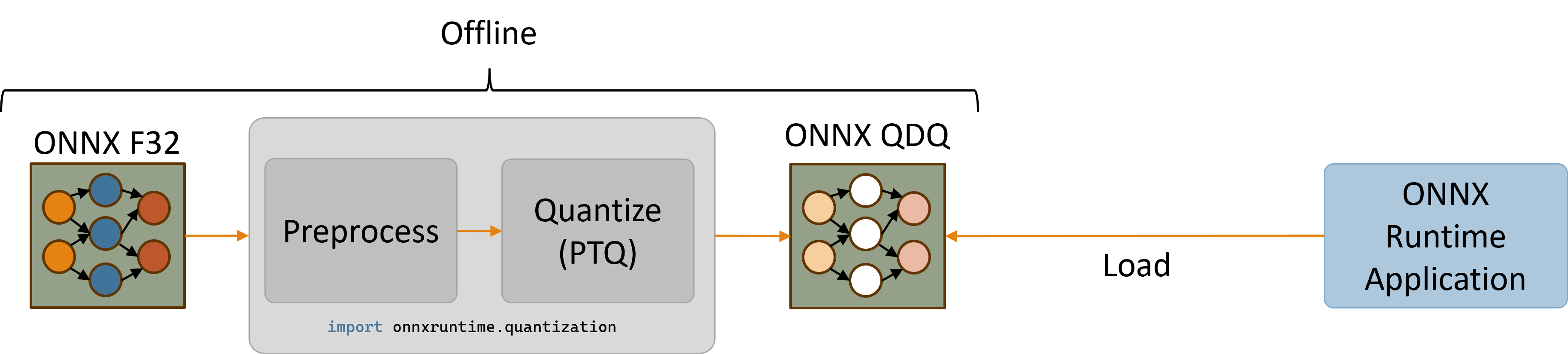
Das QNN HTP-Backend unterstützt nur quantisierte Modelle. Modelle mit 32-Bit-Gleitkomma-Aktivierungen und Gewichten müssen zuerst auf eine niedrigere Ganzzahlpräzision (z.B. 8-Bit- oder 16-Bit-Ganzzahlen) quantisiert werden.
Dieser Abschnitt enthält Anleitungen zum Quantisieren eines Modells und anschließenden Ausführen des quantisierten Modells auf dem HTP-Backend von QNN EP mithilfe von Python-APIs. Eine breitere Übersicht über Quantisierungskonzepte finden Sie auf der Quantierungsseite.
Modell-Anforderungen
QNN EP unterstützt keine Modelle mit dynamischen Formen (z.B. eine dynamische Batch-Größe). Dynamische Formen müssen auf einen bestimmten Wert fixiert werden. Weitere Informationen zum Fixieren dynamischer Eingabeformen finden Sie in der Dokumentation.
Zusätzlich unterstützt QNN EP eine Teilmenge von ONNX-Operatoren (z.B. Schleifen und Wenn-Anweisungen werden nicht unterstützt). Eine Liste der unterstützten ONNX-Operatoren finden Sie hier.
Erstellen eines quantisierten Modells (nur x64)
Das ONNX Runtime Python-Paket bietet Dienstprogramme zum Quantisieren von ONNX-Modellen über den Import onnxruntime.quantization. Die Quantisierungsdienstprogramme werden derzeit nur unter x86_64 unterstützt, da es Probleme beim Installieren des onnx-Pakets unter ARM64 gibt. Daher wird empfohlen, entweder eine x64-Maschine zum Quantisieren von Modellen zu verwenden oder alternativ eine separate x64-Python-Installation auf Windows ARM64-Maschinen zu verwenden.
Installieren Sie das ONNX Runtime x64 Python-Paket. (Bitte beachten Sie, dass Sie das x64-Paket zum Quantisieren des Modells verwenden müssen. Verwenden Sie das Arm64-Paket für die Inferenz und die Nutzung von HTP/NPU).
python -m pip install onnxruntime-qnn
Die Quantisierung für QNN EP erfordert die Verwendung von Kalibrierungs-Eingabedaten. Die Verwendung eines repräsentativen Kalibrierungsdatensatzes für typische Modelleingaben ist entscheidend für die Erzeugung eines genauen quantisierten Modells.
Der folgende Ausschnitt definiert eine Beispielklasse DataReader, die zufällige Float32-Eingabedaten generiert. Beachten Sie, dass die Verwendung von zufälligen Eingabedaten höchstwahrscheinlich zu einem ungenauen quantisierten Modell führt. Eine Implementierung eines Resnet-Datenlesers finden Sie im Beispiel für die Erstellung eines CalibrationDataReader, der Eingaben von Bilddateien auf der Festplatte liefert.
# data_reader.py
import numpy as np
import onnxruntime
from onnxruntime.quantization import CalibrationDataReader
class DataReader(CalibrationDataReader):
def __init__(self, model_path: str):
self.enum_data = None
# Use inference session to get input shape.
session = onnxruntime.InferenceSession(model_path, providers=['CPUExecutionProvider'])
inputs = session.get_inputs()
self.data_list = []
# Generate 10 random float32 inputs
# TODO: Load valid calibration input data for your model
for _ in range(10):
input_data = {inp.name : np.random.random(inp.shape).astype(np.float32) for inp in inputs}
self.data_list.append(input_data)
self.datasize = len(self.data_list)
def get_next(self):
if self.enum_data is None:
self.enum_data = iter(
self.data_list
)
return next(self.enum_data, None)
def rewind(self):
self.enum_data = None
Der folgende Ausschnitt vorverarbeitet das ursprüngliche Modell und quantisiert dann das vorverarbeitete Modell zur Verwendung von uint16-Aktivierungen und uint8-Gewichten. Obwohl die Quantisierungsdienstprogramme die Quantisierungsdatentypen uint8, int8, uint16 und int16 bereitstellen, unterstützen QNN-Operatoren typischerweise die Datentypen uint8 und uint16. Informationen zu den Datentypanforderungen jedes QNN-Operators finden Sie in der QNN SDK-Operator-Dokumentation.
# quantize_model.py
import data_reader
import numpy as np
import onnx
from onnxruntime.quantization import QuantType, quantize
from onnxruntime.quantization.execution_providers.qnn import get_qnn_qdq_config, qnn_preprocess_model
if __name__ == "__main__":
input_model_path = "model.onnx" # TODO: Replace with your actual model
output_model_path = "model.qdq.onnx" # Name of final quantized model
my_data_reader = data_reader.DataReader(input_model_path)
# Pre-process the original float32 model.
preproc_model_path = "model.preproc.onnx"
model_changed = qnn_preprocess_model(input_model_path, preproc_model_path)
model_to_quantize = preproc_model_path if model_changed else input_model_path
# Generate a suitable quantization configuration for this model.
# Note that we're choosing to use uint16 activations and uint8 weights.
qnn_config = get_qnn_qdq_config(model_to_quantize,
my_data_reader,
activation_type=QuantType.QUInt16, # uint16 activations
weight_type=QuantType.QUInt8) # uint8 weights
# Quantize the model.
quantize(model_to_quantize, output_model_path, qnn_config)
Das Ausführen von python quantize_model.py generiert ein quantisiertes Modell namens model.qdq.onnx, das unter Windows ARM64-Geräten über den QNN EP von ONNX Runtime ausgeführt werden kann.
Weitere Informationen zur Verwendung der Quantisierungsdienstprogramme finden Sie auf den folgenden Seiten.
- Quantisierungsbeispiel für Mobilenet auf dem CPU EP
- quantization/execution_providers/qnn/preprocess.py
- quantization/execution_providers/qnn/quant_config.py
Ausführen eines quantisierten Modells unter Windows ARM64 (onnxruntime-qnn Version >= 1.18.0)
Installieren Sie das ONNX Runtime ARM64 Python-Paket für QNN EP (erfordert Python 3.11.x und Numpy 1.25.2 oder >= 1.26.4).
python -m pip install onnxruntime-qnn
Der folgende Python-Ausschnitt erstellt eine ONNX Runtime-Sitzung mit QNN EP und führt das quantisierte Modell model.qdq.onnx auf dem HTP-Backend aus.
# run_qdq_model.py
import onnxruntime
import numpy as np
options = onnxruntime.SessionOptions()
# (Optional) Enable configuration that raises an exception if the model can't be
# run entirely on the QNN HTP backend.
options.add_session_config_entry("session.disable_cpu_ep_fallback", "1")
# Create an ONNX Runtime session.
# TODO: Provide the path to your ONNX model
session = onnxruntime.InferenceSession("model.qdq.onnx",
sess_options=options,
providers=["QNNExecutionProvider"],
provider_options=[{"backend_path": "QnnHtp.dll"}]) # Provide path to Htp dll in QNN SDK
# Run the model with your input.
# TODO: Use numpy to load your actual input from a file or generate random input.
input0 = np.ones((1,3,224,224), dtype=np.float32)
result = session.run(None, {"input": input0})
# Print output.
print(result)
Das Ausführen von python run_qdq_model.py führt das quantisierte Modell model.qdq.onnx auf dem QNN HTP-Backend aus.
Beachten Sie, dass die Sitzung optional so konfiguriert wurde, dass eine Ausnahme ausgelöst wird, wenn das gesamte Modell nicht auf dem QNN HTP-Backend ausgeführt werden kann. Dies ist nützlich, um zu überprüfen, ob das quantisierte Modell vollständig von QNN EP unterstützt wird. Verfügbare Sitzungskonfigurationen umfassen:
- session.disable_cpu_ep_fallback: Deaktiviert das Zurückfallen nicht unterstützter Operatoren auf das CPU EP.
- ep.context_enable: QNN-Kontext-Cache aktivieren-Funktion zum Ausgeben einer zwischengespeicherten Version des Modells, um die Sitzungserstellungszeit zu verkürzen.
Der obige Ausschnitt gibt nur die Provider-Option backend_path an. Eine Liste aller verfügbaren QNN EP-Provider-Optionen finden Sie im Abschnitt Konfigurationsoptionen.
QNN-Kontext-Binärcache-Funktion
Es gibt einen QNN-Kontext, der QNN-Graphen nach der Konvertierung, Kompilierung und Finalisierung des Modells enthält. QNN kann den Kontext in eine Binärdatei serialisieren, sodass Benutzer ihn für weitere Inferenz direkt (ohne das QDQ-Modell) verwenden können, um die Ladekosten des Modells zu verbessern. Der QNN Execution Provider unterstützt eine Reihe von Sitzungsoptionen zur Konfiguration.
QNN-Kontext-Binärdatei ausgeben
- Erstellen Sie eine Sitzungsoption, setzen Sie „ep.context_enable“ auf „1“, um die Ausgabe des QNN-Kontexts zu aktivieren. Der Schlüssel „ep.context_enable“ ist als kOrtSessionOptionEpContextEnable in onnxruntime_session_options_config_keys.h definiert.
- Erstellen Sie die Sitzung mit dem QDQ-Modell unter Verwendung der in Schritt 1 erstellten Sitzungsoptionen und verwenden Sie das HTP-Backend. Ein ONNX-Modell mit QNN-Kontext-Binärdatei wird nach der Erstellung/Initialisierung der Sitzung erstellt. Die Sitzung muss nicht ausgeführt werden. Die Erstellung der QNN-Kontext-Binärdatei kann auf dem Qualcomm-Gerät mit HTP mit einem Arm64-Build erfolgen. Sie kann auch auf einer x64-Maschine mit einem x64-Build erfolgen (kann nicht ausgeführt werden, da kein HTP-Gerät vorhanden ist).
Das generierte ONNX-Modell mit QNN-Kontext-Binärdatei kann für die Produktion/das reale Gerät zur Ausführung von Inferenz bereitgestellt werden. Dieses ONNX-Modell wird vom QNN Execution Provider als normales Modell behandelt. Der Inferenzcode bleibt derselbe wie bei der Inferenz mit QDQ-Modellen auf dem HTP-Backend.
#include "onnxruntime_session_options_config_keys.h"
// C++
Ort::SessionOptions so;
so.AddConfigEntry(kOrtSessionOptionEpContextEnable, "1");
// C
const OrtApi* g_ort = OrtGetApiBase()->GetApi(ORT_API_VERSION);
OrtSessionOptions* session_options;
CheckStatus(g_ort, g_ort->CreateSessionOptions(&session_options));
g_ort->AddSessionConfigEntry(session_options, kOrtSessionOptionEpContextEnable, "1");
# Python
import onnxruntime
options = onnxruntime.SessionOptions()
options.add_session_config_entry("ep.context_enable", "1")
Konfigurieren des Pfads zur Kontext-Binärdatei
Das generierte ONNX-Modell mit QNN-Kontext-Binärdatei wird standardmäßig als [input_QDQ_model_name]_ctx.onnx benannt, falls der Benutzer keinen Pfad angibt. Der Benutzer kann den Pfad in der Sitzungsoption mit dem Schlüssel „ep.context_file_path“ festlegen. Beispielcode siehe unten.
// C++
so.AddConfigEntry(kOrtSessionOptionEpContextFilePath, "./model_a_ctx.onnx");
// C
g_ort->AddSessionConfigEntry(session_options, kOrtSessionOptionEpContextFilePath, "./model_a_ctx.onnx");
# Python
options.add_session_config_entry("ep.context_file_path", "./model_a_ctx.onnx")
Aktivieren des Embed-Modus
Der Inhalt der QNN-Kontext-Binärdatei ist standardmäßig nicht im generierten ONNX-Modell eingebettet. Eine Binärdatei wird separat generiert. Der Dateiname sieht aus wie [input_model_file_name]QNN[hash_id].bin. Der Name wird von Ort bereitgestellt und im generierten ONNX-Modell verfolgt. Dies führt zu Problemen, wenn Änderungen an der Binärdatei vorgenommen werden. Diese Binärdatei muss zusammen mit der generierten ONNX-Datei platziert werden. Der Benutzer kann sie aktivieren, indem er „ep.context_embed_mode“ auf „1“ setzt. In diesem Fall wird der Inhalt der Kontext-Binärdatei in das ONNX-Modell eingebettet.
// C++
so.AddConfigEntry(kOrtSessionOptionEpContextEmbedMode, "1");
// C
g_ort->AddSessionConfigEntry(session_options, kOrtSessionOptionEpContextEmbedMode, "1");
# Python
options.add_session_config_entry("ep.context_embed_mode", "1")
QNN EP Gewichtsteilung
Bezieht sich auf das EPContext-Design-Dokument.
Hinweis: QNN EP erfordert die Plattform Linux x86_64 oder Windows x86_64.
Zusätzlich, wenn der Benutzer die QNN-Kontext-Binärdatei (qnn_ctx.bin) mit Gewichtsteilung mithilfe der QNN-Toolchain (qnn-context-binary-generator) erstellt, kann er ein Skript verwenden, um das Wrapper-ONNX-Modell aus dem Kontext zu generieren: gen_qnn_ctx_onnx_model.py. Das Skript erstellt mehrere model_x_ctx.onnx-Dateien, die jeweils einen EPContext-Knoten enthalten, der auf die freigegebene qnn_ctx.bin-Datei verweist. Jeder EPContext-Knoten gibt einen eindeutigen Knotennamen an, der auf verschiedene QNN-Graphen aus dem QNN-Kontext verweist.
Verwendung
C++
Details zur C-API finden Sie hier.
Ort::Env env = Ort::Env{ORT_LOGGING_LEVEL_ERROR, "Default"};
std::unordered_map<std::string, std::string> qnn_options;
qnn_options["backend_path"] = "QnnHtp.dll";
Ort::SessionOptions session_options;
session_options.AppendExecutionProvider("QNN", qnn_options);
Ort::Session session(env, model_path, session_options);
Python
import onnxruntime as ort
# Create a session with QNN EP using HTP (NPU) backend.
sess = ort.InferenceSession(model_path, providers=['QNNExecutionProvider'], provider_options=[{'backend_path':'QnnHtp.dll'}])`
Inferenzbeispiel
Fehlerbehandlung
HTP SubSystem Restart - SSR
QNN EP gibt bei QNN HTP SSR-Problemen den StatusCode::ENGINE_ERROR zurück. Das übergeordnete Framework/die Anwendung sollte die Onnxruntime-Sitzung neu erstellen, wenn dieser Fehler während der Sitzungsausführung erkannt wird.
Hinzufügen neuer Operatorunterstützung in QNN EP
Um die Unterstützung neuer Operatoren in EP zu ermöglichen, sind folgende Bereiche zu berücksichtigen:
- Unterstützt das QDQ-Skript diesen Operator? Codebeispiel
- Unterstützt die QDQ-Knoteneinheit von ONNX Runtime diesen Operator? Codebeispiel
- Ist es ein Layout-sensitiver Operator?
- Registriert im LayoutTransformer? Codebeispiel
- NHWC-Op-Schema registriert? Beispiel-Fehlermeldung
::operator ()] Modell face_det_qdq konnte nicht geladen werden:Fatal error: com.ms.internal.nhwc:BatchNormalization(9) is not a registered function/op [Beispiel-PR](https://github.com/microsoft/onnxruntime/pull/15278)
Beispiel-PRs zur Aktivierung neuer Operatoren
-
Nicht-Layout-sensitiver Operator. Hardsigmoid für QNN EP unter Verwendung von SDK-Unterstützung direkt aktivieren
-
Layout-sensitiver Operator. InstanceNormalization-Operator zu QNN EP hinzufügen
Unterstützung für gemischte Präzision
Die folgende Abbildung zeigt ein Beispiel für ein Modell mit gemischter Präzision.
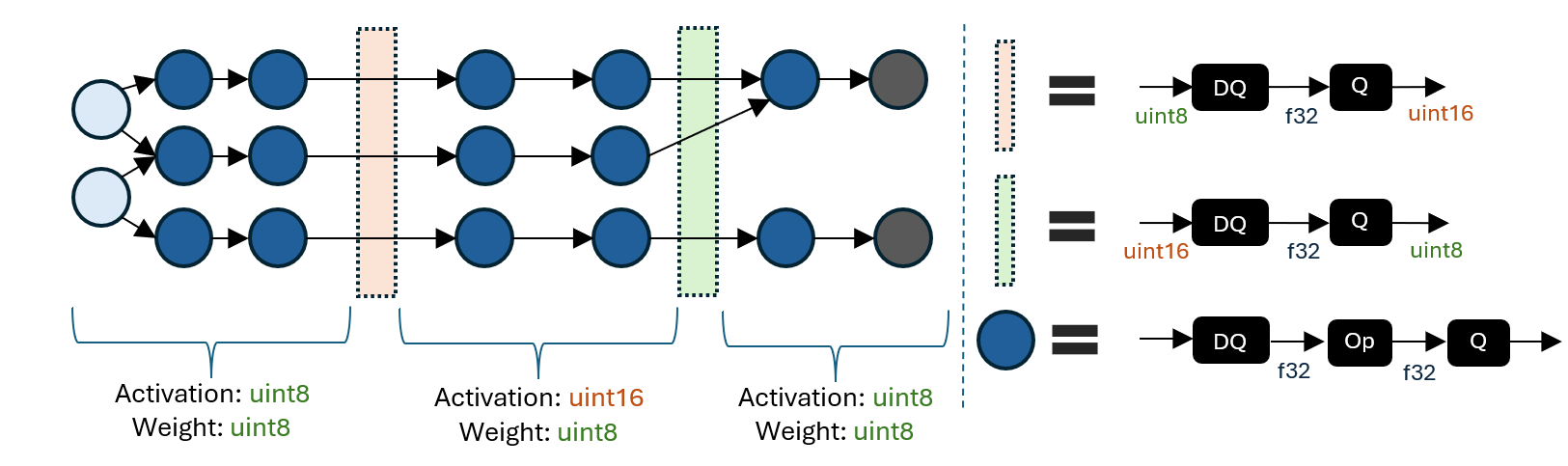
Ein QDQ-Modell mit gemischter Präzision besteht aus Regionen mit unterschiedlichen Aktivierungs-/Gewichts-Quantisierungsdatentypen. Die Grenze zwischen den Regionen wandelt zwischen Aktivierungsquantisierungsdatentypen (z.B. uint8 zu uint16) mithilfe einer DQ-zu-Q-Sequenz um.
Die Möglichkeit, Regionen mit unterschiedlichen Quantisierungsdatentypen anzugeben, ermöglicht die Untersuchung der Kompromisse zwischen Genauigkeit und Latenz. Eine höhere Ganzzahlpräzision kann die Genauigkeit auf Kosten der Latenz verbessern. Das selektive Hochstufen bestimmter Regionen auf eine höhere Präzision kann daher dazu beitragen, ein wünschenswertes Gleichgewicht bei wichtigen Metriken zu erzielen.
Die folgende Abbildung zeigt ein Modell mit einer Region, die von der standardmäßigen 8-Bit-Aktivierung auf 16-Bit hochgestuft wurde.
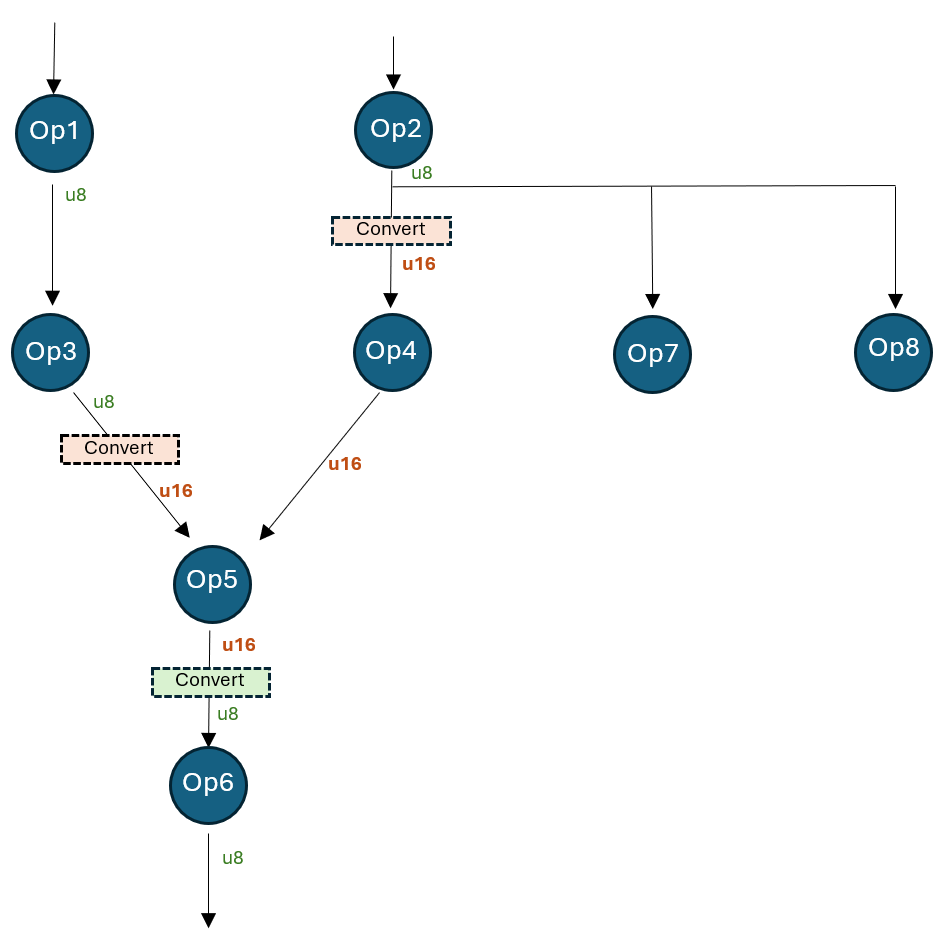
Dieses Modell wird auf uint8-Präzision quantisiert, aber der Tensor „Op4_out“ wird auf 16-Bit quantisiert. Dies kann durch Angabe der folgenden initialen Tensor-Quantisierungs-Overrides erreicht werden.
# Op4_out could be an inaccurate tensor that should be upgraded to 16bit
initial_overrides = {"Op4_out": [{"quant_type": QuantType.QUInt16}]}
qnn_config = get_qnn_qdq_config(
float_model_path,
data_reader,
activation_type=QuantType.QUInt8,
weight_type=QuantType.QUInt8,
init_overrides=initial_overrides, # These initial overrides will be "fixed"
)
Der obige Ausschnitt generiert die folgenden „festen“ Overrides (erhältlich über qnn_config.extra_options[„TensorQuantOverrides“]).
overrides = {
“Op2_out”: [{“quant_type”: QUInt8, “convert”: {“quant_type”: QUInt16, “recv_nodes”: {“Op4”}}}],
“Op3_out”: [{“quant_type”: QUInt8, “convert”: {“quant_type”: QUInt16, “recv_nodes”: {“Op5”}}}],
“Op4_out”: [{“quant_type”: QUInt16}],
“Op5_out”: [{“quant_type”: QUInt16, “convert”: {“quant_type”: QUInt8, “recv_nodes”: {“Op6”}}}]
}
Nach dem Override funktioniert das Modell wie folgt:
- Die Ausgabe von Op2 wird von Op4, Op7 und Op8 verwendet. Op4 verwendet den konvertierten u16-Typ, während Op7 und Op8 den ursprünglichen u8-Typ verwenden.
- Die Ausgabe von Op3 wird von u8 nach u16 konvertiert. Op5 verwendet den konvertierten u16-Typ.
- Die Ausgabe von Op4 ist nur u16 (nicht konvertiert).
- Die Ausgabe von Op5 wird von u16 nach u8 konvertiert. Op6 verwendet den u8-Typ.
LoRAv2-Unterstützung
Derzeit werden nur vorkompilierte Modelle mit EPContext-Knoten unterstützt. Das Beispielskript zur Referenz ist gen_qnn_ctx_onnx_model.py. Nach dem Anwenden des LoRAv2-Modells mit dem QNN SDK werden ein Haupt-QNN-Kontext-Binärdatei und mehrere Adapter-Binärabschnitte generiert. Wir verwenden die LoRAv2-Konfiguration und fügen sie in die RunOptions für die Inferenz ein.
- Das Format der LoRAv2-Konfiguration.
- Graph-Name: QNN-Graph in der QNN-vorkompilierten Kontext-Binärdatei.
- Pfad zum Adapter-Binärabschnitt: Binärabschnitt, der von qnn-context-binary-generator generiert wurde.